人工智能考试期中复习
中国科学技术大学软件学院 人工智能2018年秋课程期中考试复习🍰
1、机器学习的定义
对于某类任务T和性能度量P,一个计算机程序被认为可以从经验E中学习是指,经过经验E改进后,它在任务T上由性能度量P衡量的性能有所提升。
任务T:Testing Set - 测试集
性能度量P:Loss Function - 损失函数
经验E:Training Set - 训练集
2、Loss Function/Cost Function - 损失函数
假设函数: \[ h_{w,b}(x) = wx+b \] 在回归任务中,多使用均方误差作为损失函数: \[ L(w,b) = \frac{1}{2m}\sum_{i=1}^{m}(h_{w,b}(x^{(i)}) - \hat{y}^{(i)})^2 \] 在分类任务中,多使用交叉熵作为损失函数: \[ L(w,b) = \frac{1}{m}\sum_{i=1}^{m}[-\hat{y}^{(i)}\log(h_{w,b}(x^{(i)})) - (1-\hat{y}^{(i)})\log(1-h_{w,b}(x^{(i)}))] \]
3、Sigmoid Function和Softmax Function
Sigmoid Function不具体表示哪一个函数,而是表示一类S型函数,常用的有逻辑函数σ(z): \[ \sigma(z) = \frac{1}{1+e^{-z}} \] Softmax Function,或称归一化指数函数,是逻辑函数的一种推广。它能将一个含任意实数的K维向量z “压缩”到另一个K维实向量 σ(z) 中,使得每一个元素的范围都在(0,1) 之间,并且所有元素的和为1。该函数的形式通常按下面的式子给出: \[ \sigma(z)_{j} = \frac{e^{z_{j}}}{\sum_{k=1}^{K}e^{z_{k}}} \quad j = 1,...,K \]
4、在Logistic Regression中,为何使用Cross Entropy作为损失函数而不使用MSE
Logistic Regression的假设函数如下: \[ \sigma(z) = \frac{1}{1+e^{-z}} \quad z(x) = wx+b \]
σ(z)分别对w和b求导,结果为: \[ \frac{\partial \sigma(z)}{\partial w} = \frac{\mathrm{d} \sigma(z)}{\mathrm{d} z} \frac{\partial z}{\partial w}= \sigma(z)(1-\sigma(z))*x \]
\[ \frac{\partial \sigma(z)}{\partial b} = \frac{\mathrm{d} \sigma(z)}{\mathrm{d} z} \frac{\partial z}{\partial b}= \sigma(z)(1-\sigma(z)) \]
如果使用MSE作为损失函数的话,那写出来是这样的: \[ L(w,b) = \frac{1}{2m}\sum_{i=1}^{m}(\sigma_{w,b}(x^{(i)}) - \hat{y}^{(i)})^2 \] 当我们使用梯度下降来进行凸优化的时候,分别需要计算L(w,b)对w和b的偏导数:
\[ \frac{\partial L(w,b)}{\partial w} = \frac{1}{m}\sum_{i=1}^{m}(\sigma_{w,b}(x^{(i)}) - \hat{y}^{(i)})\sigma_{w,b}(x^{(i)})(1-\sigma_{w,b}(x^{(i)}))x^{(i)} \]
\[ \frac{\partial L(w,b)}{\partial b} = \frac{1}{m}\sum_{i=1}^{m}(\sigma_{w,b}(x^{(i)}) - \hat{y}^{(i)})\sigma_{w,b}(x^{(i)})(1-\sigma_{w,b}(x^{(i)})) \]
所以在σ(x)接近于1或者0的时候,也就是预测的结果和真实结果很相近或者很不相近的时候,σ(x)和1-σ(x)中总有一个会特别小,这样会导致梯度很小,从而使得优化速度大大减缓。
而当使用Cross Entropy作为损失函数时,损失函数为: \[ L(w,b) = \frac{1}{m}\sum_{i=1}^{m}(-\hat{y}^{(i)}\log(\sigma_{w,b}(x^{(i)})) - (1-\hat{y}^{(i)})\log(1-\sigma_{w,b}(x^{(i)}))) \]
L(w,b)分别对w和b求偏导,结果如下: \[ \frac{\partial L(w,b) }{\partial w}= \frac{1}{m}\sum_{i=1}^{m}(\sigma_{w,b}(x^{(i)})-\hat{y}^{(i)})x^{(i)} \]
\[ \frac{\partial L(w,b) }{\partial b}= \frac{1}{m}\sum_{i=1}^{m}(\sigma_{w,b}(x^{(i)})-\hat{y}^{(i)}) \]
这样梯度始终和预测值与真实值之差挂钩,预测值与真实值偏离很大时,梯度也会很大,偏离很小时,梯度会很小。所以我们更倾向于使用Cross
Entropy而不使用MSE。函数图如下所示: 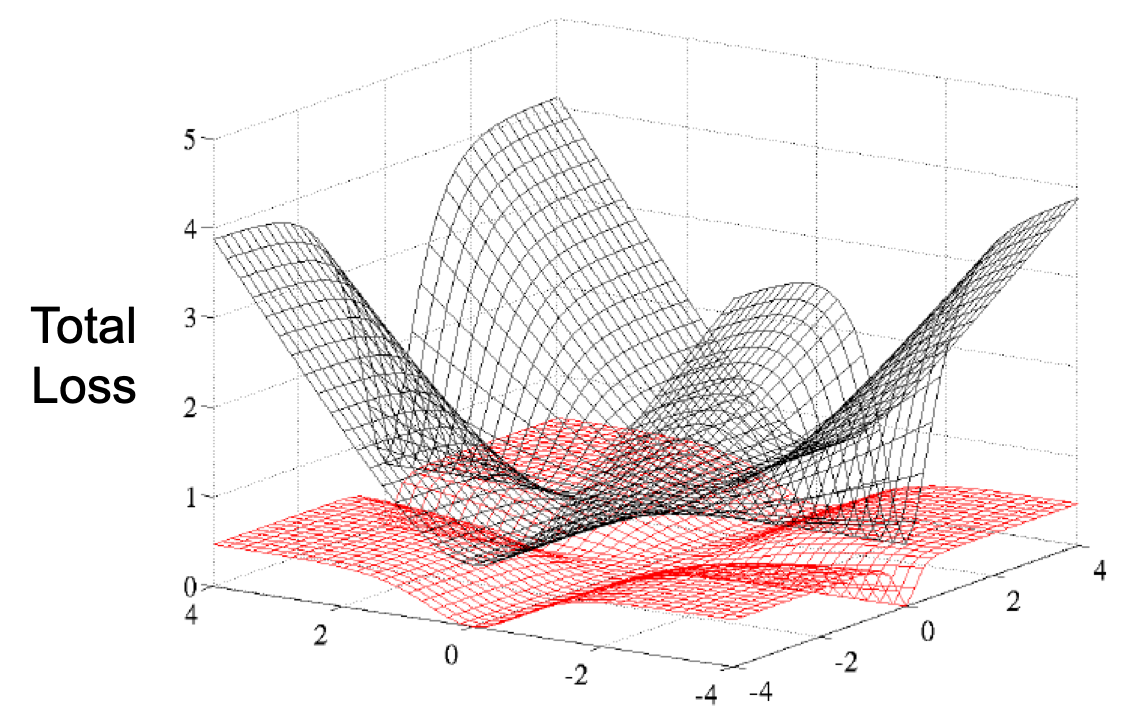
5、一堆优化方法
这堆优化方法只有一个目标:寻求合适的w和b(两个参数情况),使得L(w,b)损失函数的值最小。
(1) Gradient Descent - 梯度下降
如果需要找到一个函数的局部极小值,必须朝着函数上当前点所对应梯度(或者是近似梯度)的反方向,前进规定步长的距离进行迭代搜索。
\[ w' \leftarrow w - \eta \frac{\partial L(w,b)}{\partial w} \]
\[ b' \leftarrow b - \eta \frac{\partial L(w,b)}{\partial b} \]
tips: 这里不可以将更新好的w'代入到L(w,b)中然后计算b',参数w和b都必须等计算好后一起更新。
η代表学习率,部分决定了每一次更新的步长大小,如果学习率太低会导致更新十分缓慢,学习率太高又会导致步长太大全场乱跑。
为什么要以梯度的反方向为更新方向?
因为梯度方向是函数方向导数最大的方向,所以沿着梯度方向的反方向更新的话,函数下降的变化率最大。(感谢zzj在评论中指正)
(2) Stochastic Gradient Descent - 随机梯度下降
随机梯度下降的损失函数要这样定义:
\[ L^{(i)}(w,b) = \frac{1}{2}(h_{w,b}(x^{(i)}) - \hat{y}^{(i)})^2 \]
对比梯度下降的损失函数,发现这里少了求和以及求平均值的过程,因为这里只有一个样本作为参考,这个损失函数也是关于这一个样本的损失函数。
可以这样来理解:训练集里有20个样本,现在我就当作我只拥有这20个样本的其中一个样本,然后使用这一个样本更新参数,然后再挑另一个样本,更新参数,以此类推,直到所有样本都被用完后,这一轮随机梯度下降就结束了。
和梯度下降比较一下,随机梯度下降的好处是:梯度下降每次更新都用到了所有的样本,也就是使用所有样本的信息进行一次参数更新。而随机梯度下降每次更新只用到了一个样本,如果这个训练集有m个样本,那么梯度下降更新一次参数,随机梯度下降已经更新了m次参数了。所以随机梯度下降的更新频率是梯度下降的m倍,更新速度更快;
而随机梯度下降所带来的坏处是:随机梯度下降的更新只参考了一个样本,这种参考有点管中窥豹了,是不可能顾全大局的,所以更新时候的抖动现象很明显,就是参数的前进方向乱七八糟的,但是总体来说还是向着最低点前进。
(3) Mini-batch Gradient Descent - Mini-batch梯度下降
Mini-batch梯度下降是梯度下降和随机梯度下降的中和版本,随机梯度下降每次更新只考虑一个样本,梯度下降每次更新考虑所有样本,而Mini-batch梯度下降每次更新所考虑的样本是可以被指定的,如果总共有m个样本,那就可以在1~m中任意指定。
如果每次更新时所参考的样本数合适,那么既兼顾了随机梯度下降更新速度快的特性,又兼顾了梯度下降更新的稳定性。
可以说梯度下降和随机梯度下降都是Mini-batch梯度下降的一个特例,使用梯度下降时,指定每次更新参考全部样本,而使用随机梯度下降时,每次更新只参考1个样本。
注意:虽然随机梯度下降和Mini-batch梯度下降都是基于一部分数据进行参数更新,但是更新完后查看损失函数是基于全部训练数据所得出的训练误差。
(4) Adagrad算法
像Adagrad这一类自适应算法都是使用了自适应的学习率,他们都有一个基本思路:在整个训练过程中使用同一个学习率是不合适的,因为在训练开始时,损失值肯定是比较大的,所以需要较大的学习率,而训练快要结束时,越来越接近最低点了,此时需要较小学习率。所以这类算法会依据某些因素,在迭代过程中,逐渐减小学习率。
比如可以按下面这个公式来设计自适应的学习率,其中t代表了迭代次数:
\[ \eta^t=\frac{\eta}{\sqrt{t+1}} \]
这样学习率就会根据迭代次数来放缓学习率,从而达到学习率越来越小的目的。但是这样还是不够的,因为还要考虑到具体的函数情况。Adagrad算法不仅要求学习率跟着迭代次数变化,就是按上面的公式算出\(\eta^t\),还要再除以之前所有梯度的平方平均数,\(g^t\)代表了第t次迭代时的梯度。
\[ w^1 \leftarrow w^0 - \frac{\eta^0}{\sigma^0}g^0 \qquad \sigma^0 = \sqrt{(g^0)^2} \]
\[ w^2 \leftarrow w^1 - \frac{\eta^1}{\sigma^1}g^1 \qquad \sigma^1 = \sqrt{\frac{1}{2}[(g^0)^2+(g^1)^2]} \]
\[ w^3 \leftarrow w^2 - \frac{\eta^2}{\sigma^2}g^2 \qquad \sigma^2 = \sqrt{\frac{1}{3}[(g^0)^2+(g^1)^2 + (g^2)^2]} \]
\[ …… \]
\[ w^{t+1} \leftarrow w^t - \frac{\eta^t}{\sigma^t}g^t \qquad \sigma^t = \sqrt{\frac{1}{t+1}\sum_{i=0}^{t}(g^i)^2} \]
其中有\(\eta^t=\frac{\eta}{\sqrt{t+1}}\)代入到最后一个式子就可以得到: \[ w^{t+1} \leftarrow w^t - \frac{\frac{\eta}{\sqrt{t+1}}}{\sqrt{\frac{1}{t+1}\sum_{i=0}^{t}(g^i)^2}}g^t \]
同时约去\(\frac{1}{\sqrt{t+1}}\)后就可以得到:
\[ w^{t+1} \leftarrow w^t - \frac{\eta}{\sqrt{\sum_{i=0}^{t}(g^i)^2}}g^t \]
这就是Adagrad算法的公式了,我们可以看到这个式子中,学习率是会一直除以前面所有梯度的平方和再开根号的,这一定是一个大于0的数,所以学习率会越来越小。但是防止一开始的时候梯度就是0,如果让分母变为0会导致错误的,所以后面还要跟一个很小的正数\(\epsilon\),最终的式子是这样的: \[ w^{t+1} \leftarrow w^t - \frac{\eta}{\sqrt{\sum_{i=0}^{t}(g^i)^2+\epsilon}}g^t \]
Adagrad算法也有很多不足:
a) 如果初始的学习率设置过大的话,这个学习率要除以一个较大梯度,那么此算法会对梯度的调节太大; b) 在训练的中后期,分母上梯度平方的累加将会越来越大,使\(gradient\to0\),使得训练提前结束。
(5) *RMSprop算法
我感觉最多考到Adagrad算法就行了,RMSprop应该考不到。
在凸优化问题上,Adagrad算法具有很好的效果,但是在神经网络情况下,很多问题都是非凸优化问题,即损失函数有很多局部最小值,有了Adagrad算法的改进版RMSprop算法,RMSprop算法就像是真实物理世界中一个小球在山坡上向下滑,如果滑落到一个山谷中,小球是不会立刻停在这里的,由于具有惯性的原因,小球会继续向前冲,如果惯性足够的话,可能会再次冲出山头,更有可能会落到另一个更低的山谷中。而传统的梯度下降法只会落在一个山谷中,没有机会冲出来。 \[ w^1 \leftarrow w^0 - \frac{\eta}{\sigma^0}g^0 \qquad \sigma^0 = g^0 \]
\[ w^2 \leftarrow w^1 - \frac{\eta}{\sigma^1}g^1 \qquad \sigma^1 = \sqrt{\alpha(\sigma^0)^2 + (1-\alpha)(g^1)^2} \]
\[ w^3 \leftarrow w^2 - \frac{\eta}{\sigma^2}g^2 \qquad \sigma^2 = \sqrt{\alpha(\sigma^1)^2 + (1-\alpha)(g^2)^2} \]
\[ …… \]
\[ w^{t+1} \leftarrow w^t - \frac{\eta}{\sigma^t}g^t \qquad \sigma^t = \sqrt{\alpha(\sigma^{t-1})^2 + (1-\alpha)(g^t)^2} \]
Adagrad和RMSprop算法这两个算法很相近,不同之处在于RMSprop算法增加了一个衰减系数α来控制历史信息的获取多少。
6、Cross Validation - 交叉验证
将数据集D划分成k个大小相似的互斥子集,每次用k-1个子集作为训练集,余下的子集做测试集,最终返回k个训练结果的平均值。交叉验证法评估结果的稳定性和保真性很大程度上取决于k的取值。
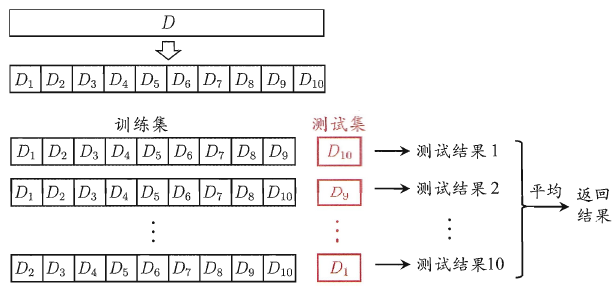
为什么要用交叉验证(Cross-Validation)
a) 交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合; b) 还可以从有限的数据中获取尽可能多的有效信息。
注意:交叉验证使用的仅仅是训练集!
7、偏差、方差、噪声以及泛化误差
(1) 偏差
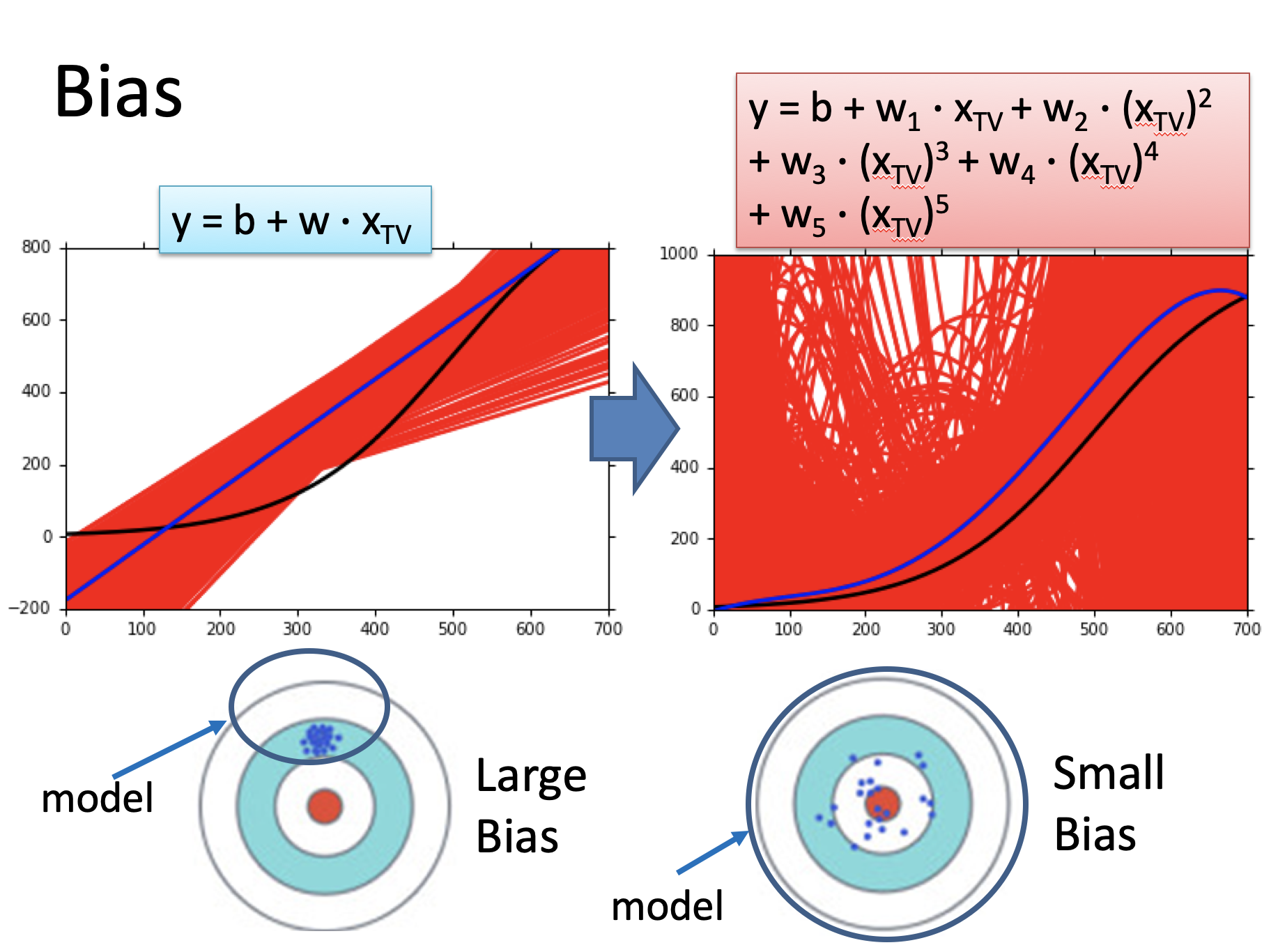
偏差bias: 期望预测与真实标记的误差,偏差越大偏离理论值越大。
上面的ppt里,左边的图模型阶数小,所以不可能很好的拟合真实情况,所作出的预测与真实情况偏离程度大,所以偏差就大;而右边的图里模型很复杂,足够模拟出真实情况,所以与真实情况偏离程度小,偏差就小。
在一个训练集\(D\)上模型\(f\)对测试样本\(x\)预测输出为\(f(x;D)\), 那么学习算法\(f\)对测试样本\(x\)的期望预测为:
\[ \bar{f}(x)=E_D[f(x;D)] \] 这里用偏差的平方来表示偏差的计算公式:
\[ Bias^2(x)=(\bar{f}(x)-\hat{y})^2 \]
(2) 方差
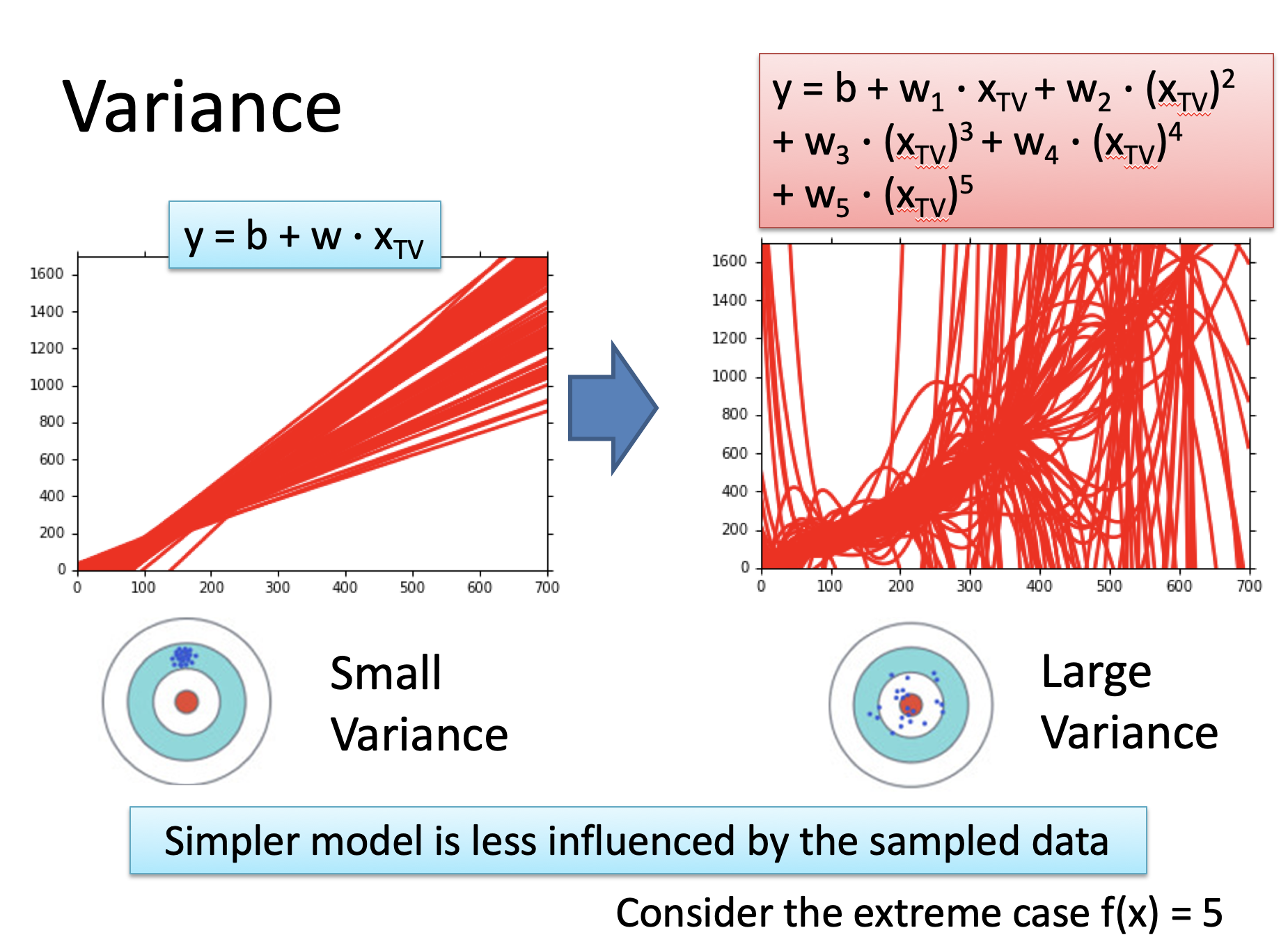
方差variance:预测模型的离散程度,方差越大离散程度越大。
就像上面ppt的左图,因为模型阶数小,所以模型都很集中;而右边的模型阶数大,有时能拟合的很好,有时拟合的不好,不稳定因素太大了。
使用样本数相同的不同训练集产生的方差为:
\[ var(x)=E_D[(f(x;D)-\bar{f}(x))^2] \]
(3) *噪声
不可能考
噪声为真实标记与数据集中的实际标记间的偏差\(y_D\)表示在数据集中的标记,\(\hat{y}\)表示真实标记,这两个可能不等):
\[ \epsilon=E_D[(y_D-\hat{y})^2] \]
(4) *泛化误差
也不可能考
学习算法的预测误差, 或者说泛化误差(generalization error)可以分解为三个部分: 偏差(bias), 方差(variance) 和噪声(noise). 在估计学习算法性能的过程中, 我们主要关注偏差与方差。因为噪声属于不可约减的误差 (irreducible error)。
下面来用公式推导泛化误差与偏差与方差, 噪声之间的关系。
以回归任务为例, 学习算法的平方预测误差期望为:
\[ Err(x)=E_D[(y_D-f(x;D))^2] \]
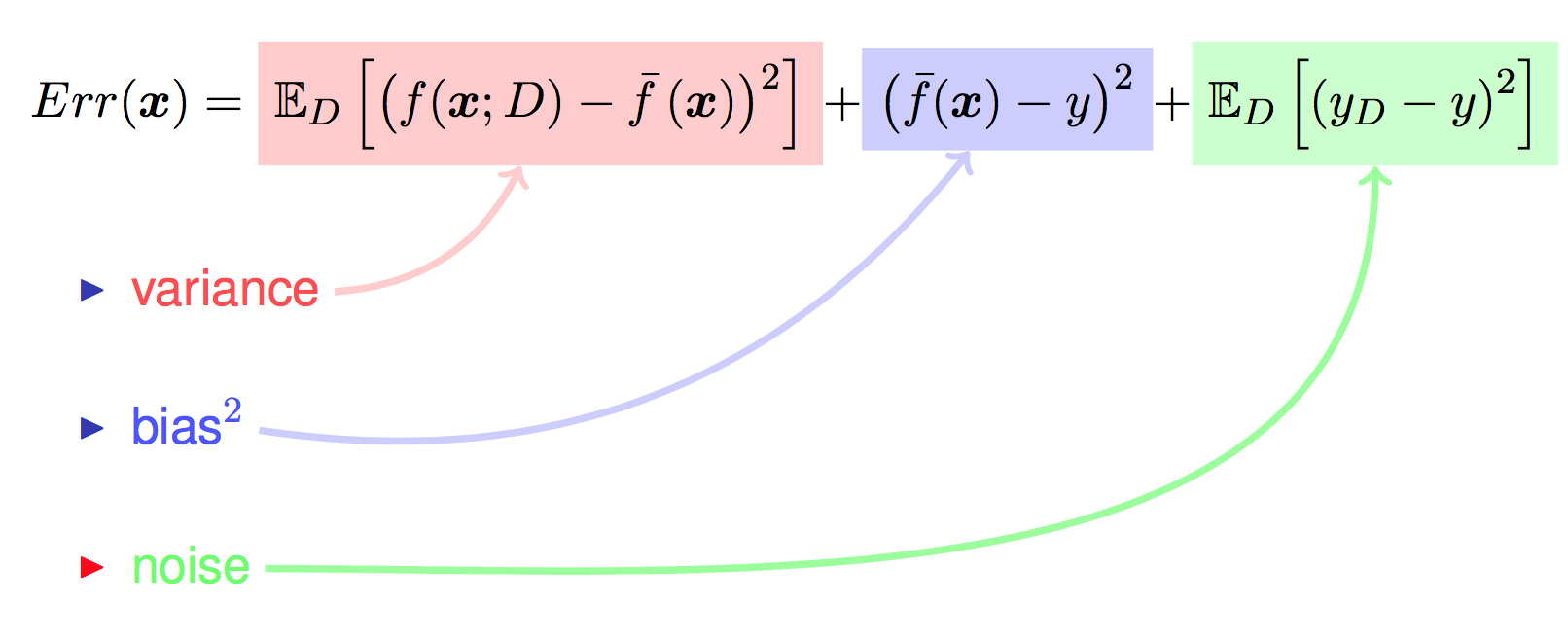
对算法的期望泛化误差进行分解,就会发现 泛化误差=偏差的平方+方差+噪声:
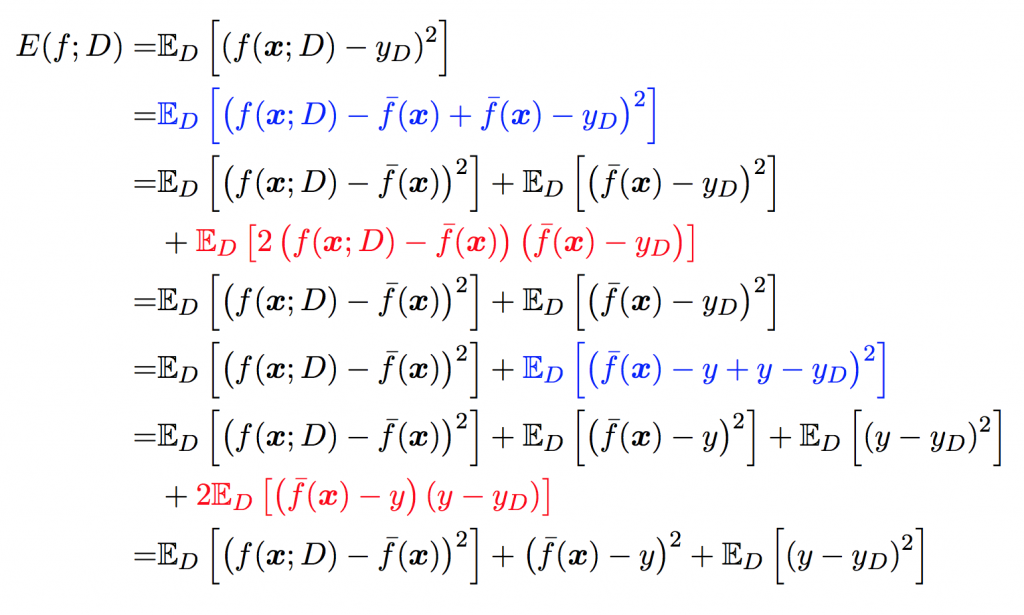
8、欠拟合和过拟合
欠拟合:模型拟合不够,在训练集上拟合情况很差。往往会出现偏差大、方差小的情况;
过拟合:模型过度拟合,在训练集上拟合情况很好,但是在测试集上拟合情况很差。往往会出现偏差小、方差大的情况。
出现欠拟合时,解决办法有:
a) 增加新特征,可以考虑加入特征组合、高次特征,来增大假设空间; b) 尝试非线性模型,比如核SVM 、决策树、DNN等模型; c) 如果有正则项可以减小正则项参数λ; d) Boosting,Boosting 往往会有较小的 Bias,比如 Gradient Boosting 等。
出现过拟合时,解决办法有:
a) 交叉检验,通过交叉检验得到较优的模型参数; b) 特征选择,减少特征数或使用较少的特征组合,对于按区间离散化的特征,增大划分的区间; c) 正则化,常用的有 L1、L2 正则。而且 L1正则还可以自动进行特征选择; d) 如果有正则项则可以考虑增大正则项参数 λ; e) 增加训练数据可以有限的避免过拟合; f) Bagging,将多个弱学习器Bagging 一下效果会好很多,比如随机森林等。
9、L1范数和L2范数
本来以为会很快写完这个部分的,没想到这里的知识点看了一晚上,更没想到这里的知识完完整整拿出来,完全可以写一篇长长的博文。如果想好好学习这里的知识的话,我推荐这个博客,或者是周老师的西瓜书第252页。这里我就介绍一点最基本的知识了。
L1范数:向量元素绝对值之和,即:
\[ \left \| \theta \right \|_1=\sum_{i=1}^{n}\left | \theta_i \right | \]
L2范数:这里我查了好久的资料,我发现网上所有的资料,包括周老师的西瓜书以及邱锡鹏教授的《神经网络与深度学习》都是说,L2范数是各个元素的平方和再求平方根,即:
\[ \left \| \theta \right \|_2=\sqrt{\sum_{i=1}^{n}\theta_i^2} \]
但是吴恩达教授、李宏毅教授课上讲的版本,以及我在学校课上(我们学校的课不就是照搬李宏毅教授的课嘛)所记录的版本,都是写的L2范数为各个元素的平方和,不再求平方根,即:
\[ \left \| \theta \right \|_2=\sum_{i=1}^{n}\theta_i^2 \]
吴恩达教授:
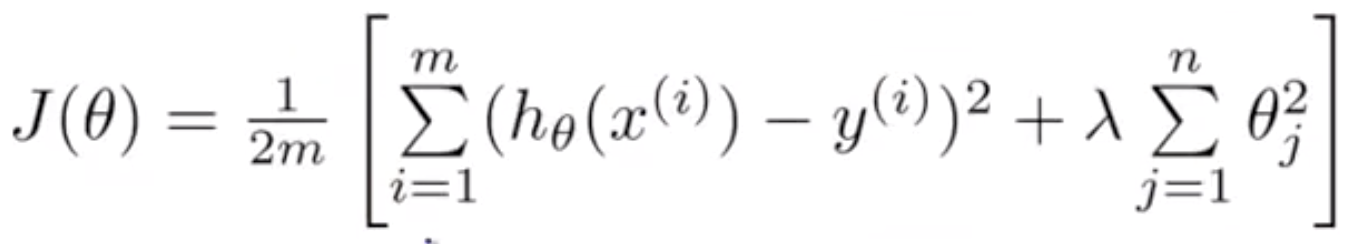
李宏毅教授:
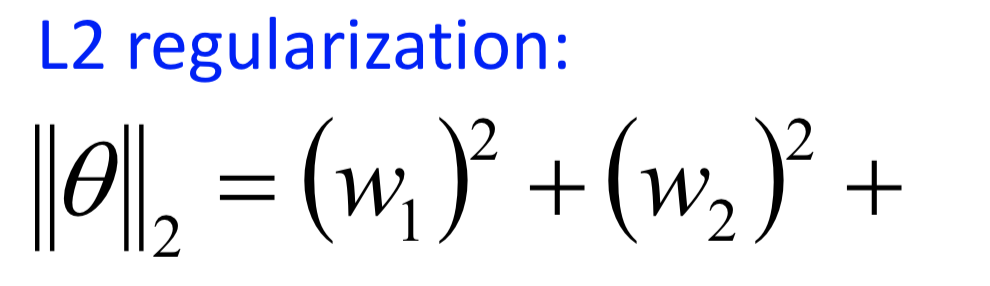
我的笔记就不拿出来了,和前两位的差不多。在这里我还是使用这个不开根号的版本。
(1) L1范数的作用
L1范数可以产生稀疏权值矩阵,一定程度上也可以防止过拟合。
稀疏权值矩阵的意思是,这个矩阵中大部分元素都是0,只有很小一部分元素不为0。试想一下当我们在看周杰伦演唱会时,只会把注意力放在周董身上,不太会关注伴舞小姐姐,更不可能去关注旁边又矮又胖的音响(这一句考试别写)。而在计算机视觉领域也一样,传进来一张图片,这个图片有很多很多的像素,但是机器真正要关注的只有其中一部分元素,比如一张田地里的农民,或是草地里的狗狗之类的,其他不重要的信息就直接不看了,所以和主题无关的信息都会乘上0,有意义的信息才会保留。自然语言处理也是一样,有很多无意义的词都会乘上0,只挑选有意义的信息保留下来。关于具体怎么实现的不讲了,去看周老师的西瓜书吧。
(2) L2范数的作用
L2范数主要用于防止模型过拟合。
L2范数比较重要一点,L2范数的作用是权值衰减,缩小各个权值,使得函数尽可能比不加L2范数平滑很多,增大模型的泛化能力。如果损失函数加上L2范数后,是这样:
\[ L(\theta) = \frac{1}{2m}[\sum_{i=1}^{m}(h_{\theta}(x^{(i)}) - \hat{y}^{(i)})^2 + \lambda\sum_{j=1}^{n}\theta_j^2] \]
当使用梯度下降时,得出的式子是这样的: \[ \theta_j' \leftarrow (1-\eta\frac{\lambda}{m})\theta_j - \eta\frac{1}{m} \sum_{i=1}^{m}(h_{\theta}(x^{(i)}) - \hat{y}^{(i)})x^{(i)} \]
每次参数更新时,都要先把原来的参数乘上一个介于0和1的数,所以参数都会先缩小一点点,再进行更新。一般来说\(1-\eta\frac{\lambda}{m}\)都会是一个很接近1的数,别看一个数打九九折后没什么变化,可是迭代次数多了后,这个权值是会衰减的很严重的。通过这种方法会有效降低权值,使得函数更为平滑,使得模型的泛化能力更强。
10、优化技巧
训练集中常常有些特征的范围差别很大,这样会导致在优化时,不同的参数优化速度差别很大。比如房子的大小从102000平米都有可能,而房间数只能处在110这个范围内,在进行优化时,房间数的参数很快就找到了最低点,而房子大小的参数还离最低点很远,这样的话,房间数的参数就在最低点来回波动,等待房子大小的参数优化好。如果能尽量让所有参数同时优化好,那么会大大提高优化速度。

(1) Feature Scaling - 特征缩放/归一化
归一化的思路是:让输入的值减去样本中最小的值,然后除以样本范围(也就是样本最大值减去样本最小值),这样会使得结果永远在0~1的范围内,所有特征参数差不多一个速度优化到最低点。式子如下:
\[ x'=\frac{x-min}{max-min} \]
(2) Mean Normalization - 均值标准化
均值标准化的思路是:让输入的值减去样本平均数μ,再除以样本标准差σ。经过这样的处理,数据的均值会是0,大小在-1~1之间。均值标准化和归一化一样,也有去除不同特征量纲不同的问题,另外机器学习中很多函数如Sigmoid、Tanh、Softmax等都以0为中心左右分布,所以数据以0为中心左右分布会带来很多便利。 \[ {x}'=\frac{x-\mu}{\sigma} \]
11、怎么调节学习率
当我们在训练过程中,发现loss下降的很慢时,可以适当增大学习率;发现loss不降反增的时候,要降低学习率。
如果我们使用的是Adagrad算法,那么一开始学习率可以设置的相对大一点。
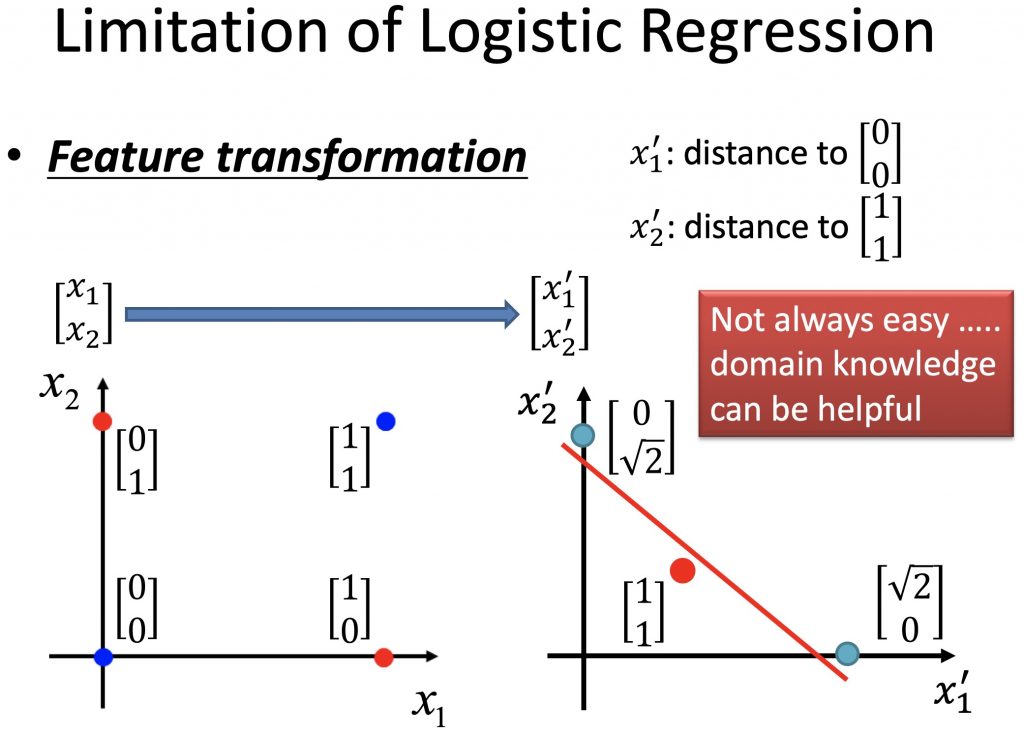
12、逻辑回归的局限性 - 深度神经网络的兴起导火索
逻辑回归不可以直接处理线性不可分的问题,例如下图所示的异或问题。处理方法是先通过一个函数,将原来的值投影转换,变成线性可分问题,再使用逻辑回归来处理。这一步叫做特征变换,先进行特征变换,再进行逻辑回归,这就是两层神经网络的雏形,也是神经网络的兴起的导火索。