Stereo R-CNN based 3D Object Detection for Autonomous Driving
摘要
本文提出了一种充分利用立体图像中稀疏、密集、语义和几何信息的自主驾驶三维目标检测方法,称为Stereo R-CNN,扩展了Faster R-CNN的立体输入,以同时检测和关联目标的左右图像。
在立体区域建议网络(RPN)之后添加额外的分支来预测稀疏的关键点、视点和目标维数,并结合二维左右框来计算粗略的三维目标边界框。然后,我们恢复准确的三维框,以区域为基础的光度比对使用左和右ROI,得到精准的深度。
简介
本文的主要贡献如下:
- 一种立体R-CNN方法,可以同时检测和关联立体图像中的目标
- 利用关键点和立体框约束的3D框估计器
- 基于密集区域的光度校准方法,确保我们的三维目标定位精度
- 对KITTI数据集的评估表明,我们的性能优于所有基于最新图像的方法,甚至可以与基于lidar的方法相媲美
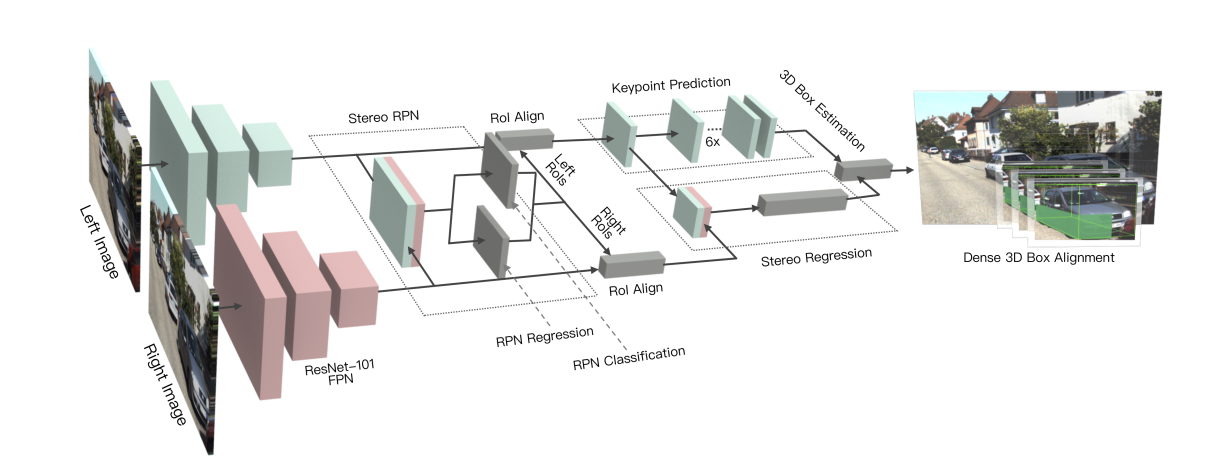
Stereo R-CNN Network
使用weight-share ResNet-101和FPN作为骨干网络,提取左右图像的一致特征。
Stereo RPN
在传统 RPN 网络的基础上,本文先对左右图做 paramid features 提取,然后将不同尺度的特征 concatenate 一起,进入 RPN 网络。
此部分主要是匹配左右两个相机的图像。
RPN Classification目的是找出合适的anchor,使得此anchor能尽可能覆盖左右两个box的并集。
RPN Regression来进一步优化此anchor的坐标。
RPN Classification

真值框定义为左右目真值框的外接合并(union GT box),一个 anchor 在与真值框的交并比(Intersection-over-Union)大于 0.7 时标记为正样本,小于 0.3 时标记为负样本。分类任务的候选框包含了左右目真值框区域的信息。
RPN Regression
真值框定义为左右目分别的真值框。待回归的参数定义为\([u, w, u', w', v, h]\),分别为:
- 左目的水平位置
- 左目的宽
- 右目的水平位置
- 右目的宽
- 垂直位置
- 高
因为左右目相机是水平安放的两个镜头,所以左右目图像共享一个高以及的垂直位置。
每个左右目的 proposal 都是通过同一个 anchor 产生的,自然左右目的 proposal 是关联的。通过 NMS 后,保留左右目都还存在的 proposal 关联对,取前 2000 个用于训练,测试时取前 300 个。
Stereo R-CNN
Stereo Regression
- 分别在左右目的 feature map上进行 RoI Align 的操作;
- 进行concatenate操作;
- 输入到2层全连接层(激活函数为Relu);
输出结果:
- 左右目的 RoI 对与真值框的 IoU 均大于 0.5 时为正样本;
- 左右目的 RoI 对与真值框的 IoU 有一个小于 0.5 且大于 0.1,则为负样本。
对于正样本,再用四个分支分别预测:
- object class;
- stereo bounding boxes,与 stereo rpn 中一致,左右目的高度已对齐;
- dimension,先统计平均的尺寸,然后预测相对量;
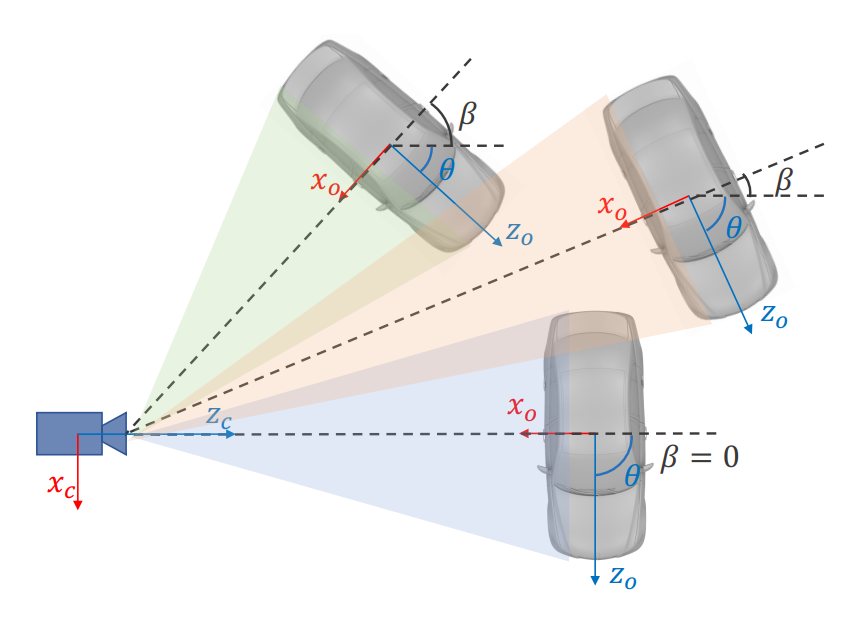
- viewpoint angle,如图 3 所示,\(\theta\)为相机坐标系下的朝向角,\(\beta\)为相机中心点下的方位角(azimuth),这三个目标在相机视野下是一样的,所以我们回归的量是视野角(viewpoint angle) \(\alpha=\theta+\beta\),其中 \(\beta=\arctan\left(-\frac{x}{z} \right)\)。并且为了连续性,回归量为 \([\sin \alpha,\cos \alpha]\)。
Keypoint Prediction
3D 框底部矩形的四个关键点,投影到图像平面后,最多只有一个关键点会在图像 2D 矩形框内。这个点被称为perspective keypoint。
对左目图像进行关键点预测,在 6×28×28 的基础上,因为关键点只有图像坐标 u 方向才提供了额外的信息,所以对每列进行累加,最终输出 6×28 的向量。
前 4 个通道代表每个关键点作为 perspective keypoint 投影到该 u 坐标下的概率;为了找出 perspective keypoint,softmax 应用于 4×28 的输出上;

后 2 个通道代表该 u 坐标是左右边缘关键点(boundary keypoints)的概率。为了找出左右边缘关键点,softmax 分别应用于后两个 1×28 的输出上。

3D Box Estimation
已知关键点,2D 框,尺寸,朝向角,我们可以求解出 3D 框\(\{x,y,z,\theta\}\)。求解目标是最小化 3D 框投影到 2D 框以及关键点的误差。如图 5 所示,已知 7 个观测量 \(z = \{u_l,v_t,u_r,v_b,u_l',u_r',u_p\}\),分别代表左目 2D 框的左上坐标,右下坐标,右目 2D 框的左右 u 方向坐标,以及 perspective keypoint 的 u 方向坐标。在图 5 的情况下(其它视角下,注意符号变化),左上点投影关系如下: \[ \require{cancel} \begin{bmatrix} u_l\\ v_t\\ 1\\ \end{bmatrix}=K\cdot \begin{bmatrix} x_{cam}^{tl}\\ y_{cam}^{tl}\\ z_{cam}^{tl}\\ \end{bmatrix}\doteq \xcancel{K} \cdot T_{cam}^{obj} \cdot \begin{bmatrix} x_{obj}^{tl}\\ y_{obj}^{tl}\\ z_{obj}^{tl}\\ \end{bmatrix}=\begin{bmatrix} x\\ y\\ z\\ \end{bmatrix}+ \begin{bmatrix} cos\theta & 0 &sin\theta\\ 0 & 1 & 0\\ -sin\theta & 0 & cos\theta\\ \end{bmatrix} \cdot \begin{bmatrix} -\frac{w}{2}\\ -\frac{h}{2}\\ -\frac{l}{2}\\ \end{bmatrix} \] 其中 \(K\)为相机内参,\(T_{cam}^{obj}\) 为目标中心坐标系在相机坐标系下的表示,\((⋅)_{cam/obj}\)分别为点在相机坐标系,目标中心坐标系下的表示。
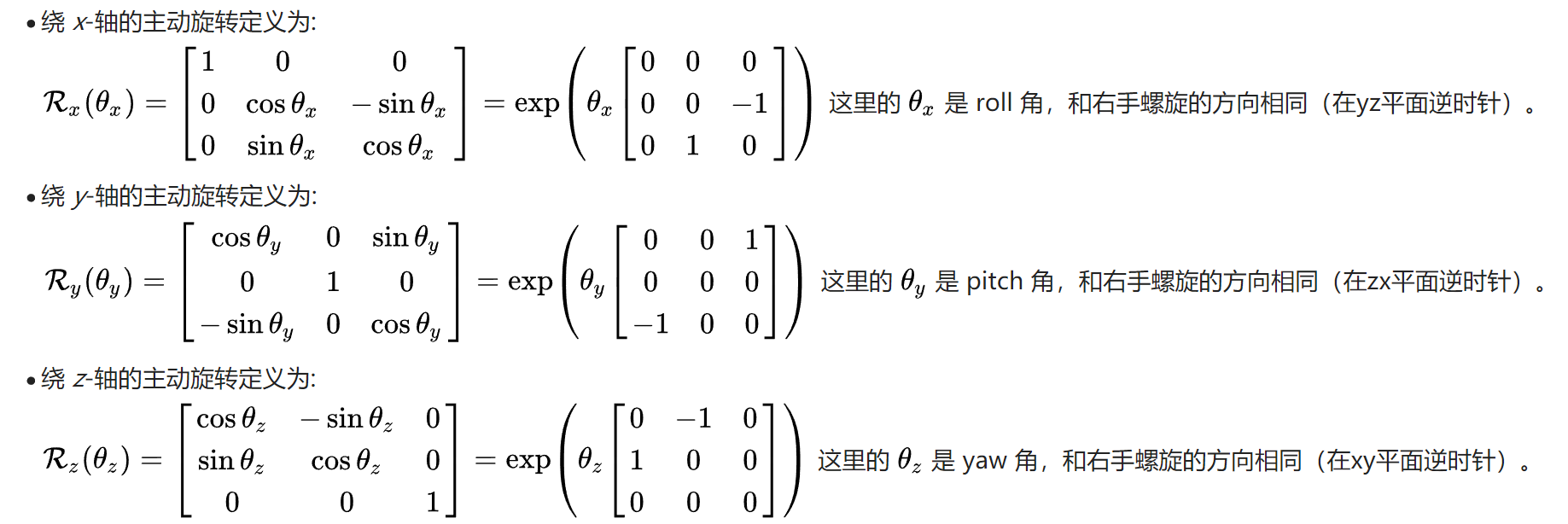
旋转矩阵的表示:
像素坐标系 - 相机坐标系 - 世界坐标系 的转换:

\[ \begin{bmatrix} u_l\\ v_t\\ 1\\ \end{bmatrix}= \begin{bmatrix} x-\frac{w}{2}cos\theta-\frac{l}{2}sin\theta\\ y-\frac{h}{2}\\ z+\frac{w}{2}sin\theta-\frac{l}{2}cos\theta\\ \end{bmatrix}= \begin{bmatrix} (x-\frac{w}{2}cos\theta-\frac{l}{2}sin\theta)/(z+\frac{w}{2}sin\theta-\frac{l}{2}cos\theta)\\ (y-\frac{h}{2})/(z+\frac{w}{2}sin\theta-\frac{l}{2}cos\theta)\\ 1\\ \end{bmatrix} \]
\[ u_l =(x-\frac{w}{2}cos\theta-\frac{l}{2}sin\theta)/(z+\frac{w}{2}sin\theta-\frac{l}{2}cos\theta) \]
\[ v_t =(y-\frac{h}{2})/(z+\frac{w}{2}sin\theta-\frac{l}{2}cos\theta) \]
同样的,这个视野下,右下点为: \[ \require{cancel} \begin{bmatrix} u_p\\ v_b\\ 1\\ \end{bmatrix}=K\cdot \begin{bmatrix} x_{cam}^{tl}\\ y_{cam}^{tl}\\ z_{cam}^{tl}\\ \end{bmatrix}\doteq \xcancel{K} \cdot T_{cam}^{obj} \cdot \begin{bmatrix} x_{obj}^{tl}\\ y_{obj}^{tl}\\ z_{obj}^{tl}\\ \end{bmatrix}=\begin{bmatrix} x\\ y\\ z\\ \end{bmatrix}+ \begin{bmatrix} cos\theta & 0 &sin\theta\\ 0 & 1 & 0\\ -sin\theta & 0 & cos\theta\\ \end{bmatrix} \cdot \begin{bmatrix} \frac{w}{2}\\ \frac{h}{2}\\ -\frac{l}{2}\\ \end{bmatrix} \]
\[ \begin{bmatrix} u_p\\ v_b\\ 1\\ \end{bmatrix}= \begin{bmatrix} x+\frac{w}{2}cos\theta-\frac{l}{2}sin\theta\\ y+\frac{h}{2}\\ z-\frac{w}{2}sin\theta-\frac{l}{2}cos\theta\\ \end{bmatrix}= \begin{bmatrix} (x+\frac{w}{2}cos\theta-\frac{l}{2}sin\theta)/(z-\frac{w}{2}sin\theta-\frac{l}{2}cos\theta)\\ (y+\frac{h}{2})/(z-\frac{w}{2}sin\theta-\frac{l}{2}cos\theta)\\ 1\\ \end{bmatrix} \]
\[ u_p =(x+\frac{w}{2}cos\theta-\frac{l}{2}sin\theta)/(z-\frac{w}{2}sin\theta-\frac{l}{2}cos\theta) \]
\[ v_b =(y+\frac{h}{2})/(z-\frac{w}{2}sin\theta-\frac{l}{2}cos\theta) \]
右图中,同样有: \[ \require{cancel} \begin{bmatrix} u_l'\\ v_t\\ 1\\ \end{bmatrix}=K\cdot \begin{bmatrix} x_{cam}^{tl}\\ y_{cam}^{tl}\\ z_{cam}^{tl}\\ \end{bmatrix}\doteq \xcancel{K} \cdot T_{cam}^{obj} \cdot \begin{bmatrix} x_{obj}^{tl}\\ y_{obj}^{tl}\\ z_{obj}^{tl}\\ \end{bmatrix}=\begin{bmatrix} x-b\\ y\\ z\\ \end{bmatrix}+ \begin{bmatrix} cos\theta & 0 &sin\theta\\ 0 & 1 & 0\\ -sin\theta & 0 & cos\theta\\ \end{bmatrix} \cdot \begin{bmatrix} -\frac{w}{2}\\ -\frac{h}{2}\\ -\frac{l}{2}\\ \end{bmatrix} \]
\[ \begin{bmatrix} u_l'\\ v_t\\ 1\\ \end{bmatrix}= \begin{bmatrix} x-b-\frac{w}{2}cos\theta-\frac{l}{2}sin\theta\\ y-\frac{h}{2}\\ z+\frac{w}{2}sin\theta-\frac{l}{2}cos\theta\\ \end{bmatrix}= \begin{bmatrix} (x-b-\frac{w}{2}cos\theta-\frac{l}{2}sin\theta)/(z+\frac{w}{2}sin\theta-\frac{l}{2}cos\theta)\\ (y-\frac{h}{2})/(z+\frac{w}{2}sin\theta-\frac{l}{2}cos\theta)\\ 1\\ \end{bmatrix} \]
\[ u_l' =(x-b-\frac{w}{2}cos\theta-\frac{l}{2}\sin\theta)/(z+\frac{w}{2}sin\theta-\frac{l}{2}cos\theta) \]
最后看\(u_r\)和\(u_r'\),求这两个量时,我发现此时\(v\)轴方向的量是不知道的。但是无关紧要,假设这个值为\(v_m\) \[ \require{cancel} \begin{bmatrix} u_r\\ v_m\\ 1\\ \end{bmatrix}=K\cdot \begin{bmatrix} x_{cam}^{tl}\\ y_{cam}^{tl}\\ z_{cam}^{tl}\\ \end{bmatrix}\doteq \xcancel{K} \cdot T_{cam}^{obj} \cdot \begin{bmatrix} x_{obj}^{tl}\\ y_{obj}^{tl}\\ z_{obj}^{tl}\\ \end{bmatrix}=\begin{bmatrix} x\\ y\\ z\\ \end{bmatrix}+ \begin{bmatrix} cos\theta & 0 &sin\theta\\ 0 & 1 & 0\\ -sin\theta & 0 & cos\theta\\ \end{bmatrix} \cdot \begin{bmatrix} \frac{w}{2}\\ \frac{h}{2}\\ \frac{l}{2}\\ \end{bmatrix} \]
\[ \begin{bmatrix} u_r\\ v_m\\ 1\\ \end{bmatrix}= \begin{bmatrix} x+\frac{w}{2}cos\theta+\frac{l}{2}sin\theta\\ y+\frac{h}{2}\\ z-\frac{w}{2}sin\theta+\frac{l}{2}cos\theta\\ \end{bmatrix}= \begin{bmatrix} (x+\frac{w}{2}cos\theta+\frac{l}{2}sin\theta)/(z-\frac{w}{2}sin\theta+\frac{l}{2}cos\theta)\\ (y+\frac{h}{2})/(z-\frac{w}{2}sin\theta+\frac{l}{2}cos\theta)\\ 1\\ \end{bmatrix} \]
\[ u_r =(x+\frac{w}{2}cos\theta+\frac{l}{2}sin\theta)/(z-\frac{w}{2}sin\theta+\frac{l}{2}cos\theta) \]
同理: \[ u_r' =(x-b+\frac{w}{2}cos\theta+\frac{l}{2}sin\theta)/(z-\frac{w}{2}sin\theta+\frac{l}{2}cos\theta) \] 综上,可整理出 7 个方程组(论文中第一个公式符号有错): \[ \left\{\begin{array}{l} u_l=(x- \frac{w}{2} cos\theta- \frac{l}{2} sin\theta) / (z+ \frac{w}{2} sin\theta - \frac{l}{2} cos\theta)\\ v_t=(y- \frac{h}{2}) / (z+ \frac{w}{2} sin\theta - \frac{l}{2} cos\theta)\\ u_p=(x+ \frac{w}{2} cos\theta- \frac{l}{2} sin\theta) / (z- \frac{w}{2} sin\theta - \frac{l}{2} cos\theta)\\ v_b=(y+ \frac{h}{2}) / (z- \frac{w}{2} sin\theta + \frac{l}{2} cos\theta)\\ u'_l=(x-b- \frac{w}{2} cos\theta- \frac{l}{2} sin\theta) / (z+ \frac{w}{2} sin\theta - \frac{l}{2} cos\theta)\\ u_r=(x+ \frac{w}{2} cos\theta+ \frac{l}{2} sin\theta) / (z- \frac{w}{2} sin\theta + \frac{l}{2} cos\theta)\\ u'_r=(x-b+ \frac{w}{2} cos\theta+ \frac{l}{2} sin\theta) / (z- \frac{w}{2} sin\theta + \frac{l}{2} cos\theta)\\ \end{array}\right. \] 其中\(b\)为双目的基线长(baseline)。以上方程组可用 Gauss-Newton 法求解。
在某些情况下,少于两个侧面可以被完全观察到,没有透视键指向上(例如,截断,正投影),方向和尺寸是无法从纯几何约束观察到的。我们使用的观点角度\(\alpha\)赔偿难以察觉的状态说明(见图3): \[ \alpha=\theta+\arctan(-\frac{x}{z}) \] 从二维方框和透视关键点求解,粗三维方框投影准确,与图像对齐良好,使我们进一步密集对齐。
Dense 3D Box Alignment
以上得到的目标 3D 位置是 object-level 求解得到的,利用像素信息,还可以进行优化精确求解。首先在图像 2D 目标框内扣取一块 RoI,要使 RoI 能较为确定的在目标上,扣取方式定义为:
- 目标一半以下区域;
- perspective keypoint 与边缘关键点包围区域;
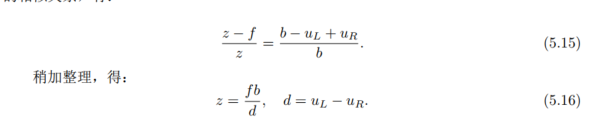
关键点预测的时候只预测了 u 方向的坐标,边缘关键点无 v 方向的信息,看起来会使某些背景像素被划入为目标像素,更好的方法是加入 instance segmentation 信息。定义误差函数为: \[ E=\sum_{i=0}^N e_i=\sum_{i=0}^N \left\| I_l(u_i,v_i)-I_r(u_i-\frac{b}{z+\Delta z_i},v_i)\right\| \] \(\Delta z_i = z_i-z\):表示某个像素点ii所对应的 3D 点与目标中心点之间的距离。最小化总误差即可求得最优的中心点距离\(z\)。

优化过程先以 0.5m 的精度找 50 步,再以 0.05m 的精度找 20 次。

注意,这种方法是有效的,可以是一个轻量级的插件模块,任何基于图像的三维检测,以实现深度校正。
Implementation Details
使用了五个比例为{32、64、128、256、512}的比例锚,三个比例为{0.5、1、2}。原始图像在短边被调整到600像素。对于立体RPN,由于左右特征图的拼接,最终的分类回归层有1024个输入通道,而实现FPN时只有512个输入通道。同样地,我们在R-CNN回归头中有512个输入通道。在Titan Xp GPU上,一个立体对的立体R-CNN推理时间约为0.28秒。
