分布式与云计算复习笔记
分布式与云计算2019春季课程笔记
这个东西吧,太简单了,我们这里不讲了
这个东西吧,比较难,后续我们在讲吧(后续后续。。。)
这里吧,(喝口水,ppt翻页),直接跳过了
天文地理鲁迅balabala,石竹老师先退票再买票,最后没抢到票我感到非常高兴233333
end
瞎划的重点:
⚡️远程过程调用 - Remote Procedure Call
⚡️面向流的通信 - Stream-oriented Communication
⚡️⚡️选举算法 - Election Algorithms
Chapter 1 概述
分布式系统的定义
分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像是单个相关的系统。
为了使种类各异的计算机和网络都呈现为单个的系统,分布式系统常常通过一个"软件层"组织起来,该"软件层"在逻辑上位于有用户和应用程序组成的高层与有操作系统组成的低层之间。这样的分布式系统又称为中间件(middleware)。
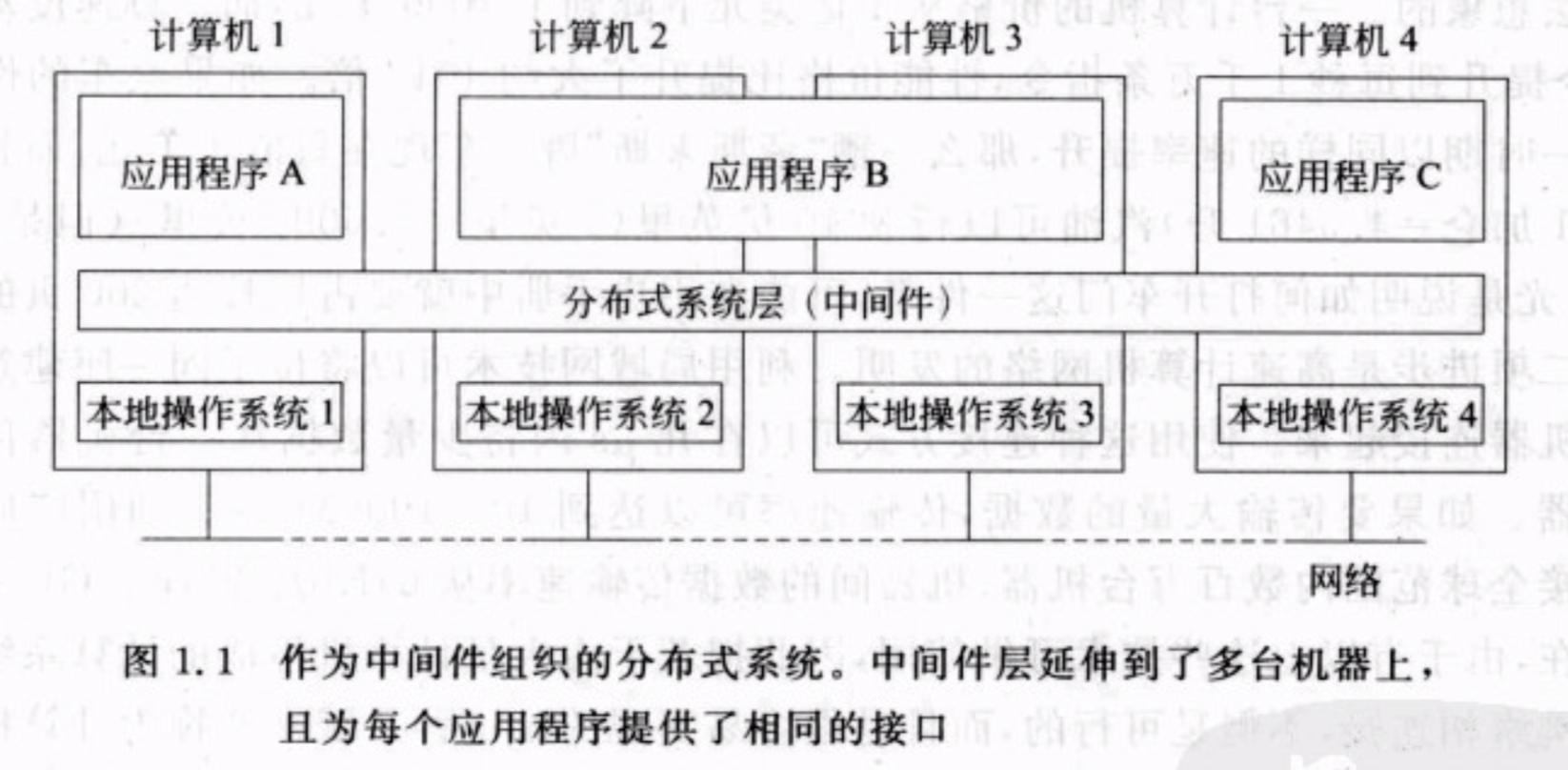
目标
使资源可访问
分布式系统最主要的目标是使用户能够方便地访问远程资源,并且以一种受控的方式与其他用户共享这些资源。
透明性
分布式系统的重要目标之一是将它的进程和资源实际上在多台计算机上分布这样一个事实隐藏起来。如果一个分布式系统在用户和应用程序面前呈现为单个计算机系统,这样的分布式系统就称为是透明的。
透明的类型
- 访问透明性:对不同数据表示形式以及资源访问方式的隐藏;
- 位置透明性:用户无法判别资源在系统中的物理位置;
- 迁移透明性:如果分布式系统中的资源移动不会影响该资源的访问方式,就可以说这种分布式系统能提供;
- 重定位透明性:如果资源可以在接受访问的同时进行重新定位,而不引起用户和应用程序的注意,拥有这种资源的系统能提供重定位透明性。
- 复制透明性:对同一个资源存在多个副本这样一个事实的隐藏;
- 并发透明性:隐藏资源是否由若干相互竞争的用户共享这一事实;
- 故障透明性:隐藏资源的故障与恢复。
透明度
在设计并实现分布式系统时,把实现分布的透明性作为目标是正确的,但是应该将它和其他方面的问题(比如性能)结合起来考虑。
开放性
开放式的分布式系统:根据一系列准则来提供服务,这些准则描述了所提供服务的语法和语义。
可扩展性
系统的可扩展性至少可以通过三个方面来度量:
- 规模可扩展:可方便向系统里加入更多用户和资源;
- 地域可扩展:可使系统中的用户与资源相隔十分遥远;
- 管理可扩展:即使分布式系统跨越多个独立的管理机构,仍然可以方便的对其进行管理。
可扩展性问题
分布式算法:
- 没有任何计算机拥有整个系统的全局信息;
- 计算机只根据本地信息做出决策;
- 某台计算机的故障不会使算法崩溃;
- 不存在全局时钟。
扩展技术
隐藏通信等待时间
- 使用异步通信,通常用于批处理系统;
- 启动一个新的控制线程来执行请求。
问题:有许多应用程序不适用此方式。
分布技术
把某个组件分割成多个部分,然后再把他们分散到系统中去。
例:DNS、万维网WWW
复制技术
对组件进行复制并将副本分布到系统各处。
缓存是复制的一种特殊形式。缓存一般是在访问资源的客户附近制作该资源的副本。
分布式系统的类型
分布式计算系统
用于高性能计算任务的系统。
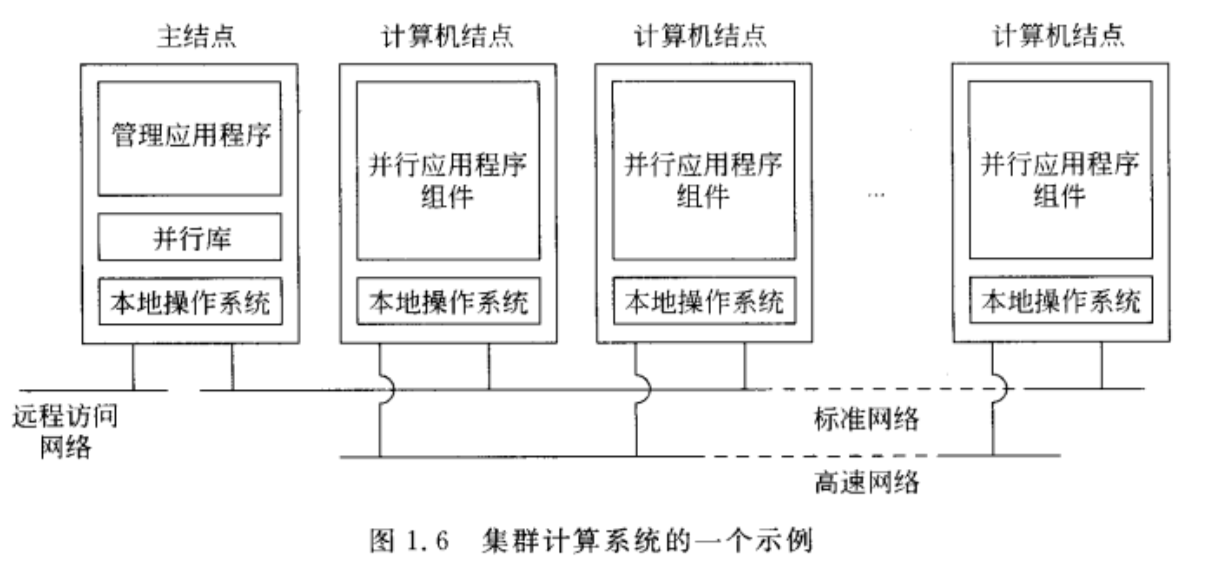
集群计算系统
底层硬件是由类似的工作站或PC集组成,通过高速的局域网紧密连接起来的。而且,每个节点运行的是相同的操作系统。
集群计算系统的特点是同构性,大多数情况下,集群中的计算机都是相同的:
- 有相同的操作系统
- 通过同一网络连接
网格计算系统
组成分布式系统的子分组通常构建成一个计算机系统联盟,每个系统归属于不同的管理域。
网格计算系统具有高度异构性:
- 硬件
- 操作系统
- 网络
- 管理域
- 安全策略
都不尽相同。
以虚拟组织的方式,把来自不同计算机组织的资源集中起来,是一组人或机构协调工作。属于同一虚拟组织的人,具有访问提供给该组织的资源的权限。
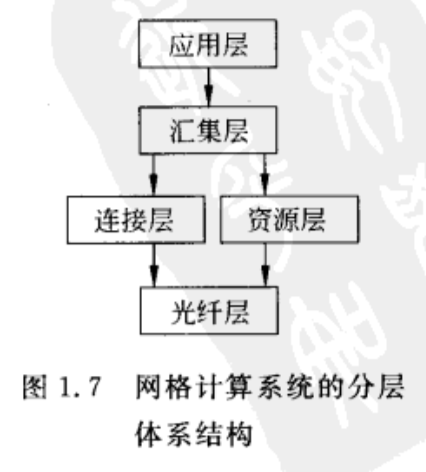
光纤层:在特定站点提供对局部资源的接口。这些接口都进行了定制,以允许在某个虚拟组织中实现资源共享。
连接层:由通信协议组成,用于支持网格事务处理,延伸多个资源的使用。例如,用于在资源之间传输数据或从远程地点访问资源的协议。另外,连接层还有安全协议,用于进行用户和资源的认证。
资源层:负责管理单个资源。它使用由连接层提供的功能,直接调用对光线层可用的接口。
汇集层:负责处理对多个资源的访问,通常由资源分派、把任务分配和调度到多资源以及数据复制等服务组成。连接层和资源层由相对较小、较标准的协议集组成,而汇集层由很多用于不同目的的不同协议组成。
应用层:由应用程序组成。
分布式信息系统
分布式普适系统
Chapter 2 体系结构
体系结构的样式
根据组件、组件之间相互的连接方式、组件之间的数据交换以及这些元素如何集成到一个系统中来定义。
- 组件Component:一个模块单元,可以提供良好定义接口,在其环境中是可替换的。
- 链接器Connector:在组件之间传递通信、使组件相互协调和协作。
根据组件和连接器的使用,划分成不同体系结构:
分层体系结构
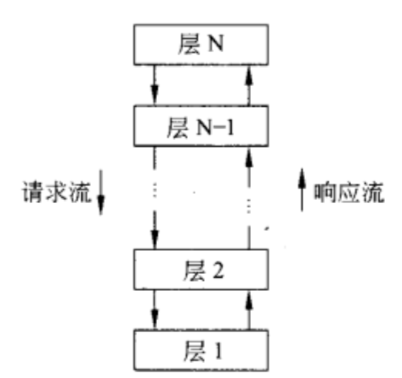
组件组成了不同的层,其中\(L_i\)层中的组员可以调用下面的层\(L_{i-1}\)。
基于对象的体系结构
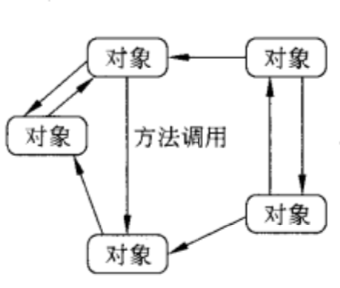
每个对象都对应一个组件,这些组件是通过(远程)过程调用机制来连接的。
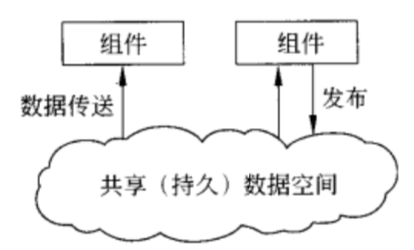
以数据为中心的体系结构
通过一个公用(被动或主动的)仓库进行通信。
基于事件的体系结构
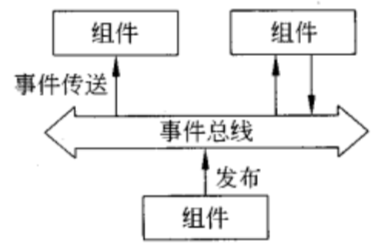
通过事件的传播来通信。
系统体系结构
集中式体系结构
客户-服务器的交互方式,又被称为请求-回复行为。
幂等操作:如果某个操作可以重复多次而无害处,那么称它是幂等的。
应用分层
客户-服务器模型分为三层:
- 用户接口层,用于与用户交互;
- 处理层,包含应用程序;
- 数据层,管理要使用的实际数据。
多层体系结构
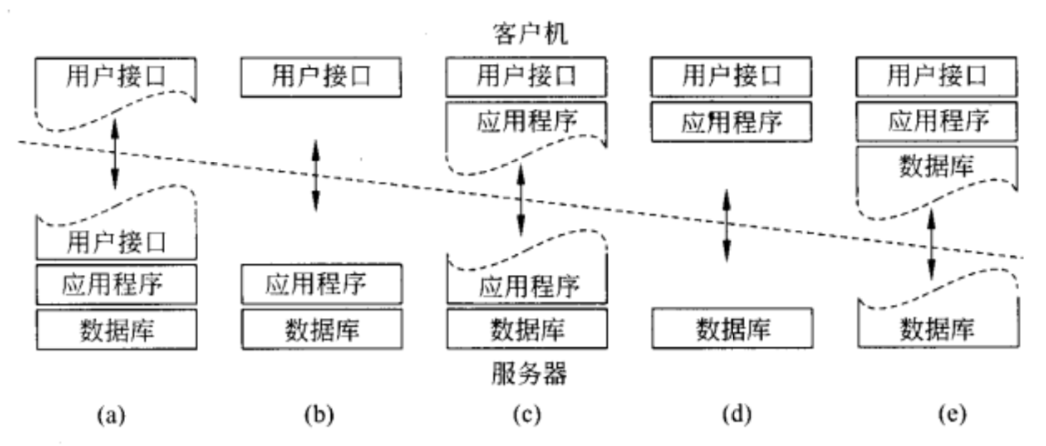
非集中式体系结构
结构化的点对点体系结构
点对点体系结构:在结构化的点对点体系机构中,覆盖网络是一个确定性的过程来构成的。这个使用最多的进程是通过一个分布式哈希表来组织进程的。

非结构化的点对点体系结构
很多非结构化的点对点系统的一个目标就是构造一个类似于随机图的覆盖网络。
超级对等体
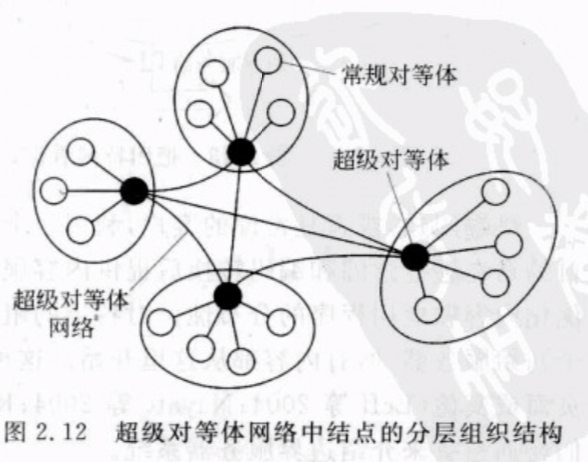
能维护一个索引或者充当一个代理程序的结点称为超级对等体,控制管理多个常规对等体。每个常规对等体作为一个客户连接到超级对等体。
混合体系结构
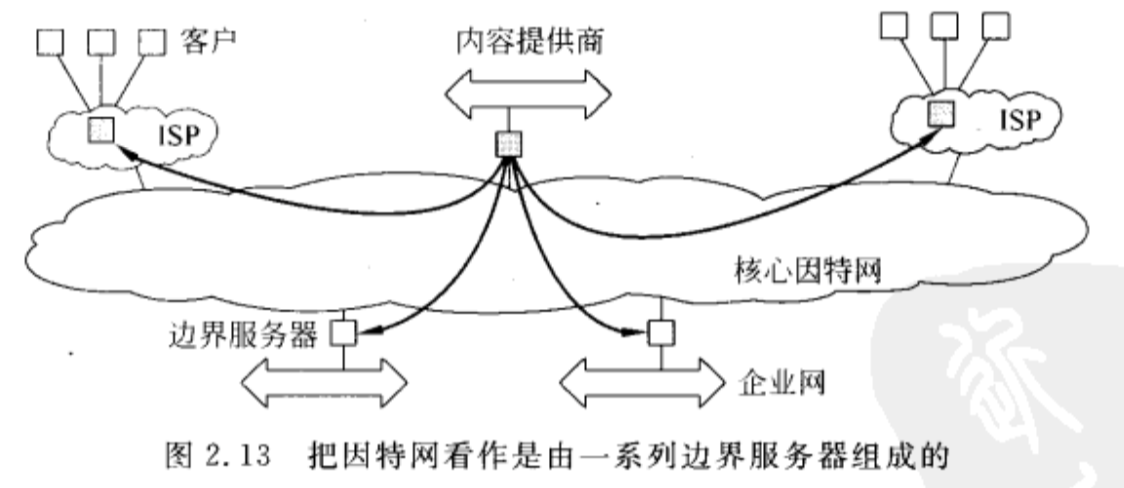
边界服务器系统
这种系统部署在因特网中,服务器放置在网络的“边界”。这种边界是由企业网络和实际的因特网之间的分界线形成的。例如,因特网服务提供商。家庭终端用户通过ISP连接到因特网,该ISP就可以认为是因特网的边界。
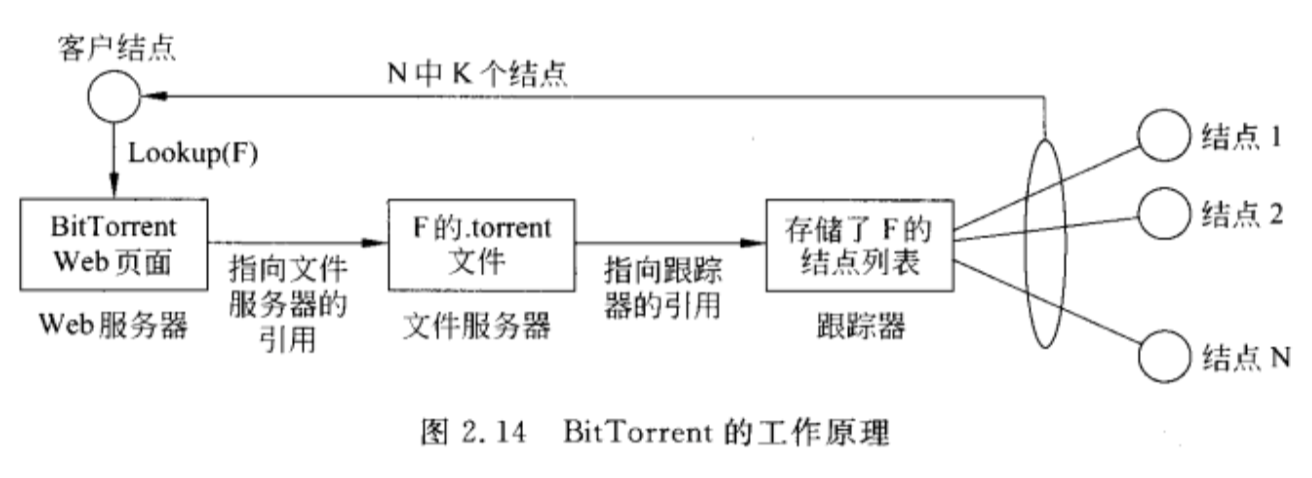
协作分布式系统
混合结构主要部署在协作式分布式系统中。在很多重要的系统中,主要问题是先启动起来,因为经常会部署一个传递的客户-服务器结构。一旦某个结点要加入系统,就可以使用完全非集中式的组织结构,用于协作。
BitTorrent是一个点对点的文件下载系统。基本思想是,当一个终端用户要查找某个文件时,他可以从其他用户那里下载文件块,直到所下载的文件块能够组装成完整的文件为止。
分布式系统的自我管理
自治计算:以高级反馈控制系统的形式来组织分布式系统,允许自动自适应变换。也叫做自主系统。
自适应的多样性:
- 自我管理
- 自我恢复
- 自我配置
- 自我优化
- 等
反馈控制模型

反馈控制系统的核心由需要管理的组件形成。这些组件能通过可控输入参数驱动,受干扰或噪声输入的影响。
系统本身需要被监视,因此需要对系统各个方面进行测量。但是实际测量很难做到,就需要一个逻辑尺度预测组件。
控制循环的核心部分是反馈分析组件,分析上述测量值,并把它们与参考值进行比较。包含了决定自适应的各种算法。
Chapter 3 进程
线程
为什么要使用线程?
虽然进程构成了分布式系统中的基本组成单元,但是实践表明,操作系统提供的用于构建分布式系统的进程在粒度上还是太大了。而就粒度而言,将每个进程细分为若干控制线程的形式则更加合适,可以使构建分布式应用程序变得更加方便,获得更好的性能。
线程与进程不同之处?
- 线程不会以性能降低为代价,换取高度的并发透明性。
- 线程上下文一般只包含存储在寄存器和存储器中的尽可能少的信息,仅仅用于执行一系列指令。
分布式系统中的线程
多线程客户端
多线程客户端最大的问题是如何隐藏网络延时。常规方法是启动网络通信线程后,立即进行其他工作。
多线程服务器
在服务器上使用多线程技术有很多好处:
可以提升性能
- 启动一个线程处理请求比启动进程开销更小
- 可以隐藏网络延时。当有请求到来时,也可以做其他工作。
结构更优
多线程程序的结构会更简单。
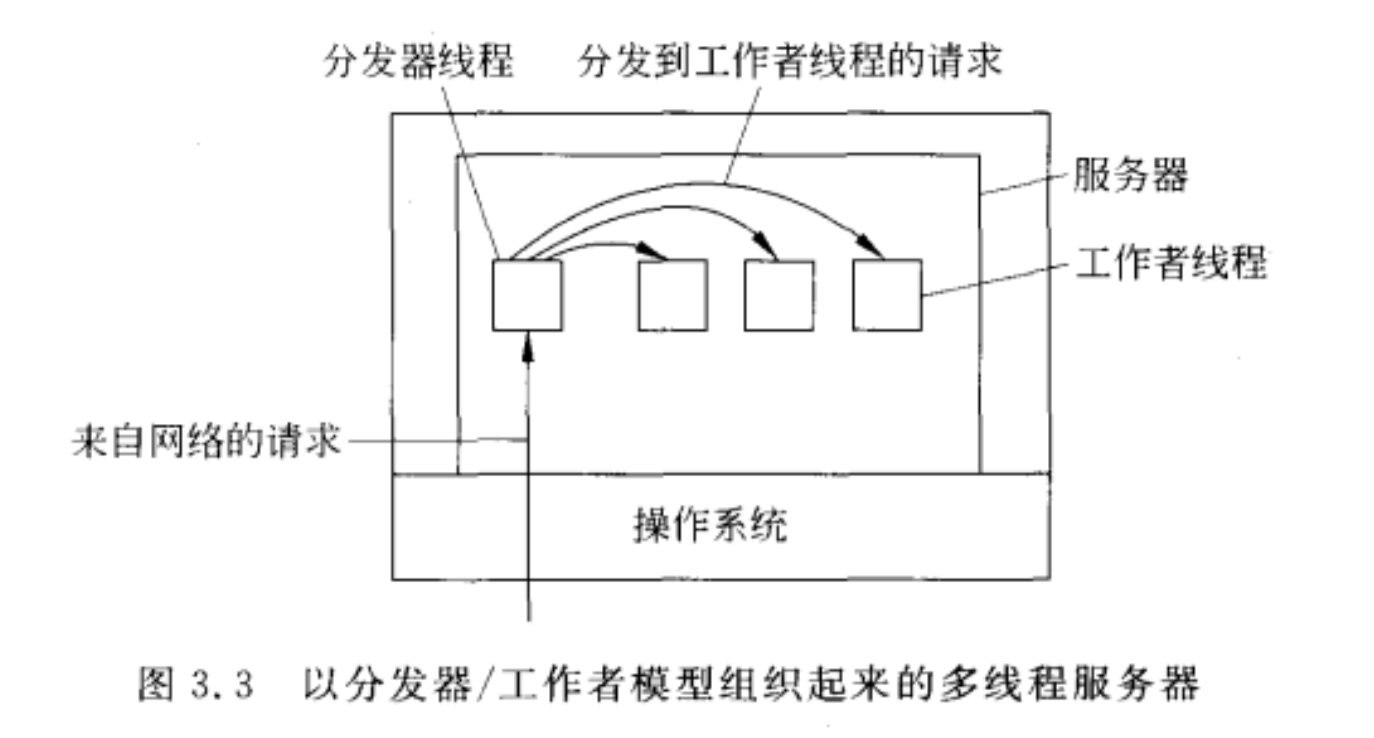
上图中,分发器线程读取文件操作请求,随后选择一个空闲的工作者线程来处理请求。
⚡️虚拟化
虚拟化:把一样东西看成另一个东西
- 多虚一,多个资源虚拟整合成一个资源;
- 一虚多,把一个资源虚拟成多个,供多用户使用,可弥补运营成本;
- 做隔离,底层和上层之间不可见,便于移植;早期用于程序迁移。
虚拟机体系结构
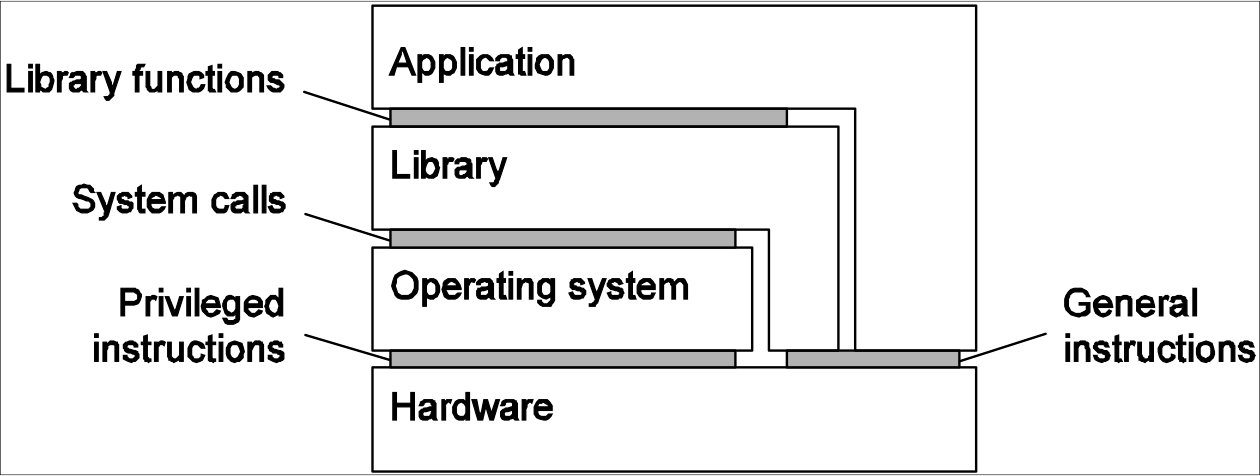
计算机系统通常在4个不同层次提供4个不同的界面:
由机器指令组成,任何程序都可激起的,介于硬件软件之间的界面;
Interface between hardware and software, non-privileged.
由机器指令组成,只有特权程序(e.g 操作系统)才可激起的界面;
Interface between hardware and software, privileged.
有操作系统提供的系统调用组成的界面;
System calls.
由库调用组成的界面,通常形成了所谓的应用程序编程接口(API)。
Libraries functions.
而虚拟化的实质就是模仿这些界面的行为。
- 指令集虚拟化的代价很高;
- 硬件虚拟化,性能损失不大,是虚拟化的主流。
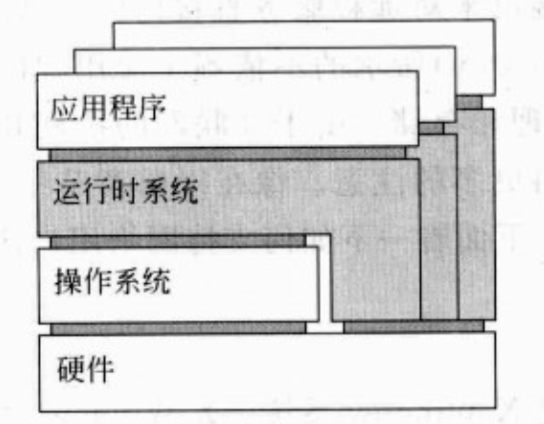
虚拟机的两种方式
构建一个运行时(runtime)系统,实质上提供了一套抽象指令集来执行程序。例如Java虚拟机,将指令进行翻译,使用库虚拟化;还有使用Windows操作系统模拟Linux,是OS虚拟化。
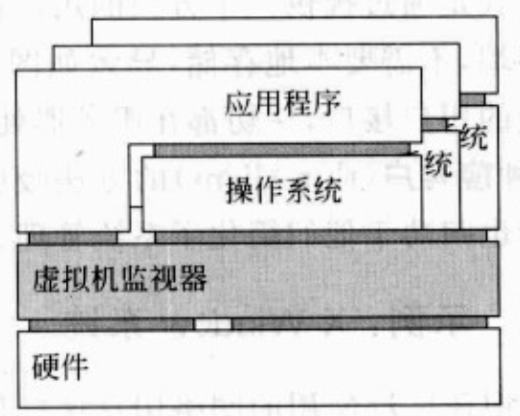
使用虚拟机监视器(VMM)这一层,虚拟机监视器完全屏蔽硬件,但提供一个同样指令集(或其他硬件)的界面。这个界面可以同时提供给多个程序,可以有多个不同的操作系统独立并发地运行在同一平台。
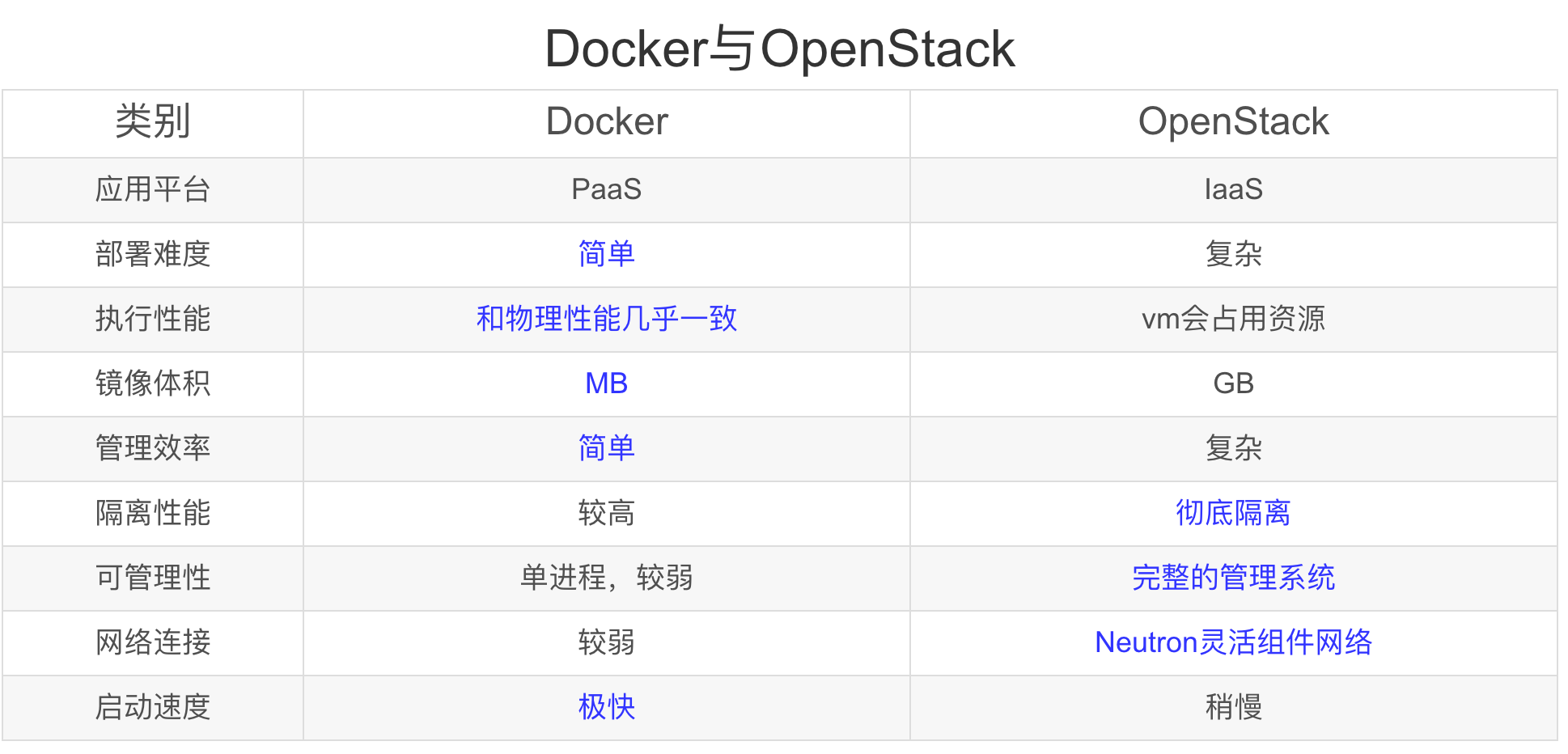
虚拟化 v.s. 容器
虚拟化:OpenStack
使用OpenStack做虚拟化时,它可以将操作系统都一并打包好,各个虚拟机之间完全隔离,互不干涉。
层次结构:
- 最顶层应用
- 操作系统(任意的操作系统)
- OpenStack
- 底层硬件
容器:Docker
Docker是基于进程容器(Process container)的轻量级VM解决方案,用比虚拟机技术少很多的资源消耗实现了类似于虚拟机的对CPU、磁盘、网络的隔离。
层次结构:
- 最顶层应用
- Docker
- 操作系统(仅限Linux)
- 底层硬件
OpenStack与Docker的区别
客户端
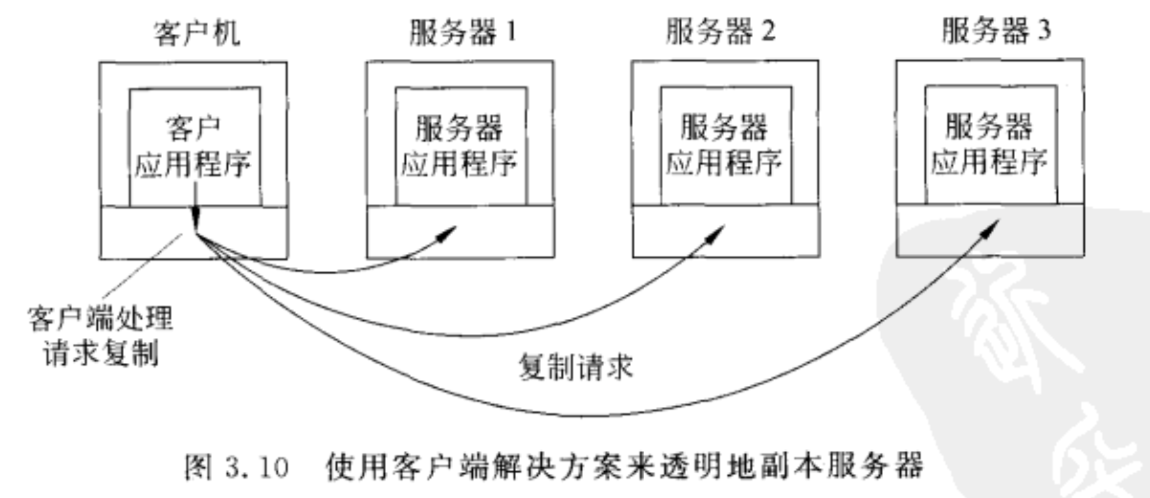
客户端软件与分布透明性
一个带有副本服务器的分布式系统,可以通过将调用请求转发给每一个服务器的副本来达到复制透明性。客户代理将会透明地偶素即所有对象的响应,并且只向客户应用程序送回一个返回值。
服务器
迭代服务器
自己处理请求,并且在必要的情况下将响应返回给发出请求的客户。
一次只能处理一个客户端请求,而并发服务器不同。
并发服务器
并不自己处理请求,而是将请求传递给某个独立线程或者其他进程来处理,自身立即返回并等待下一个输入的请求。
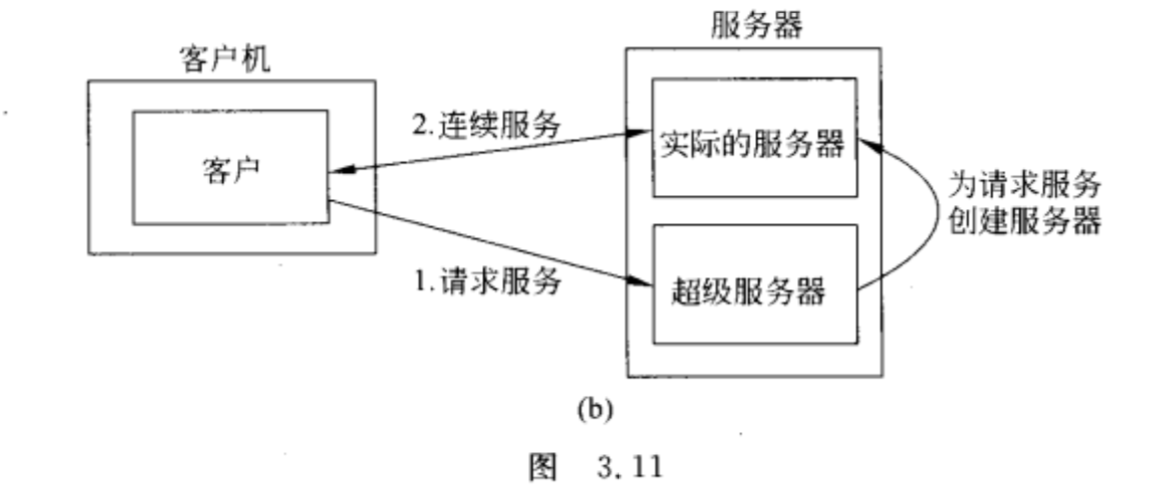
超级服务器
负责监听所有与这些服务关联的端点,当收到请求的时候,它派生出一个进程已对该请求进行进一步处理,这个派生出的进程在处理完毕后将会自动退出运行。
状态无关服务器
不保存器客户的状态信息,而且也不将自身的状态变化告知任何客户。
- 不记录文件是否已经打开(只在访问后再次关闭文件);
- 不一定会使得客户的缓存变无效;
- 不跟踪客户行为。
后果:
- 客户端与服务器端完全独立;
- 非无状态服务器的情况下,由于客户或者服务器端某一方发生崩溃,从而导致双方状态不一致。而在无状态服务器中,因为是无状态的,这种状态不一致的情况大大减小了;
- 因为某些原因性能可能会有所降低,例如服务器无法预测客户的行为(比如预取文件块)。
状态相关服务器
跟踪客户的状态,一直保留客户端的信息直到被显式删除,包括:
- 记录文件已被打开,以便可以进行预取;
- 知道客户端缓存了哪些数据,并允许客户端保留共享数据的本地副本
如果允许客户端保留本地副本,则可以提升读写操作的性能。
缺陷:
- 如果服务器崩溃,那么必须将自身的整个状态恢复到崩溃之前。但是如果采用状态无关设计,就不需要采取任何特殊措施来使崩溃的服务器恢复。
Cookies
Cookies是一小段数据,其中包含有对服务器有用的针对特定客户的信息。浏览器本身永远不会执行cookie,它只对cookie进行存储。
Cookies可用于将当前客户端操作与先前操作相关联,也可用于状态的存储。
服务器集群
常见的组织
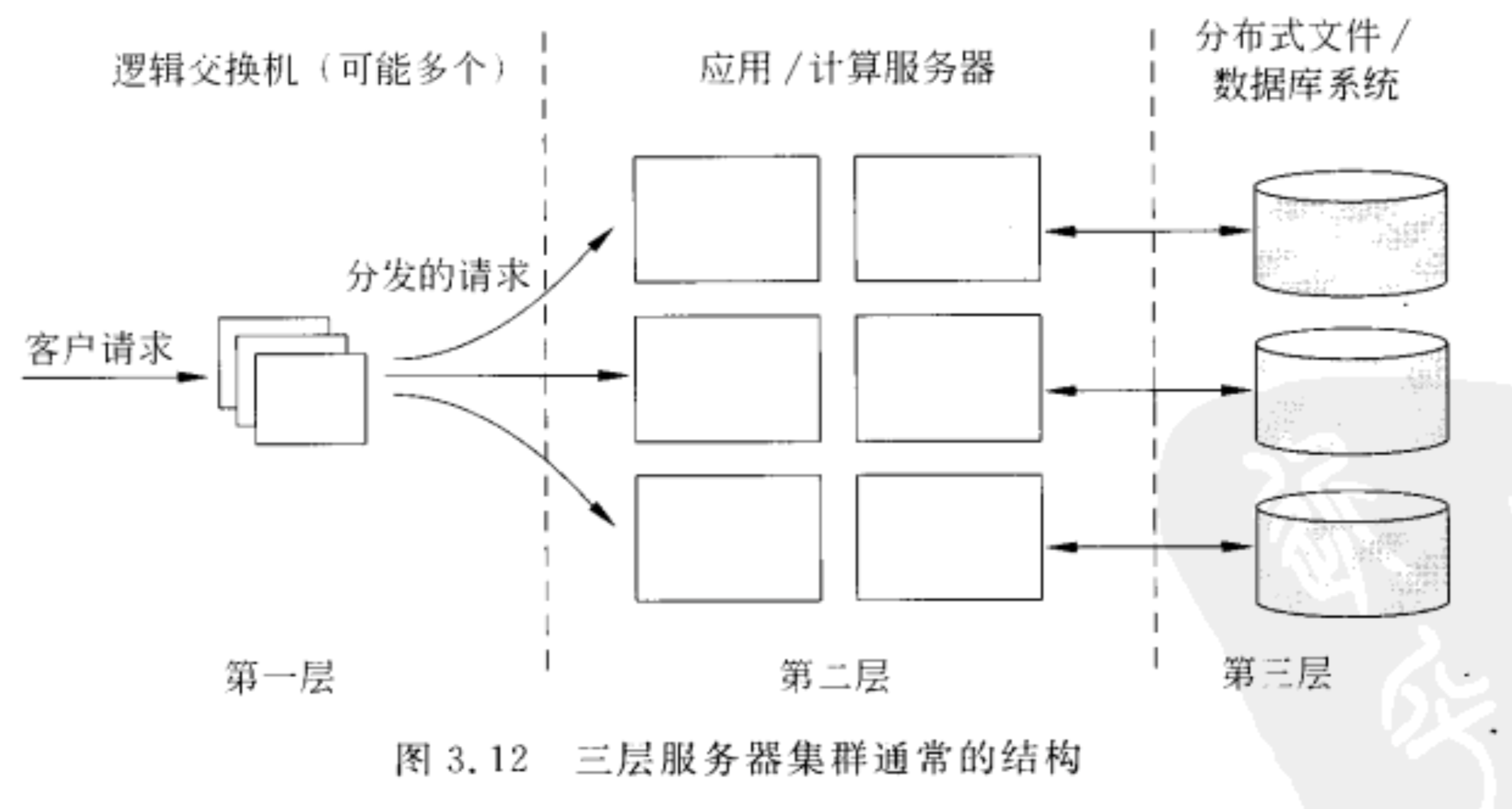
服务器集群逻辑上由三层组成。
- 第一层:(逻辑上的)交换机,由它分配客户请求给服务器;
- 第二层:应用计算服务器,是专用于提供计算能力的服务器;
- 第三层:文件和数据库服务器,是分布式文件系统或分布式数据库系统。
交换机形成了集群入口,提供了唯一的网络地址。
一种标准的存取服务器集群的方式是建立一个TCP连接,在这之上应用级别的请求可作为一个会话的一部分来发送,撤除连接可结束会话。在传输层交换机的情况下,交换机接受到来的TCP连接请求,转发这些请求给一台服务器。

当交换机收到一个TCP连接请求时,他就找到处理这个请求的最佳服务器,并转发这个请求包给这个服务器。服务器反过来会发送一个应答给请求的客户,但把交换机的IP地址插入到承载TCP数据段的IP包头的原地址域。(看上去是服务器欺骗客户自己是交换机,但是客户等待的是交换机的应答,而不是某个不知名的服务器,所以这种欺骗是必须的。从而可以看出,实现TCP转发需要操作系统级别的修改)
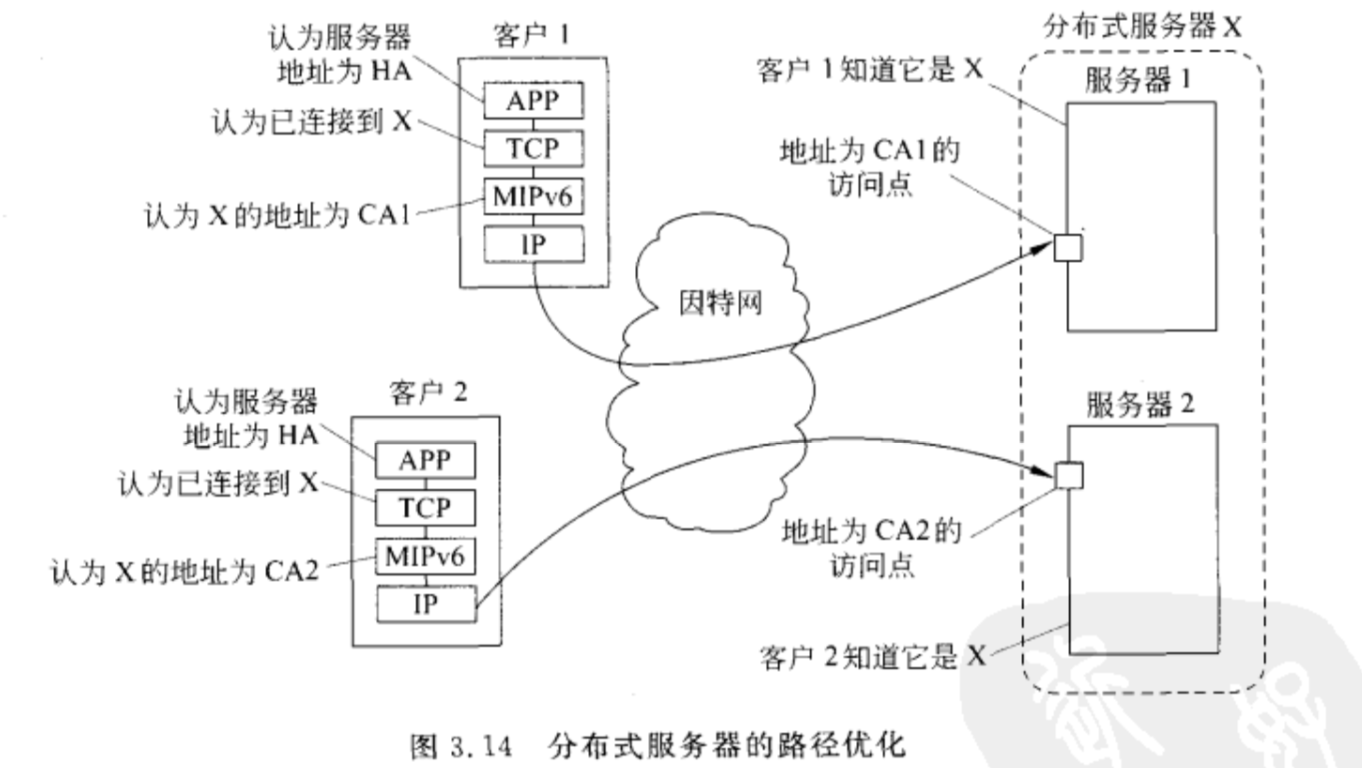
分布式服务器
分布式服务器指可动态变化的一个机器群,它的访问点也可以变化,但对外却表现为一强有力的单台机器。
如何在这样的系统中实现一个稳定访问点?
主要思想是利用可用的网络服务,比如IP版本6的移动支持(MIPv6)。在MIPv6中,一个移动结点假设有一个宿主网络,通常待在这个网络中,并有稳定的地址,称为宿主地址。
宿主网络有一个特别的路由器,称为宿主代理。当移动节点附着到一个外部网络时,它会收到一临时需要的地址,其他结点可以发送网络包给这个地址。这个临时地址通告给宿主代理,它随后就可以转发送给移动节点的网络包到这个临时地址。
在分布式服务器的情况下,给集群分配一个唯一的联系地址(服务器生命周期内和外界通信的地址),任何时候分布式服务器都有一节点作为联系地址的访问点,这个角色可以容易被另一结点取代。访问点在分布式服务器所在网络的宿主代理注册自己的地址为临时地址。这是所有的网络包都会导向访问点,他然后分配请求给当前参与分布式服务器的结点。若访问点失效,一个简单容错机制启动,另一个访问点会选出并注册一个新的临时地址。
这个配置会使得宿主代理和访问点称为瓶颈,因为这样所有的流量都要流经这两台机器,可以使用MIPv6的路径优化(见下图):
- 客户知道服务器的地址是HA,把请求传给HA;
- 服务器的宿主代理把请求转发给当前临时地址CA;
- 宿主代理转发CA给客户;
- 客户把(HA,CA)存储在本地,之后通信直接送给CA。
代码迁移
代码迁移会带来与本地资源使用相关的问题,因为迁移时要求资源同时迁移,并且在目标机器上重新绑定到本地资源,或者使用系统范围的网络引用。
另一个问题是,在迁移代码时要考虑异构性。可以使用虚拟机来处理异构性。
代码迁移模型
进程包含如下三段:
- 代码段,包含构成正在运行的程序的所有指令;
- 资源段,包含指向进程需要的外部资源(文件、打印机、设备等)的指针;
- 执行段,用来存储进程的当期那执行状态量(包括私有数据、栈、程序计数器等)。
弱可移动性:
只传输代码段以及某些初始化数据。传输过来的程序总是从预先定义的几个位置之一开始执行。
强可移动性:
可以先停止运行中的进程,然后将它移到另一台机器上去,再从刚才中断的位置继续执行。

Chapter 4 通信 - Communication
进程间通信 - Interprocess Communication
进程间通信是每个分布式系统的核心。
但是,不同机器的进程想相互交流是很困难的。 😭
解决方案:
目前主要有四种方法用于进程间通信 - IPC models:
- RPC
- RMI
- MOM
- Streams
分层协议 - Layered Protocols
分层协议可以解决通信的问题
两大类协议
面向连接
消息发送与接收双方需要先建立连接,再传输数据;
面向无连接
直接传数据
中间件协议
中间件是一种应用程序,逻辑上位于应用层中。
- 中间件通信协议支持高层通信服务;
- 对实时数据传输进行设定并使其保持同步的协议;
- 还提供可靠的多播服务。
⚡️远程过程调用 - Remote Procedure Call
RPC就是一个机器调用位于其他机器上的进程。
A机器的进程调用B机器的进程:
- A将本地调用进程挂起;
- A通过参数将信息传递给B;
- B执行被调用进程;
- B执行结束将信息传回给A。
一般说的RPC就是同步RPC,如上面的流程所示,机器A的调用进程:
- 无需保护现场;
- 在结果返回之前会阻塞的。
基本的RPC操作 - Basic RPC Operation
RPC操作背后隐含的思想是尽量是远程过程调用具有与本地调用相同的形式。
将客户过程对客户存根发出的本地调用转换成对服务器过程的本地调用,而客户和服务器都不会意识到有中间步骤的存在。
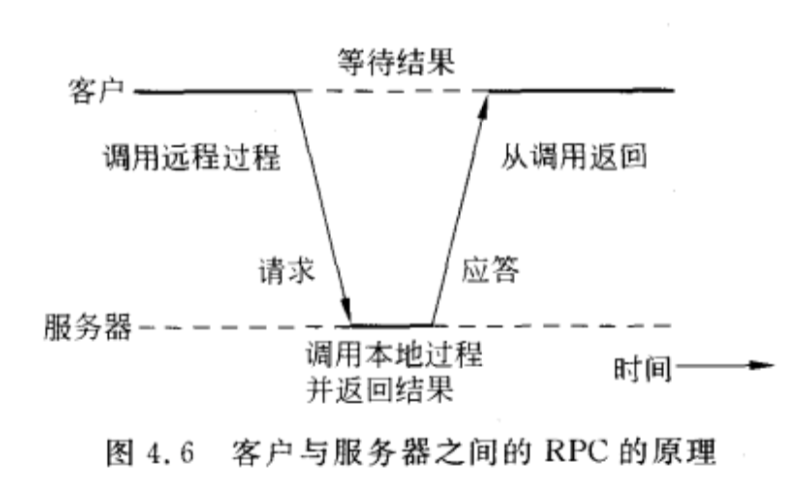
使用socket进行通信,把socket通信隐藏到底层,从而实现透明性。
RPC的步骤:
总结一下就是:
发送:
客户过程 -> 客户存根 -> 客户操作系统 -> 服务器操作系统 -> 服务器存根 -> 服务器进程
返回:从右向左就是了。
具体:
- 客户过程以正常的方式调用客户存根;
- 客户存根生成一个消息,然后调用本地操作系统;
- 客户端操作系统将消息发送给远程操作系统;
- 远程操作系统将消息交给服务器存根;
- 服务器存根将参数提取出来,然后调用服务器;
- 服务器执行要求的操作,操作完成后将结果返回给服务器存根;
- 服务器存根将结果打包成一个消息,然后调用本地操作系统;
- 服务器操作系统将含有结果的消息发送回客户端操作系统;
- 客户端操作系统将消息交给客户存根;
- 客户存根将结果从消息中提取出来,返回给调用他的客户过程。
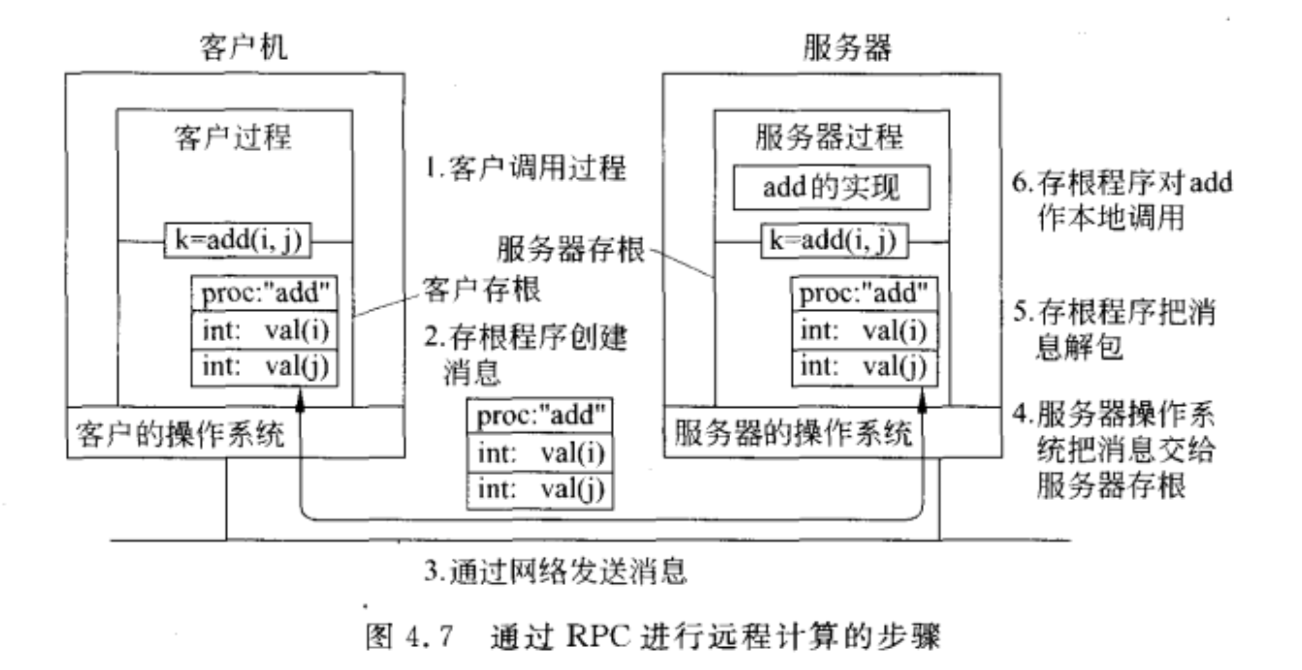
参数传递 - Parameter Passing
完整定义了RPC协议后,需要实现客户存根和服务器存根,不同点仅仅在于面向应用程序的接口。
接口通常使用IDL(接口定义语言),用IDL说明的接口可以与适当的编译时接口或者运行时接口一起编译到客户存根过程和服务器存根中。
异步RPC - Variations
异步RPC中:
- 客户发出RPC请求,接受到服务器的确认信息后,不会阻塞,继续向下执行;
- 服务器在接受到RPC请求后立即向客户送回应答,之后再调用客户请求的过程。
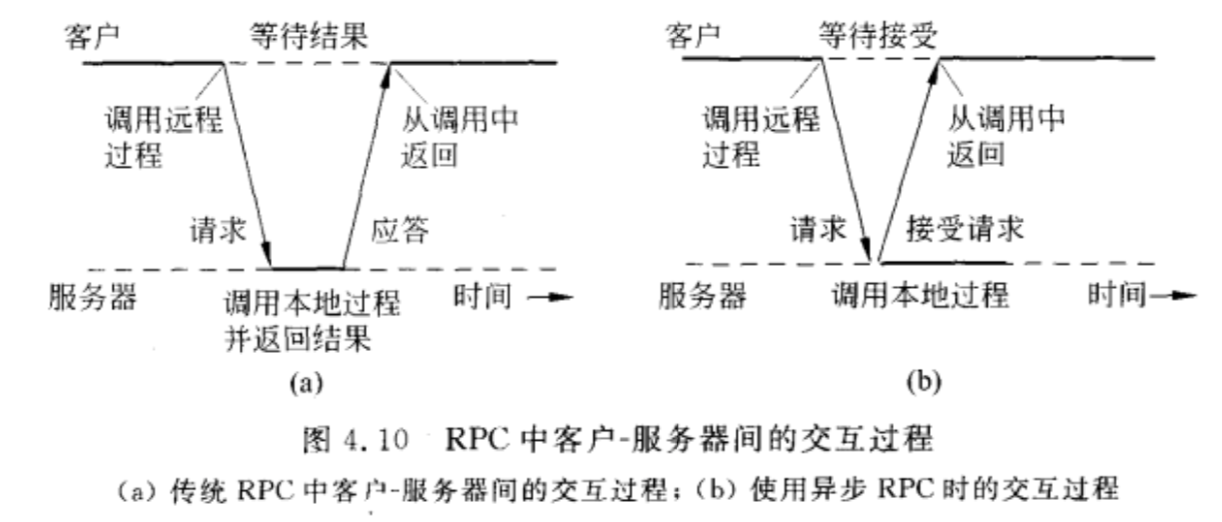
异步RPC效率高,但是难编程。
延迟的同步RPC:
就是两个异步RPC结合起来。
远程服务器在处理请求时,客户同时做一些其他的事情。当服务器处理好请求时,返回结果去中断客户,服务器一端变成发送端,实现第二个异步RPC。
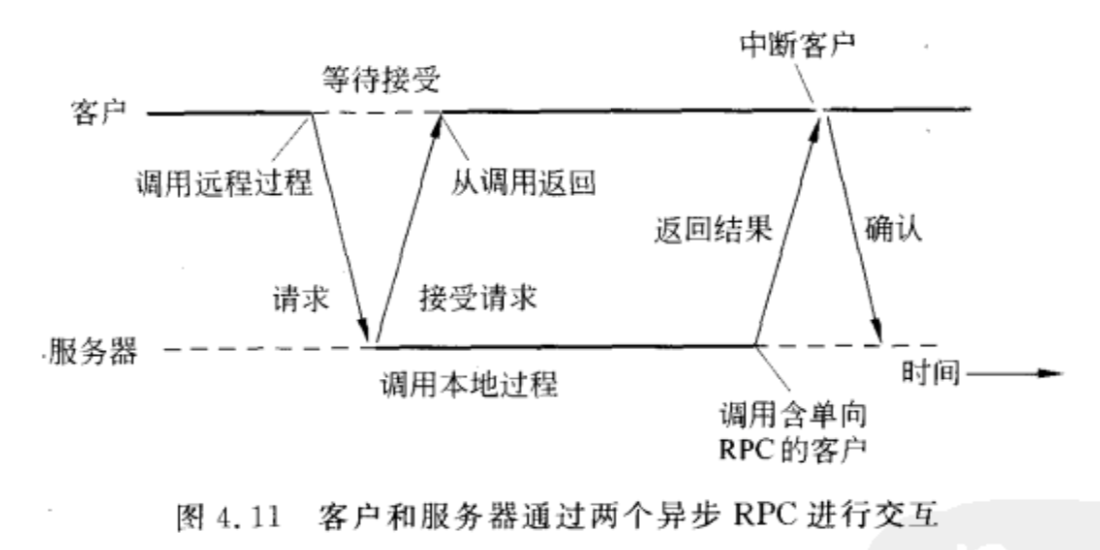
面向消息的通信 - Message-oriented Communication
套接字
一种通信端点。如果应用程序要通过底层网络发送某些数据,可以把这些数据写入套接字,然后从套接字读出数据。
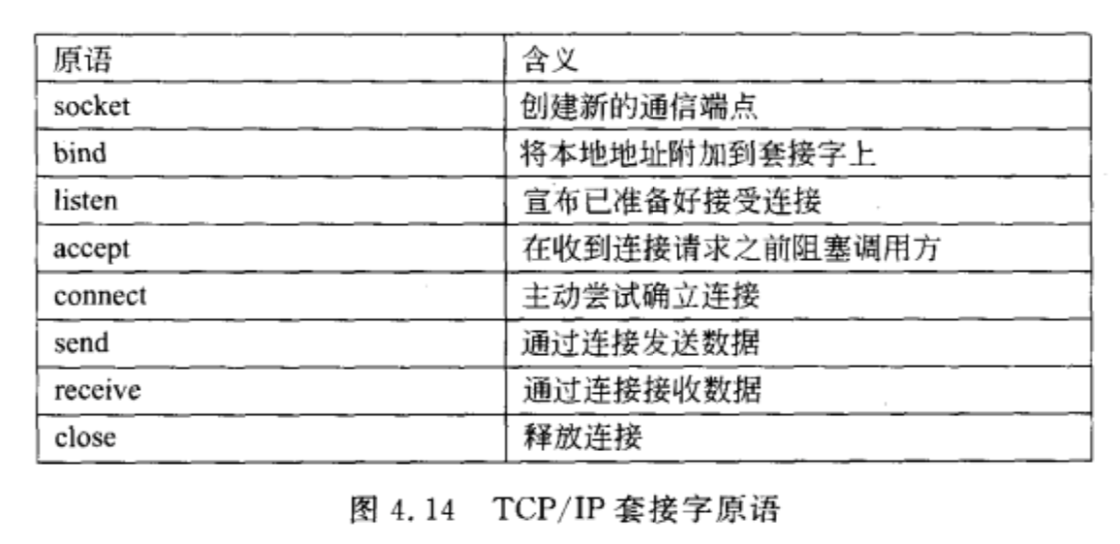
服务器一般执行前4个原语,一般按照图中顺序执行。调用套接字原语的时候,调用者创建一个新的通信端点,用于某种特定的传输协议的。
消息传递接口 MPI
MPI的先进之处:
程序的硬件独立性需要导致MPI的出台。MPI是为并行应用程序设计的,是为瞬时通信量身定做的。它直接使用的是底层网络。
MPI是并行计算,一般运行于集群中。

消息队列系统
面向消息的中间件服务。为持久异步通信提供多种支持。本质是,提供消息的中介存储能力,这样就不需要消息发送方和接收方在消息传输中都保持激活状态。与套接字和MPI的重要区别在于,它的设计目标一般是支持那些时间要求较为宽松的消息传输,不适合几秒甚至几微秒内要完成的传输。
⚡️面向流的通信 - Stream-oriented Communication
流的定义
A (continuous) data stream is a connection oriented communication facility that supports isochronous data transmission
简单流:
只包含单个数据序列;
复杂流:
简单流的组合
传输模式
异步传输模式:
流中的数据项是逐个传输的,但是对某一项在何时进行传输并没有进一步的限制。这是采用离散数据流时常见的情况。比如文件的传输。
同步传输模式:
数据流中每一个单元都定义了一个端到端的最大延迟时间,容许延迟。数据单元的传输时间是否远远小于最大允许延迟并不重要。
等时传输模式:
数据单元必须按时传输,端到端的延迟时间同时又上限和下限。这个上、下限也称为边界延迟抖动。在视频和音频方面很常用,比如音视频的同步(对口型)。
流媒体就属于这个类,既有最大端到端延迟限制,又有最小的端到端延迟限制。
流与服务质量
QoS服务质量:
- 数据传输所要求的比特率;
- 创建会话的最大延时(比如应用程序何时可以开始发送数据);
- 端到端的最大延时;
- 最大延时抖动;
- 最大往返延时。
QoS保证:
使用 buffer 来减少 jitter
当数据包有不同的延时,接收方先把它们存储在缓冲区,当总是有足够的数据包进入缓冲区时,接收方就可以以固定的速率把数据包传递给应用程序。
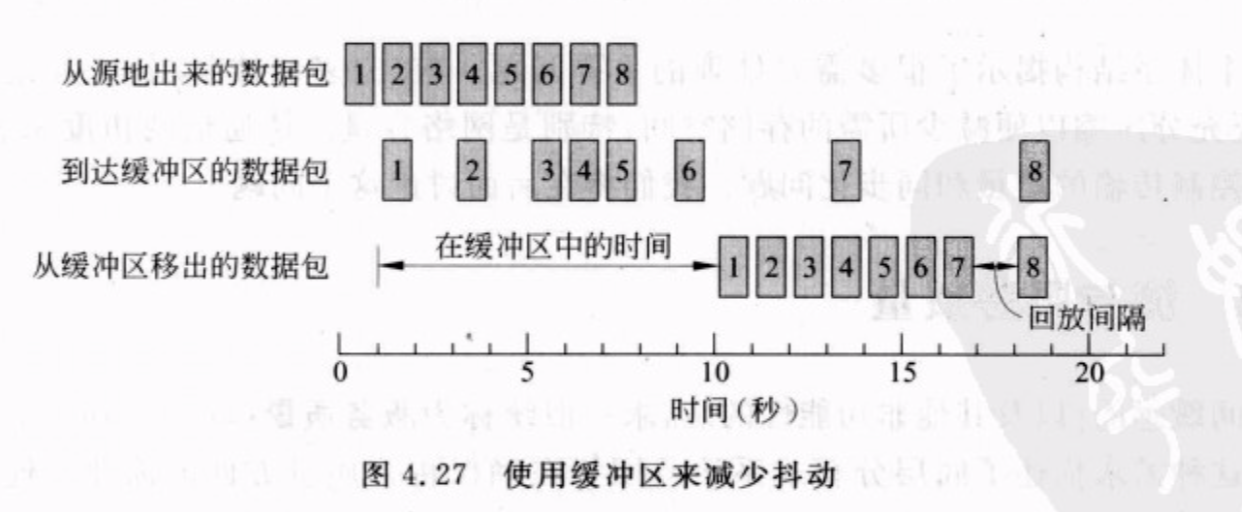
针对丢包情况,interleaving,若没有交错机制,丢包时会把连续的几帧一起丢掉,视觉影响较大;而使用交错机制,会交叉丢包。
如在传送音视频时,采用交错传输,丢失的帧分布较广,这样丢失的就不是一大段而是零散的帧,对于音视频的播放影响就较小。但是这样需要更大的缓冲区,因此程序的开始延时更高。
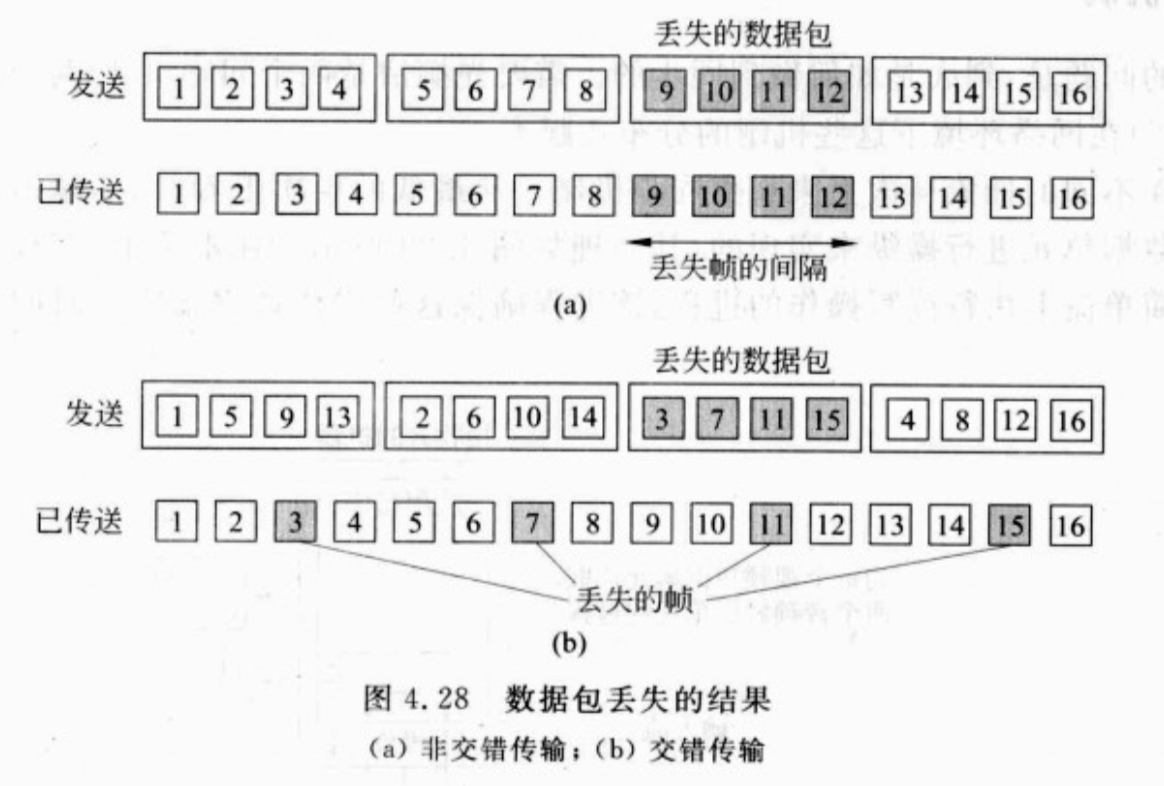
流同步
音视频流同步
采用音视频的编解码协议:H264协议
多播通信 - Communication
Gossip-Based Data Dissemination
属于p2p系统的多播。
应用在自主网或是p2p,就是没有服务器的那一类网。
几种多播
全序多播 Total order
FIFO多播
通信层被强制按照消息发送的顺序传送来自同一进程的消息,对不同进程之间的顺序不作要求。
例:

不保证m1和m3之间的顺序,所以对于P2和P3,只要m1在m2之前,m3在m4之前,就算满足要求。
Causal 因果序多播
Chapter 5 命名系统 - Naming
命名是在分布式中表示这个实体,且要访问到这个实体。
- 访问点:用来实体的一种特殊实体。
- 地址:访问点的名称。
所以访问点就是实体的地址。
⚡️⚡️DHT
全称是Distributed Hash Tables,是P2P环境下最经典的解决方案
Chord
使用一个m位的标识符空间,把随机选择的标识符赋给结点,并把键值赋值给特定实体(任意的东西,比如文件、进程)。
构造Finger table算法:
每个Chord结点维护一个最多有m个实体的指状表(Finger table),如果用\(FT_p\)表示结点\(p\)的指状表,那么有: \[ FT_p[i]=succ(p+2^{i-1}) \] - \(p\)是当前结点 - \(i\)是指状表的index - \(succ(k)\)表示k(若结点k存在)或k的下一个存在的结点,即\(succ(k) \geq k\)
例:
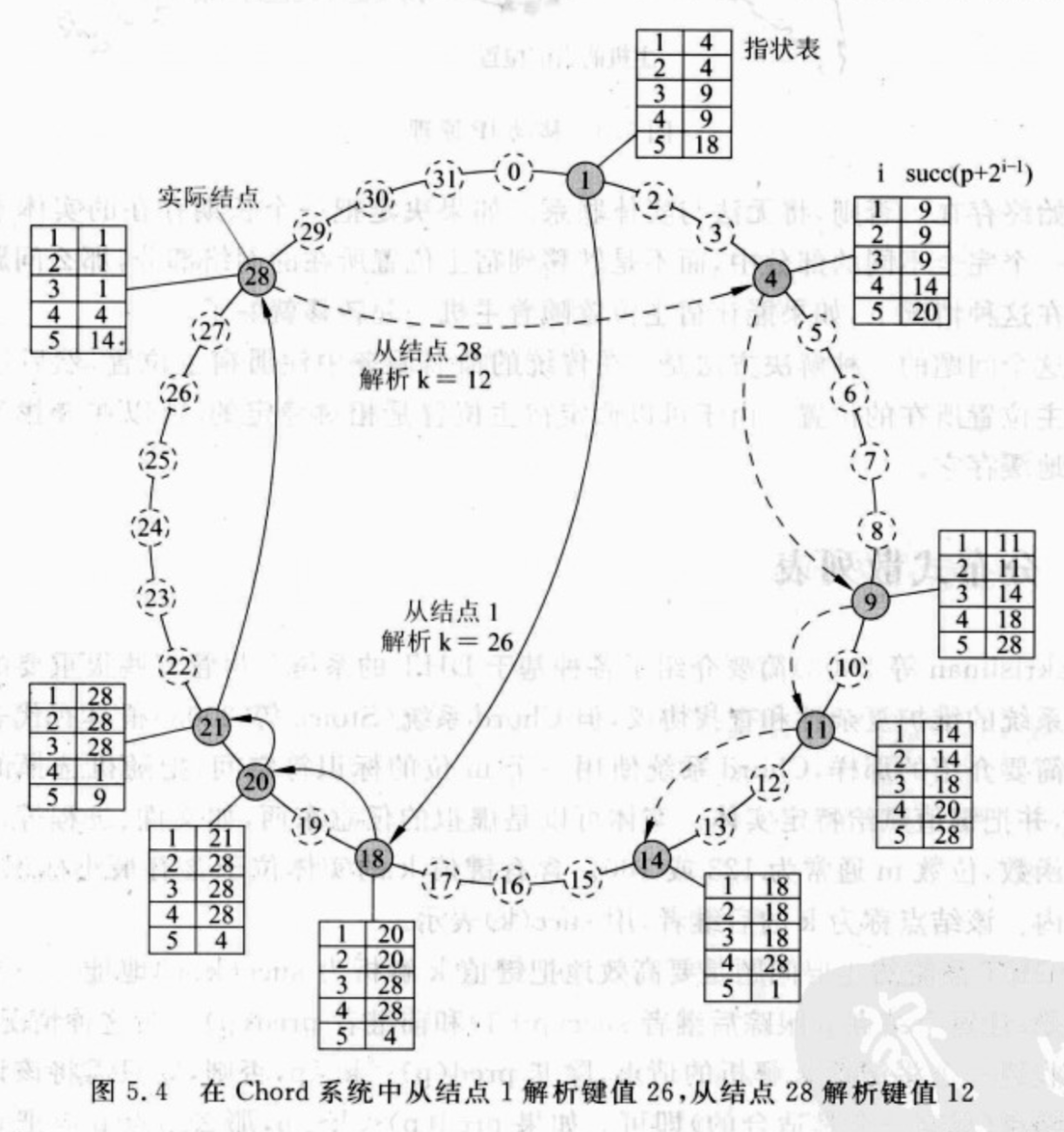
根据\(FT_p[i]=succ(p+2^{i-1})\)公式,构造结点p=4的Finger table:
| \(i\) | \(FT_p[i]\) |
|---|---|
| 1 | \(succ(4+1)=9\) |
| 2 | \(succ(4+2)=9\) |
| 3 | \(succ(4+4)=9\) |
| 4 | \(succ(4+8)=14\) |
| 5 | \(succ(4+16)=20\) |
解析算法:
目标:从节点p开始解析key=k的结点
搜索节点p的Finger table,从上依次向下搜索,如果一个结点q满足: \[ q=FT_p[j] \leq k < FT_p[j+1] \] 那么就将该请求转发给结点q;
如果p的Finger table第一个结点就比k还大,即: \[ p < k < FT_p[1] \] 那么就转发给\(FT_p[1]\)结点,此节点负责结点k,将k的地址返回给结点p。
例:
还是上面那个图
从结点1开始解析k=26:
- 结点1的指状表里,\(FT_1[5]=18 \leq 26\),将请求转发给18;
- 结点18的指状表里,\(FT_{18}[2]=20 \leq 26 < FT_{18}[3]=28\),将请求转发给20;
- 结点20的指状表里,\(FT_{20}[1]=21 \leq 26 < FT_{20}[2]=28\),将请求转发给21;
- 结点21的指状表里,\(21 < 26 < FT_{21}[1]=28\),将请求转发给28,该结点负责解析k=26;
从结点28开始解析k=12:
- 结点28的指状表里,\(FT_{28}[4]=4 \leq 12 < FT_{28}[5]=14\),将请求转发给4;
- 结点4的指状表里,\(FT_{4}[3]=9 \leq 12 < FT_{4}[4]=14\),将请求转发给9;
- 结点9的指状表里,\(FT_{9}[2]=11 \leq 12 < FT_{9}[3]=14\),将请求转发给11;
- 结点11的指状表里,\(11 < 12 < FT_{11}[1]=14\),将请求转发给14,该结点负责解析k=12;
⚡️⚡️HLS
网络被划分为一组域。每个域D都有关联的目录节点dir(D),dir(D)会跟踪域中的实体,形成一颗目录结点树。
HLS结构
看下面这个图来解释一下HLS吧:
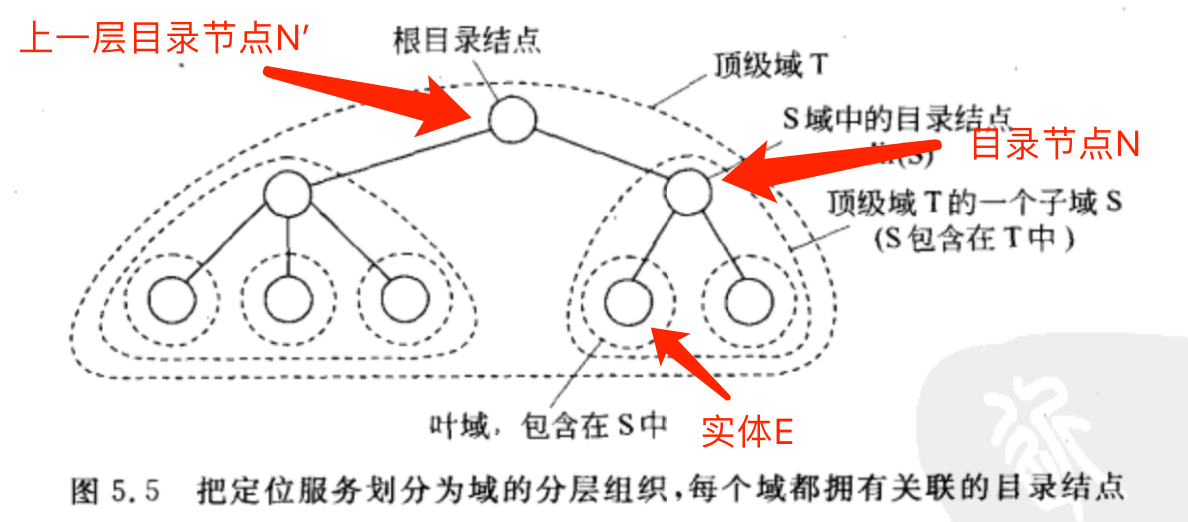
为了跟踪实体E的位置,实体E位于域S中,所以域S的目录结点N含有E在该域中的位置信息。
而在比域S更高一级的域T中,域T的目录结点N'也有实体E的位置信息,但是这个位置信息只有N的指针,也就是要找实体E,就先去找到其子域的目录结点N,然后通过目录节点N找到E。
同理,在比域T更大的域中,那个域的目录节点也有实体E的位置信息,不过这个位置信息只有N'的指针,要找实体E,就要先找N',然后找到N,最后找到E。
所以顶级域的目录结点,即根(目录)节点,包括全部实体位置信息。
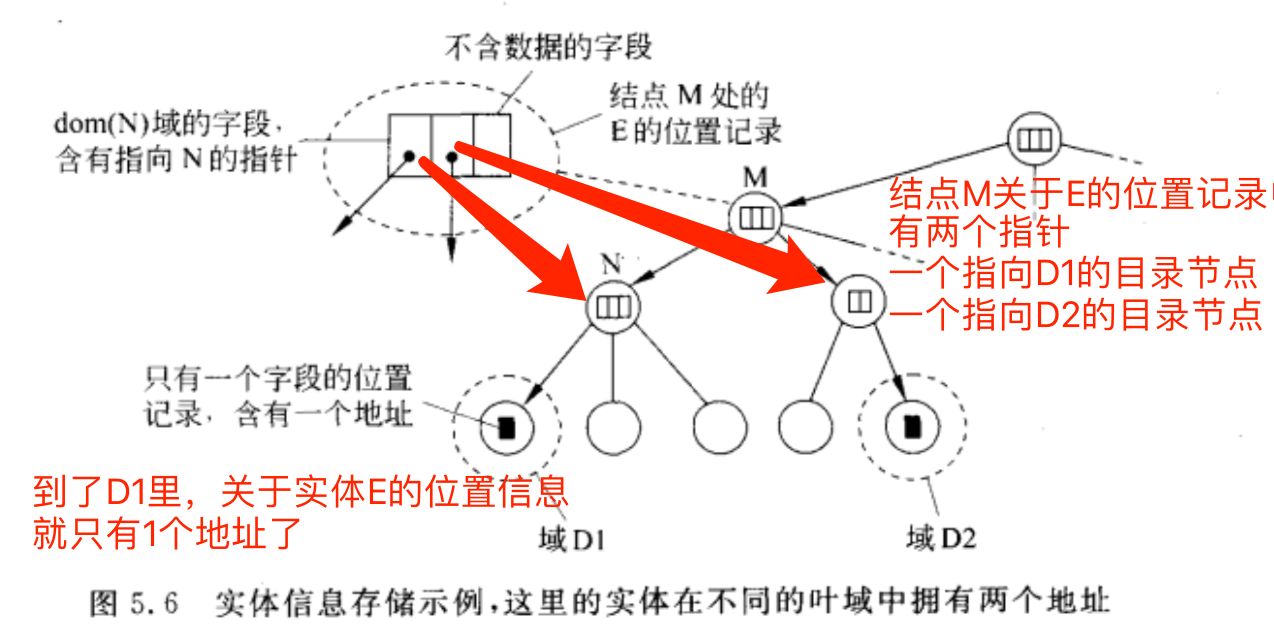
如果一个实体有多个地址
实体可以拥有多个地址,比如被复制了,实体在域D1和域D2中都有地址,那么同时包含D1和D2的最小域目录结点将有两个指针,每个指针都指向一个包含地址的子域。
HLS查询操作
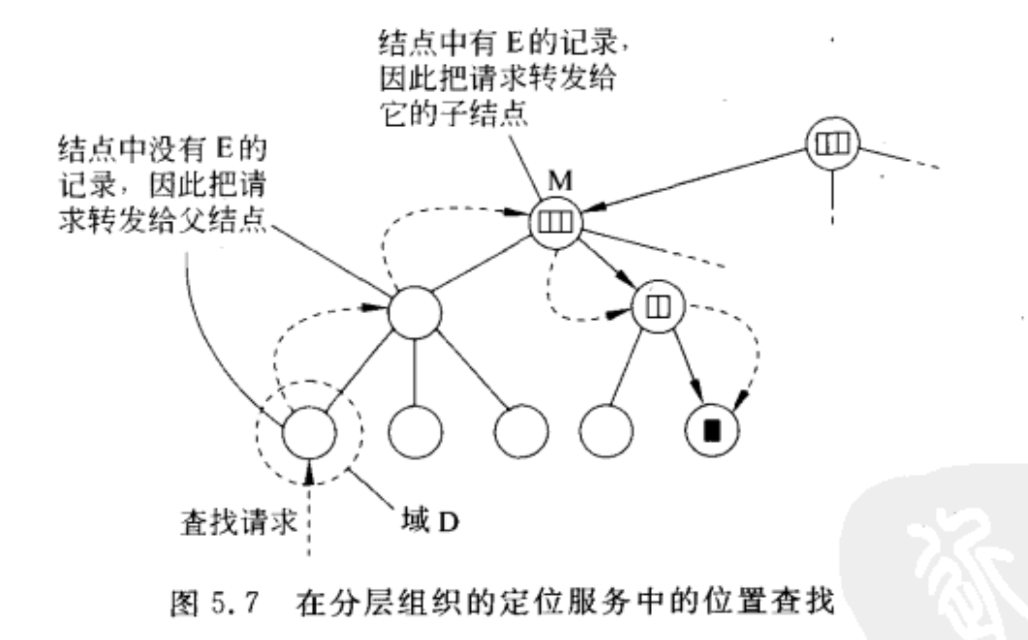
现在希望能定位实体E的位置信息,那么就向当前域的目录结点发送查找请求:
1 | if 目录结点找到了实体E的位置信息: |
最差情况是一直找不到,向上转发直到根节点。
插入操作
这块不要看中文教材!因为教材把图用错了!(真的坑)

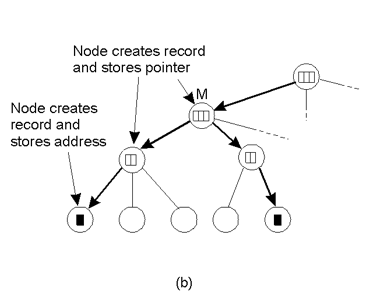
如果要插入实体E,将其所在域的目录节点加入实体E的地址,然后一路向上转发。
如果这个目录结点不知道E,就存储一下子域地址,直到一个节点知道E的位置或者到根节点就终止。
为啥刚刚插入的实体E,可能有的结点已经知道E的位置了呢?
因为E可能是复制过来的,正如上面讲的有多个实体,包含两个E的最小域的目录节点会有E的两个地址,而再往上一层,就只有E的一个地址了(指向两个E的最小域的目录节点),到这里就停止向上传递。

这是中文教材的配图,怎么都看不懂这两条线啥意思,原来中文教材用成查询的图了。
(:3」∠)
HLS思想
若用root node实现扁平化直接管理,根节点负载过大,且一旦崩溃,整个集群系统瘫痪。因此,使用分治思想,不同dom内实现自治。
名称空间的实现 - Name Space Implementation
Basic issue
Distribute the name resolution process as well as name space management across multiple machines, by distributing nodes of the naming graph.
Consider a hierarchical naming graph and distinguish three levels:
- Global level: Consists of the high-level directory nodes. Main aspect is that these directory nodes have to be jointly managed by different administrations
- Administrational level: Contains mid-level directory nodes that can be grouped in such a way that each group can be assigned to a separate administration.
- Managerial level: Consists of low-level directory nodes within a single administration. Main issue is effectively mapping directory nodes to local name servers.
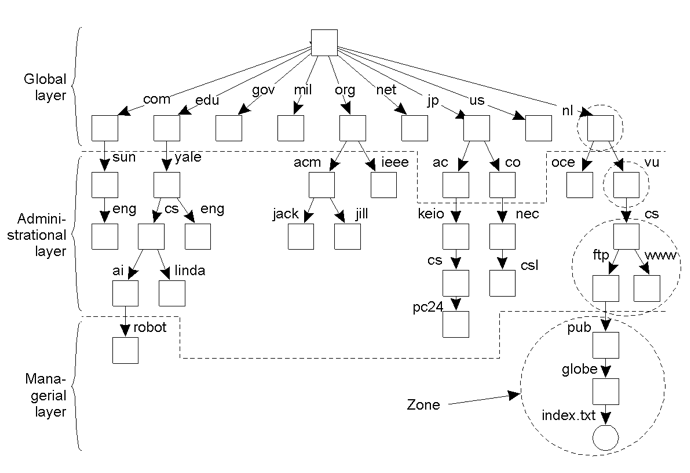
从上至下依次分为了Global level, Administrational level and Managerial level。
Global层几乎不怎么变化,Administrational层变化多些,Managerial层变化最多。
具体区别看下面这个表:
| Item | Global | Administrational | Managerial |
|---|---|---|---|
| Geographical scale of network | Worldwide | Organization | Department |
| Total number of nodes | Few | Many | Vast numbers |
| Responsiveness to lookups | Seconds | Milliseconds | Immediate |
| Update propagation | Lazy | Immediate | Immediate |
| Number of replicas | Many | None or few | None |
| Is client-side caching applied? | Yes | Yes | Sometimes |
名称解析 - Name Resolution
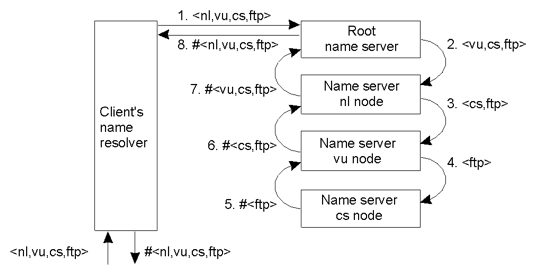
迭代名称解析 - Iterative Name Resolution
- resolve(dir,[name1,...,nameK]) is sent to Server0 responsible for dir
- Server0 resolves resolve(dir,name1) → dir1, returning the identification (address) of Server1, which stores dir1.
- Client sends resolve(dir1,[name2,...,nameK]) to Server1, etc.

递归名称解析 - Recursive Name Resolution
- resolve(dir,[name1,...,nameK]) is sent to Server0 responsible for dir
- Server0 resolves resolve(dir,name1) →dir1, and sends resolve(dir1,[name2,...,nameK]) to Server1, which stores dir1.
- Server0 waits for the result from Server1, and returns it to the client.
Scalability Issues
Issue 1
因为名称解析都需要先解析高级域名,所以高层服务器的需要每秒处理大量处理请求。
Solution:
因为在global层和administrational层的结点内容几乎不会变,所有我们可以把这些服务器的内容广泛地复制到多个服务器中,这样名称解析可以就近处理,加快速度,如果找不到再发请求到高层服务器。
Issue 2
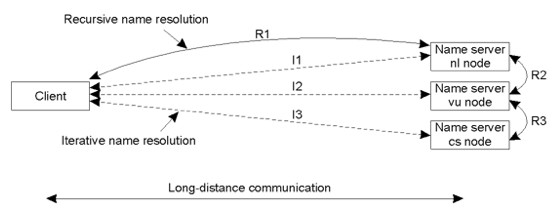
Geographical scalability - 地域可扩展性,即名称解析服务要可以在很大的地理距离内进行扩展。
如果客户和服务器端离的比较远,那么最好采用递归名称解析,因为客户端只和服务器通信一次即可取得结果,而迭代名称解析需要通信多次。
Chapter 6 同步化 - Synchronization
时钟同步 - Clock Synchronization
Berkeley算法
Berkeley UNIX系统的时间服务器(实际上是时间守护程序)是主动的,定期询问每台机器的时间。然后算出一个平均时间,并告诉所有其他机器将它们的时钟拨快/拨慢一个新的时间。
Berkeley算法除了第一次传播时间守护程序的广播外,传播的都是相对时间,如下图的b和c,目的是为了减小误差。
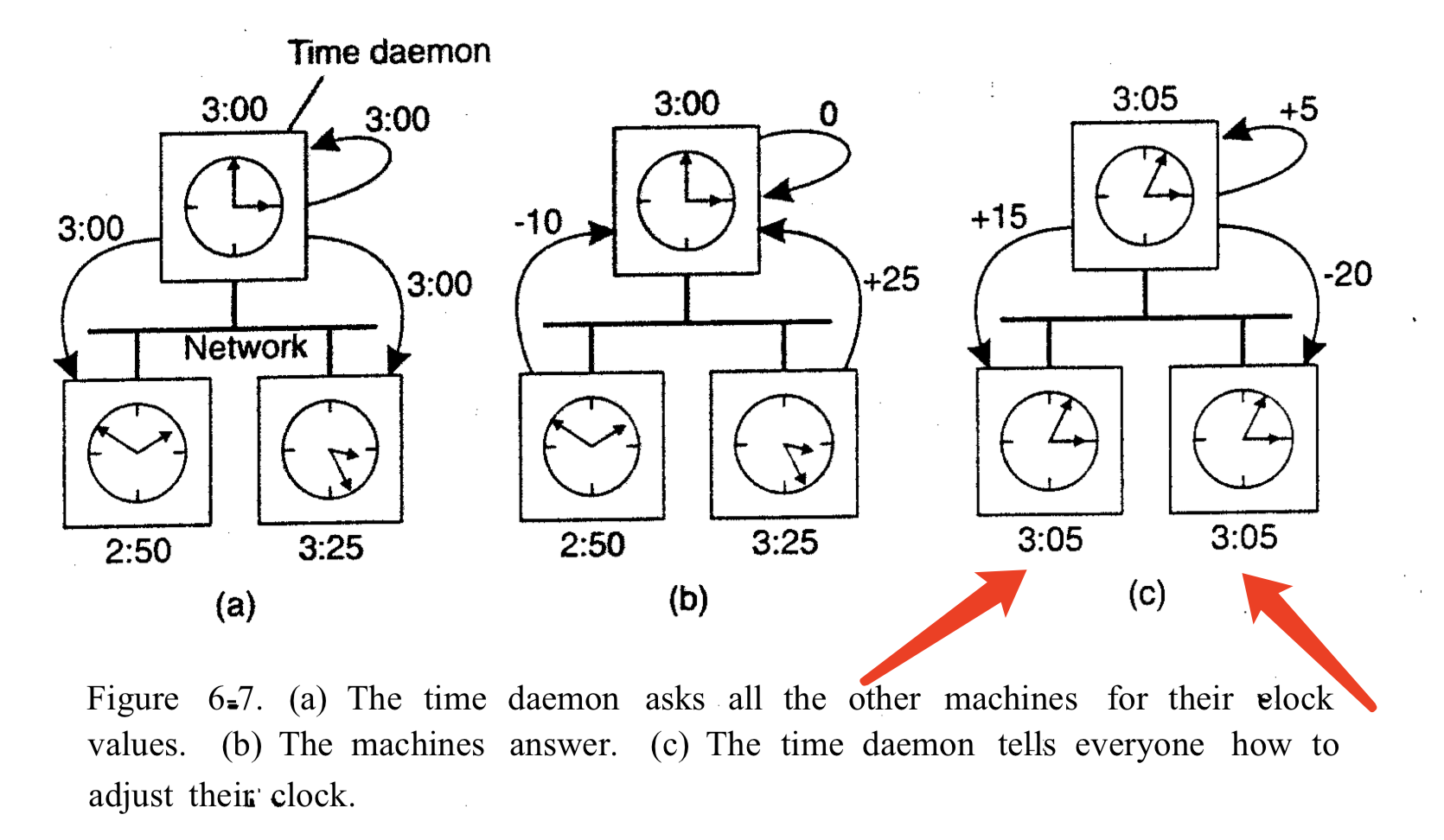
感谢王海杰同学发现并提醒我中文书这里时间写错了。
⚡️⚡️逻辑时钟 - Logical clocks
⚡️⚡️Lamport逻辑时钟
先发生关系 - Happen-Before (HB) Relation
表达式:a→b读作"a在b之前发生",意思是所有进程一直认为事件a先发生,然后事件b才发生。
HB关系准则:
If \(\exists process \ p_i\) : a comes before b, then a→b
如果a和b是同一进程中的两个事件,且a在b之前发生,则a→b为真
For any message m, send(m) → receive(m)
如果a是一个进程中发送消息的事件,b是另一个进程中接受这个消息的事件,那么a→b为真
IF a, b and c are events such that, a → b and b → c, then a → c
如果a→b,b→c,那么a→c
Problem:
How do we maintain a global view on the system’s behavior that is consistent with the happened before relation?
如何使用HB Relation来维持系统时间一致?
Solution: attach a timestamp \(C(e)\) to each event e, satisfying the following properties:
对于每个事件a,我们都能为它分配一个所有进程都认可的时间值\(C(a)\)
If a and b are two events in the same process, and a→b, then we demand that \(C(a) < C(b)\).
如果a比b先,那么应该是\(C(a) < C(b)\).
If a corresponds to sending a message m, and b to the receipt of that message, then also C(a) < C(b).
若a是发送的,b是接受的,那么应该是\(C(a) < C(b)\).
若上述两条最后出现了\(C(a) \geq C(b)\),那么执行操作\(C(b) = C(a) +1\),使得\(C(a) < C(b)\).

m3是从P3发送给P2,发送时间是P3的60,接受时间是P2的56,这不符合发送时间<接收时间,所以把接受时间改为发送时间+1,即61。m4同理。
注意:调整时钟操作发生在中间件层。
全序多播
所谓的全序,就是所有进程统一顺序,只要最后所有进程的事件执行顺序相同就行。
- 进程先给消息打上一个当前逻辑时间作为时间戳,然后把这个消息放进自己的本地队列中,再将这个消息发送给其他进程;
- 进程收到来自其他进程的消息后,也把这个消息放进本地队列中,按时间戳排序。
例:
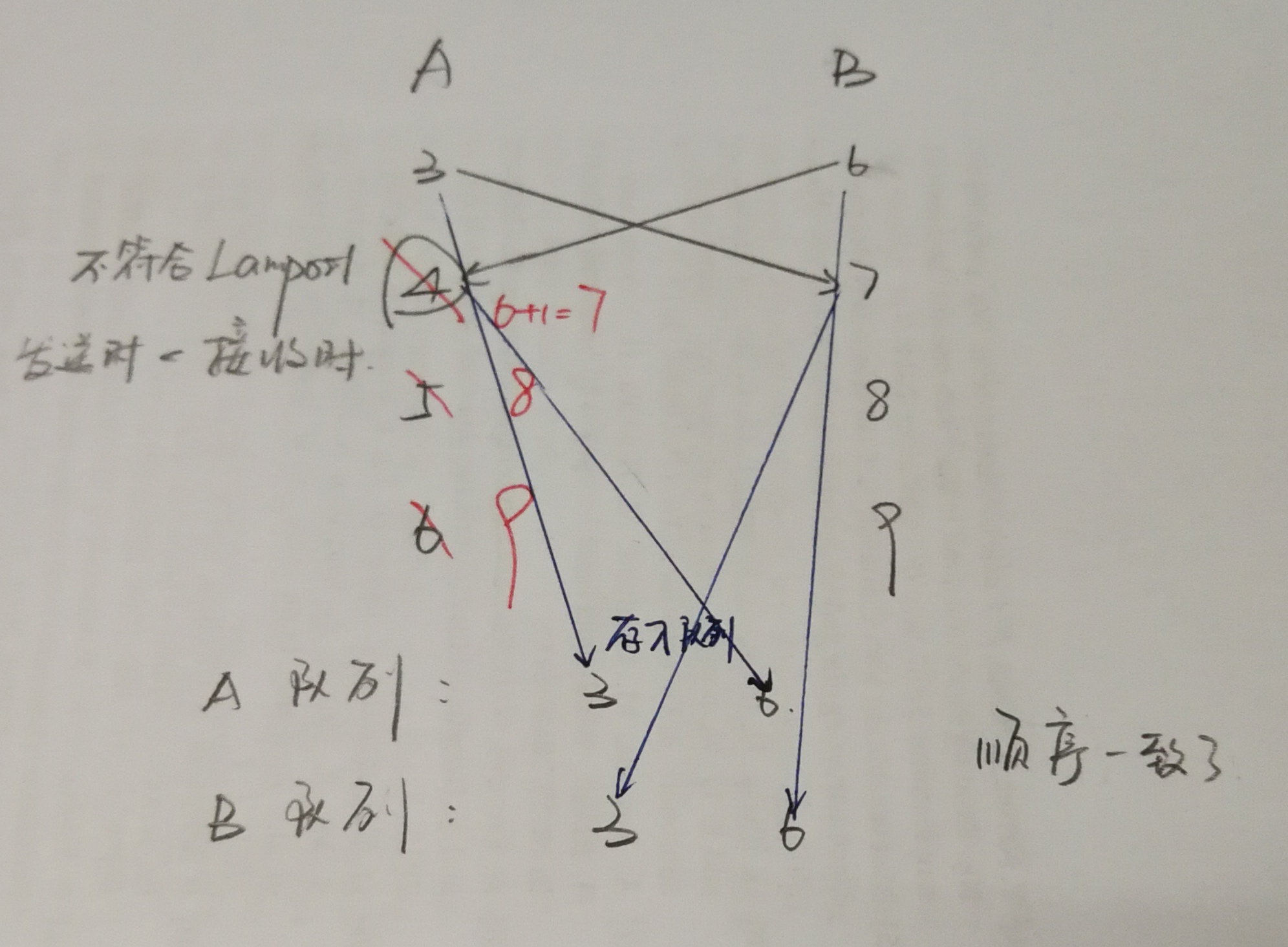
A和B的时间不同,A在本地时间3发出消息,B在本地时间6发出消息。
最后双方的本地队列的顺序都是先执行A的消息,再执行B的消息。
但是这样永远是时间快的进程先执行,时间慢的后执行,所以B发送给A的时候,要使用Lamport逻辑时钟准则调整A的时钟。
全序多播开销很大!
字丑勿见怪
向量时钟
但是向量时钟可以捕获因果关系。
每个进程都维护一个向量\(VC\),比如进程\(P_i\)维护的向量就是\(VC_i\),有两个性质:
- \(VC_i[i]\)表示目前为止,本进程\(P_i\)发生了多少事件;
- \(VC_i[j]=k\)表示进程\(P_i\)知道\(P_j\)已经发生了k个事件。
执行步骤:
- \(P_i\)进程执行一个事件之前,先把自身的向量里第i个分量(也就是\(VC_i[i]\))自增1;
- \(P_i\)进程发送一个消息m给\(P_j\)时,把m的时间戳ts(m)设置为等于\(VC_i\);
- 接受消息m时,进程\(P_j\)通过为每个k设置\(VC_j[k] = \max(VC_j[k], ts(m)[k])\)来调整自己的向量。然后,\(P_j\)要执行这个事件,如步骤1所示,把\(VC_j[i]\)自增1.
强制因果序多播
设计思想:
我懂的不能比你少,不然万一有其他消息还没来,你的消息就插队了,所以我不能收你的消息。
具体操作:
进程\(P_i\)发给进程\(P_j\)一个时间戳为\(ts(m)\)的消息m。如果不满足以下两个条件,这个消息就不交付给应用层,直到满足条件为止:
- \(ts(m)[i] = VC_j[i]+1\)
- \(ts(m)[k] \leq VC_j[k] \quad for \ all \ k \neq i\)
关于你刚刚发的消息,可以比我多知道一条消息。毕竟他发的,肯定比我多了解一条;
但是关于其他消息,你知道的不可以比我多,不然我就是还有其他消息没收到,等我收到其他消息后再处理这个消息。
这本中文书你还能再坑一点吗?
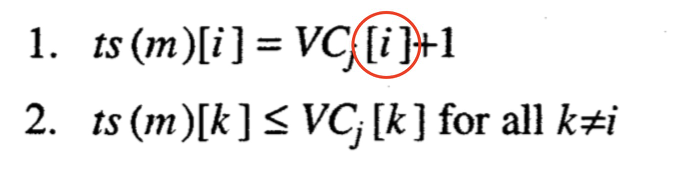
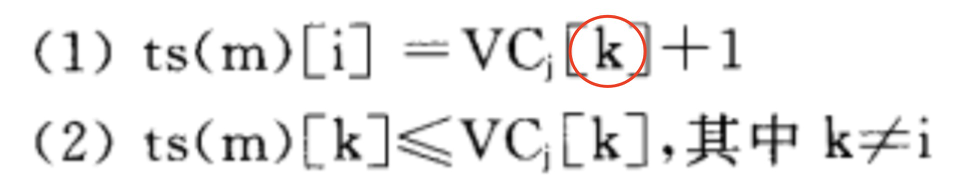
例:
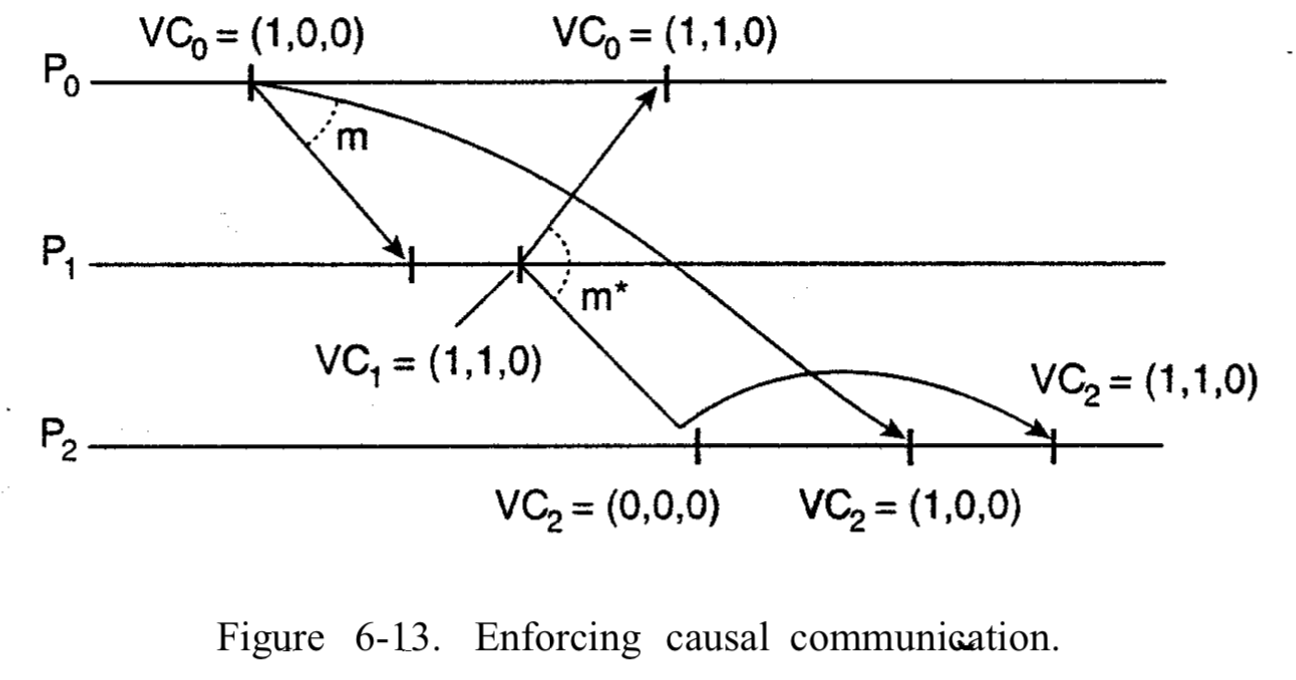
- \(P_0\)先发送消息m,自身先把\(VC_0[0]\)自增1,消息的时间戳为(1, 0, 0);
- \(P_1\)收到消息m,当时\(P_1\)的向量是(0, 0, 0),只有第一维比自己多1个,其他都和自己相同,所以满足上述条件,消息交付应用层;
- \(P_1\)发送消息m*,自身先把\(VC_1[1]\)自增1,消息的时间戳为(1, 1, 0), \(P_0\)接收此消息;
- \(P_2\)不接收\(P_1\)发送的消息,因为此时\(P_2\)的向量是(0, 0, 0),\(P_0\)的消息还没收到,所以延迟接受\(P_1\)的消息;
- 等到\(P_0\)的消息到来,\(P_2\)调整过自身的向量后,才可以接收\(P_1\)的消息。
例2:
互斥 - Mutual Exclusion
分布式系统情况下,进程将需要同时访问相同的资源,互斥算法就是保证进程之间能够互斥访问资源。
集中式算法
选举一个进程作为协调者。其他进程想访问资源都要问他。
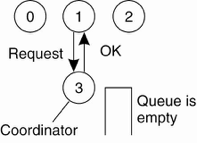
进程3是协调者,进程1想访问资源,问一下进程3,进程3说ok。
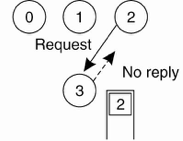
进程2也想访问资源,进程3不理进程2,但是把进程2放到等待队列里。
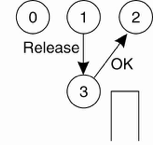
进程1用完资源后,向进程3说一声他用完了。进程3便向等待队列的队首进程说一声,可以用资源了。
非集中式算法
这个Decentralized一点意义都没有!开销大!神经病!书上举这个例子就是说不要什么事都尝试Decentralized。Google云计算的也只是一个协调者,协调者挂了就选举。多协调者没好处,只会扯皮!
——丁箐
分布式算法
当一个进程想要某个资源,就向所有其他进程发送消息询问。比如进程A想要一个资源,就向其他进程发消息询问,进程B就收到了A的消息。
若B不想用这个资源,就给A回一个OK。
“Yes, you can have it. I don’t want it, so what do I care?”
若B已经在用这个资源了,就不理A,但是把A的请求消息放进等待队列中。
“Sorry, I am using it. I will save your request, and give you an OK when I am done with it.”
若B也想用这个资源,但是还没开始用,那么就把A发送来的消息时间戳和自己将要广播消息的时间戳进行比较,谁发的早谁获得资源。这里的一致性是由Lamport逻辑时钟保证的。
竞争失败的进程会给获得资源的进程发个OK,然后把自己放进等待队列里。
If the incoming message has a lower timestamp, the receiver sends back an OK.
“I want it also, but you were first.”
If it’s own message has a lower timestamp, it queues it up.
“Sorry, I want it also, and I was first.”
令牌环算法 - A Token Ring Algorithm
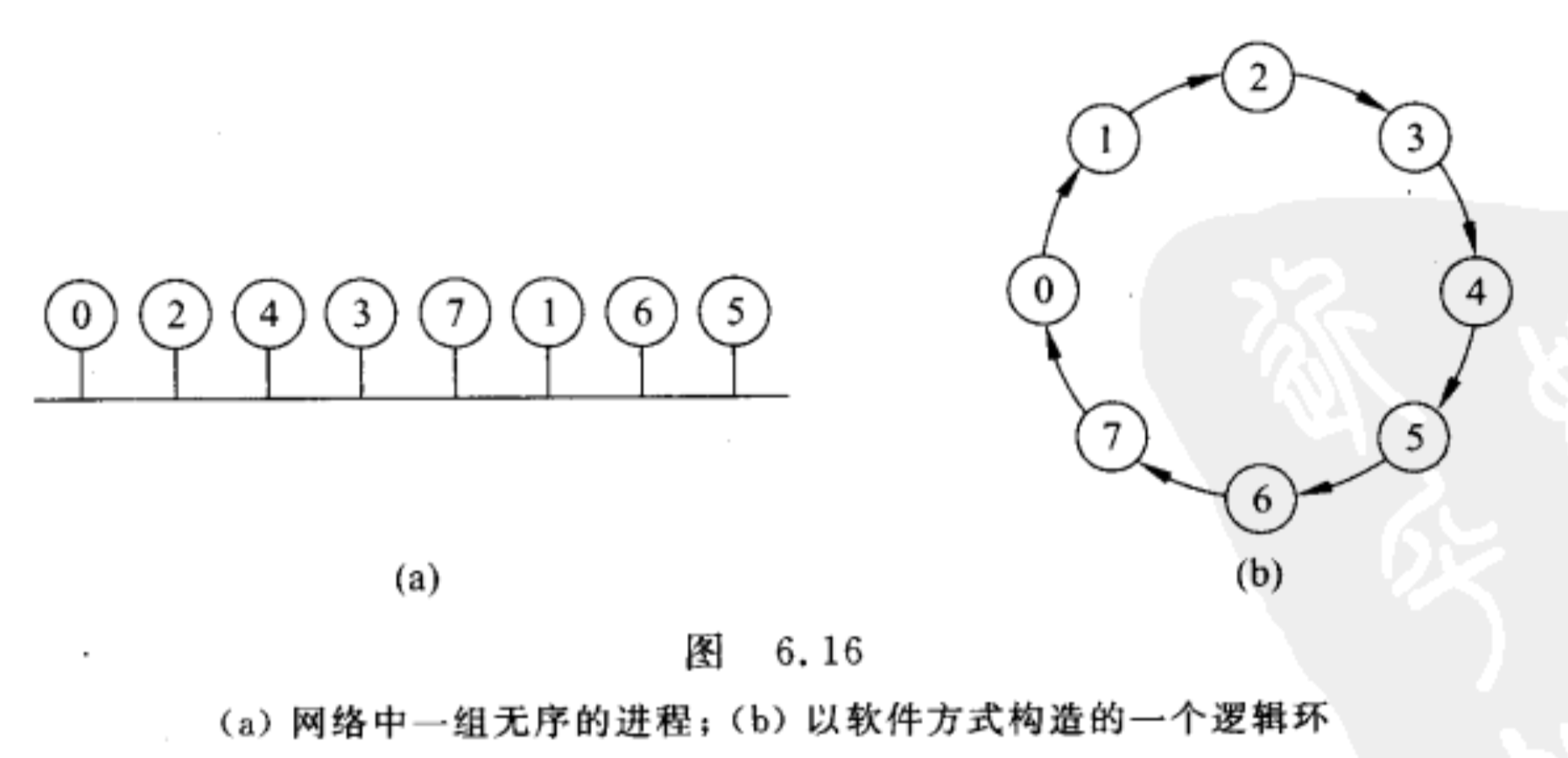
在网络中,环的顺序是无序的,但是可以用软件的方法构造成一个有序的逻辑环。环的顺序和进程在总线上的位置是无关的。
令牌(token)在进程间相互传递,拥有令牌的进程可以访问共享资源,用完就向下传。
如果某个进程收到了令牌但不用访问资源就传下去。
不允许某一个进程用完资源后,使用同一令牌继续访问该资源。
整个分布式系统中只有一个令牌,如果令牌毁了,比如拥有令牌的进程挂掉了,那么就需要重启一个复杂的分布式进程创建新令牌。
⚡️四种算法的比较
四种互斥算法每次进/出需要的消息数以及进入前的延迟(按消息数)


⚡️⚡️选举算法 - Election Algorithms
很多分布式的机子,要选举出一个协调者。
或者协调者崩了,要重选一个协调者。
选举算法就是选一个协调者的算法。
欺负算法 - Bully Algorithm
当任何一个进程发现协调者不再响应请求时,它就发起一次选举
- P向所有编号比它大的进程发送一个ELECTION消息
- 如果无人响应,P获胜并称为协调者
- 如果有编号比它大的进程响应,则由响应者接管选举工作。P的工作完成。
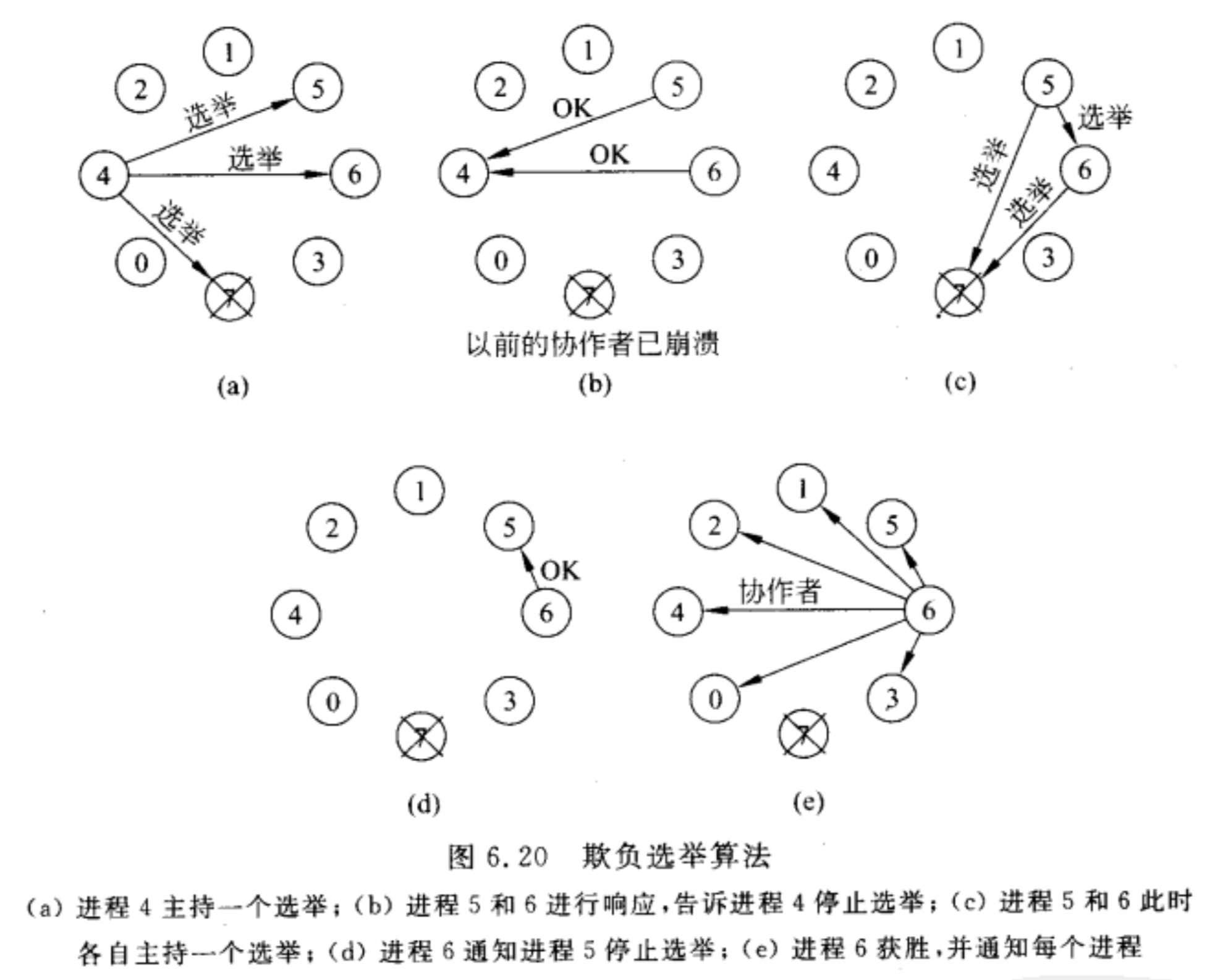
当有ELECTION消息到达时,接收者回送一个OK消息给发送者,表明自己仍在运行,并接管选举工作。最终除了一个进程外,其他进程都将放弃,这个进程就是新的协调者。它将获胜的消息发送给所有进程。
当以前的一个崩溃了的进程恢复过来时,它将主持一次选举。
总结一下:
这个算法就是哪个进程的编号大且没崩盘哪个就是协调者,因为编号小的都要问编号大的,编号大的只要没崩都说接管选举任务。而且崩盘的进程一旦恢复了,就会广播一个COORDINATOR消息,表示大哥回来了,又接管协调者的任务。
环算法 - Election in a Ring
会有2个消息,各绕环一圈。
step 1 发送ELECTION message:
当任何一个进程发现协调者不工作时,它就构造一个带有它自己进程号的ELECTION消息,发送给后继者。如果后继者崩溃,就跳过崩溃的进程,继续往下走,直到找到一个正在运行的进程。每一步,发送者都将自己的进程号加入到消息中,使自己也成为协调者的候选人。
最终消息返回到发起选举的进程。当发起者接收到包含自己号的消息,识别出这个事件,选出进程号最大的作为协调者。
step 2 发送COORDINATOR message:
第一则的消息转变为COORDINATOR,并再一次绕环运行,通知大家谁是新的协调者以及新环中的成员。消息循环一周后被删除,然后每个进程恢复正常工作。
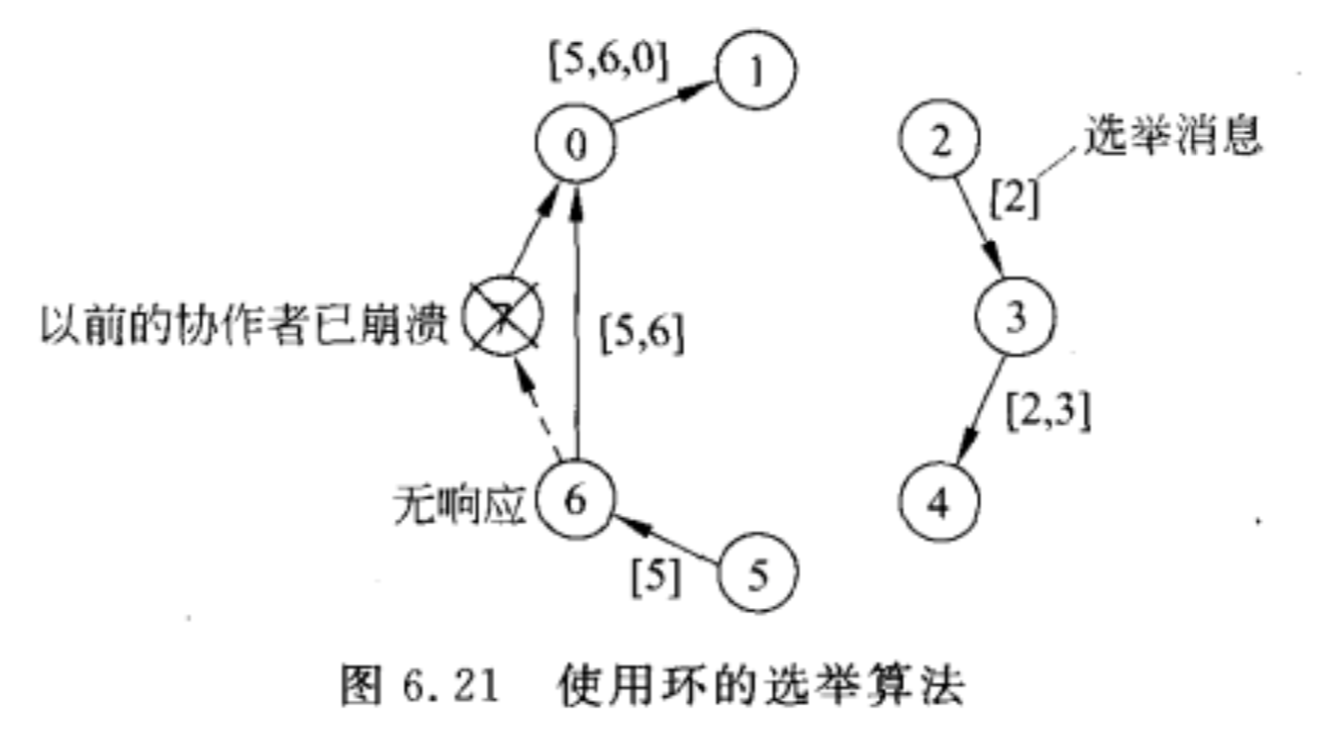
这个图是说当进程2和5同时发现协调者7崩盘了,使用环选举算法选出新的协调者。
这个图在演示Election message是怎么循环的,现在还没有4到5的箭头,是因为还没循环到那里。
无线系统下的选举算法
选定一个源节点,在网络拓扑结构中构造树形结构,源节点就是树的根结点。
例:
- 选定a是源节点;
- a向相邻结点(b和c)发生ELECTION消息;
- b和c第一次接受到ELECTION消息,认为a是他们的父结点;
- b和c再次向相邻结点发送ELECTION消息,此时g结点一定都会受到b和c的ELECTION消息,谁的消息先到谁就是g的父结点;
- 如此递给构造树形结构,直到叶节点;
- 从叶节点开始,逐层向上发送自身情况,每个非叶子节点收到子节点情况汇报后,会将子结点情况与自身情况相比较,选择出最优结点,再向上汇报。这样根结点(源节点)就知道哪个结点是最优的。从而选出这个结点是协调者。
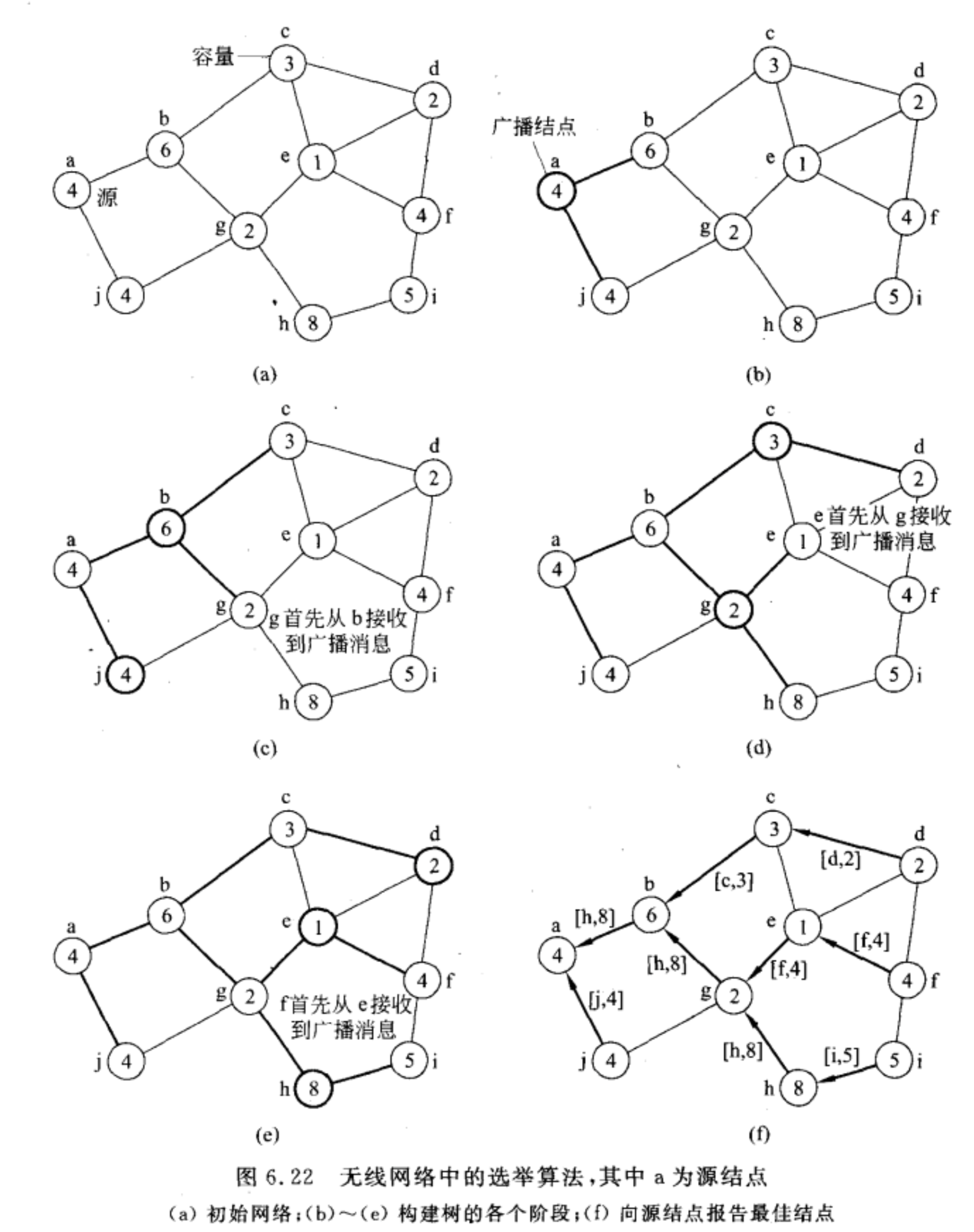
总结:
- 父结点向子节点广播ELECTION消息,直到最底层。
- 从最底层开始每个结点向父结点报告自己的容量和节点号,又父结点选择容量大的作为最佳结点,继续再向自己的父结点报告。最终到根节点选出一个容量最大的最佳结点。
Chpater 7 一致性和复制 - Consistency & Replication (第7章和第8章部分内容参考李博强同学笔记,在此感谢辛苦整理!)
概述
为什么要进行数据的复制?
进行复制是为了增强系统的可靠性和性能。
- 可靠性:更好的防止数据被破坏。
- 性能:当分布式系统需要在服务器数量和地理区域上进行扩展时,就需要复制来提高性能。
复制带来的问题 ?
一致性问题
两个术语\(W_i(x)a\)和\(R_i(x)b\)
- \(W_i(x)a\): 进程\(P_i\)把数值a写入到数据项x。
- \(R_i(x)b\): 进程\(P_i\)从数据项x读取数据后返回数值b。
严格一致性
就是写操作必须在读操作的前面执行
定义:
在一个副本上执行更新操作时,无论这一操作是在哪个副本上启动或执行的,这一更新操作都应该在后序操作发生前传播到所有副本。
从这个定义里可以发现:
隐含的假设存在绝对的全局时间。
在单处理器中(或者在有单一控制总线环境下->单一时钟)可以实现,在分布式系统中不可能实现。
例: 下图中,(a)是具有严格一致性的,(b)是没有的,因为P2出现了R(x)NIL,P1的写操作没有在P2的读操作之前传播过来。 (这根线的意思就是❌,表示这个图不满足要求)
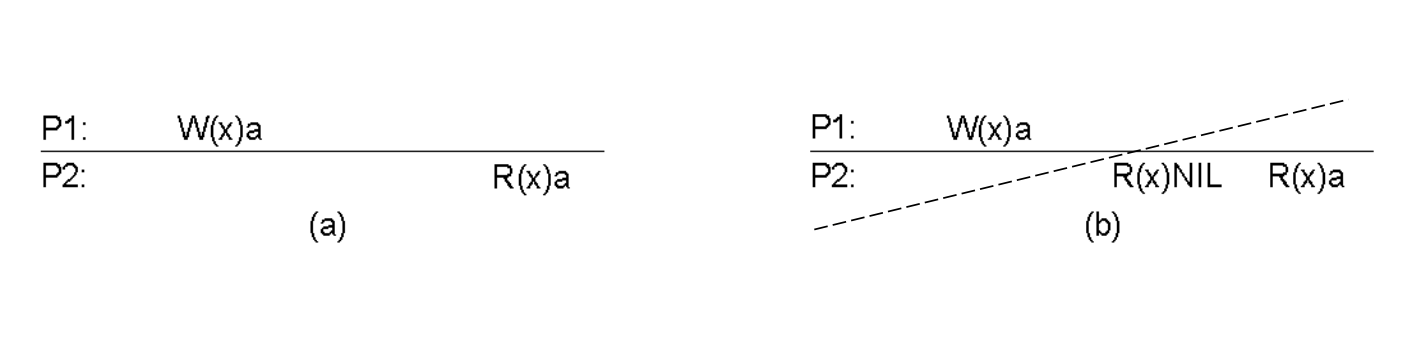
⚡️⚡️以数据为中心的一致性模型
要求知道定义,能判断!
持续一致性
这块老师大概提了一下,大概意思是什么是一致,怎么判断一致,以一个什么样的标准来判断一致。
以数据为中心的一致性模型和以客户为中心的一致性模型的区别
以数据为中心的一致性模型
不区分客户,所以叫以数据为中心的一致性模型。
- 针对所有的用户,是没有区别的。所有用户看到的都是同样的东西。对所有的用户一视同仁。
- 以数据为中心的一致性模型,从大的范围来看,都是比较严格的一致性模型。
- 成本比较高。
- 常常用在大型的数据中心中,系统一般来讲不是很大,以局域网为主。
以用户为中心的一致性模型
- 用户不同,看到的结果可能不一样。
- 以客户为中心的一致性模型,都是比较弱的一致性。
- 因为是针对某一个客户的需求来保持一致。相对来说成本比较低。
- 范围广,甚至可以在Internet上使用,相对来说是在一个广域网上,一般用在企业应用上。
后面的一系列模型,就是在对严格一致性的条件进行放松,在一个双方都可以接受的约束,认为它是一致的 (类似于睁一只眼闭一只眼)
顺序一致性
定义
数据存储满足以下条件时,称为是顺序一致的。
任何进程的执行结果都是相同的,就好像所有进程对数据存储的读、写操作是按某种序列顺序执行的,并且每个进程的操作按照程序所制定的顺序出现在这个序列中。
和严格一致不同之处
不再要求写必须在读的前面。
思想
允许由于种种因素出错,但是出的错得是一样的,所有人最后结果相同就行。
例:
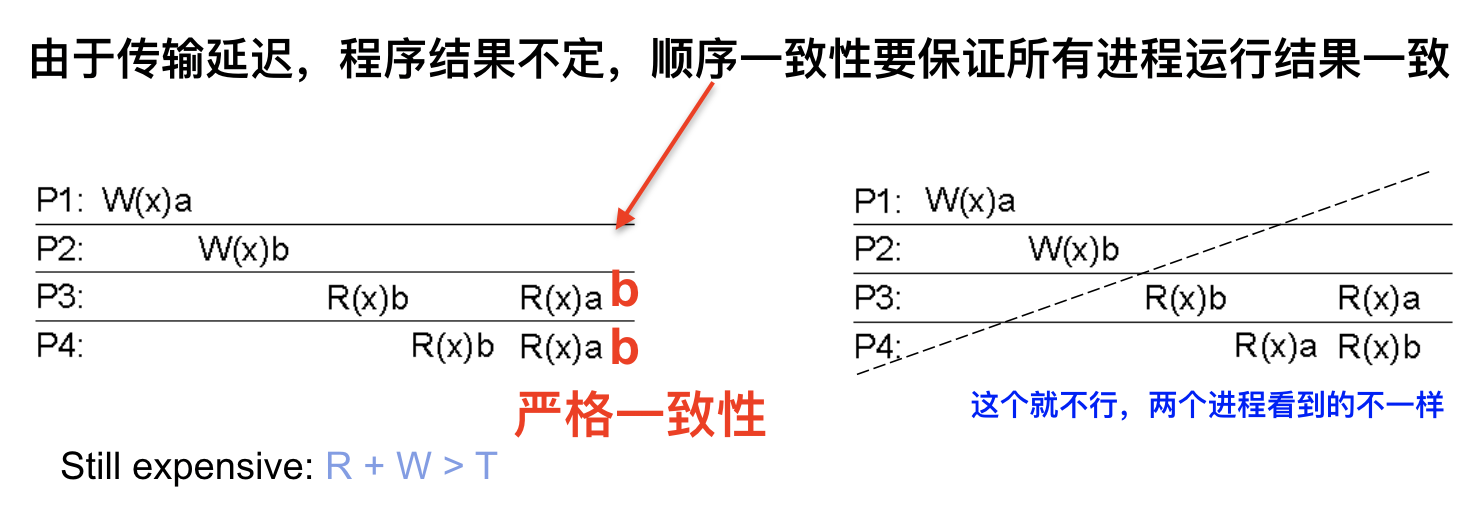
左边这个图(先不看红色的字)是满足顺序一致性的。P1的写a操作由于网络延迟等因素,在P2的写b操作之后发生,所以P3和P4都是先读到b,再读到a。如果要满足严格一致性的话(看红色字),那么在P2写b操作之后,所有进程应该只能读出b来,这才满足严格一致性。
右边的图不满足顺序一致性,P3先读到了b再读到a,P4先读到a再读到b。进程对数据存储的读写没有按某种序列顺序进行。
顺序一致性也是比较难做出来的。但是是一个强一致性,顺序一致性做到了 100%的分布式透明性。
因果一致性
基本思想
满足因果条件下,所有人必须是一致的,不满足因果条件可以不一致。
从数据的产生和消费的角度去定义因果。数据总是产生在前,消费在后。
因果性
如果事件B是由事件A引起的,或受到事件A的影响,那么因果关系必然要求其他每个人先看到事件A再看到事件B。
考虑一个分布式数据库的示例:
假设进程P1对数据项x执行了写操作。然后进程P2先读取x,然后对y执行写操作。这里,对x的读操作和对y的写操作具有潜在的因果关系,因为y的计算可能依赖于P2所读取的x的值(也即,P1写入的值)。
潜在因果关系
- 同一进程,先读再写有因果关系。很可能是读取了这个数据才能执行操作,然后写入结果。
- 不同进程,先写再读有因果关系。不同的进程间,一个把结果写进去,另一个才能够读出来。
- 两个读之间没有因果关系。
- 两个写之间没有因果关系。
- 因果关系具有传递性,e.g. If write1-> read, and read -> write2, then write1 -> write2.
定义
如果数据库是因果一致的,那么它必须服从以下条件:
所有进程必须以相同的顺序看到具有潜在因果关系的写操作。
不同进程上可以以不同的顺序看到并发的写操作。
我看到这个定义也是一脸懵逼,看几个例子就懂了。
例子1
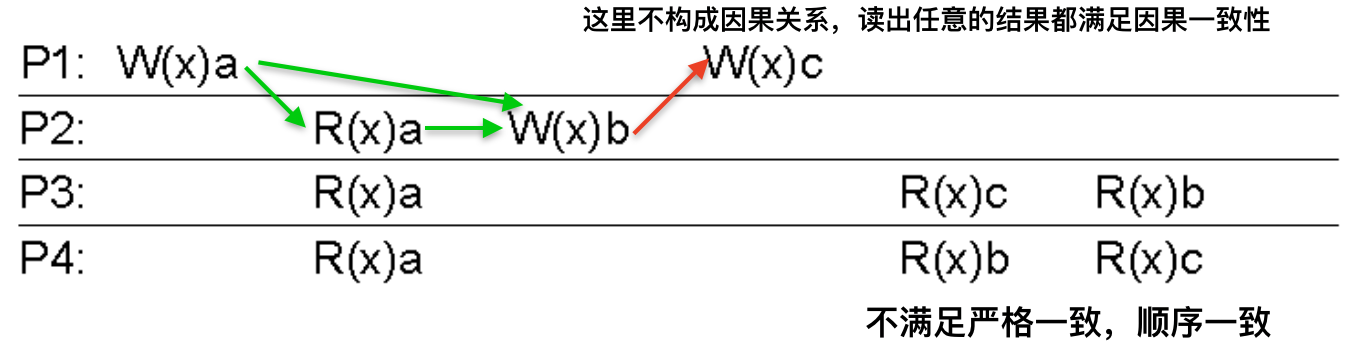
由潜在因果关系第二条,P1和P2之间,先发生\(W_1(x)a\),再发生\(R_2(x)a\),先写再读,具有潜在因果关系,所以读出来的结果必须是一致的,所有进程都必须读出a。这就是定义第一句话的意思。
由潜在因果关系第四条,两个写之间没有因果关系,所以\(W_2(x)b\)和\(W_1(x)c\)没有因果关系,那么读出什么结果都满足因果一致性,这就是定义第二句话的意思。但是这里不满足严格一致性和顺序一致性。
因果关系具有传递性,在P2内部发生了先读再写,由潜在因果关系第二条,满足因果关系,再由因果关系的传递性可知,\(W_1(x)a\)与\(W_2(x)b\)构成因果关系。图上原谅色箭头所示。
例子2:

刚刚才提到的,由因果关系的传递性可知,\(W_1(x)a\)与\(W_2(x)b\)构成因果关系,所以后面所有进程读出来的结果都必须一致,但是这里不一致,所以不满足因果一致性。

这个就满足了,因为两个并发写没有因果关系。
应用
因果一致性是首先应用在大量集群中的一致性模型。
实现方式:
- 向量时钟:使用向量时间戳捕获因果关系
分组操作
分组操作是一个弱一致性模型。实质是依靠加锁(这个锁就是同步化变量),将一些非原子操作组合为原子操作,从而实现弱一致性。
由于引入了锁的概念,分布式系统就变得不是那么透明了。
分组操作需要满足以下标准:
- 在一个进程对被保护的共享数据的所有更新操作执行完之前,不允许另一个进程执行对同步化变量的获取访问。
- 如果一个进程对某个同步化变量正进行互斥模式访问,那么其他进程就不能拥有该同步化变量,即使是非互斥模式也不行。
- 某个进程对某个同步化变量的互斥模式访问完成后,除非该变量的拥有者执行完操作,否则任何其他进程对该变量的下一个非互斥模式访问也是不允许的。
解析:
- 第一个条件表示,当一个进程获得拥有权后,这种拥有权直到所有被保护的数据都已更新为止。换句话说,对被保护数据的所有远程修改都是可见的。 (这个远程修改又是个啥???)
- 第二个条件表示,在更新一个共享数据项之前,进程必须以互斥模式进入临界区,以确保不会有其他进程试图同时更新该共享数据。
- 如果一个进程要以非互斥模式进入临界区,必须首先与该同步化变量的拥有者进行协商,确保临界区获得了访问被保护共享数据的最新副本。
我感觉上面废话了这么多,就是想说:
- 一个进程获得一个数据的控制权后,其他进程不能再获得这个数据的控制权;
- 一个进程在修改一个数据时,必须以互斥模式进入临界区;
- 进程以非互斥模式进入临界区,要先获得共享数据的最新副本。
例:入口一致性问题
入口一致性的编程问题: 正确地把数据与同步化变量相关联

- P1获得了x的同步变量,修改x一次,然后再获得y的同步变量,修改y,然后释放x的同步变量,再释放y的同步变量。
- 进程P2获得了x的同步变量,但是没有获得y,因此他可以从x读取值a,但如果读取y则为NIL,因为进程P3首先获得了y的同步变量,所以当P1释放y的同步变量时,P3可以读得值b。
Weak consistency properties
- Accesses to synchronization variables associated with a data store are sequentially consistent.
- No operation on a synchronization variable is allowed to be performed until all previous writes have been completed everywhere.
- No read or write operation on data items are allowed to be performed until all previous operations to synchronization variables have been performed.
例:

- S表示同步,由于P2,P3没有进行S操作,所以是不保证读取结果一样的。
- 对于第二个(b),P1进行了S操作,P2也在R之前进行了S操作,P2应该读取R(x)b。所以(b)这个例子是不满足弱一致性模型的。如果S在R后面,则不违反弱一致性模型。
⚡️⚡️以客户为中心的一致性模型
以客户为中心的一致性模型,底层上是更新的传播。
最终一致性/事件一致性
没有更新操作时,所有副本逐渐成为相互完全相同的副本。
最终一致性实际上只要求更新操作被保证传播到所有副本。
常用在广域网,分布式数据库上。
符号说明
\(X_i[t]\): Version of data item x at time t at local copy \(L_i\)
t时刻本地副本\(L_i\)中数据项x的版本
\(WS(x_i[t])\): all write operations at \(L_i\) since init
对\(L_i\)中的x进行一系列写操作得到\(X_i[t]\),\(WS(x_i[t])\)表示这一系列写操作的集合
\(WS(x_i[t1], x_j[t2])\): If operations in \(WS(x_i[t1])\) have also been performed at local copy \(L_j\) at a later time t2, it is known that \(WS(x_i[t1])\) is part of \(WS(x_j[t2])\)
t2时刻, \(WS(x_i[t1])\)中的操作也已经在本地副本\(L_i\)上执行完毕,表示更新传播了,记为 \(WS(x_i[t1], x_j[t2])\)
⚡️单调读
定义
If a process reads the value of a data item x, any successive read operation on x by that process will always return that same or a more recent value.
如果一个进程读取数据项x的值,那么该进程对x执行的任何后续读操作将总是得到第一次读取的那个值或更新的值。
解释
Client “sees” only same or newer version of data.
接下来的读操作要么和之前的读操作值一样,要么值比他还新。
例
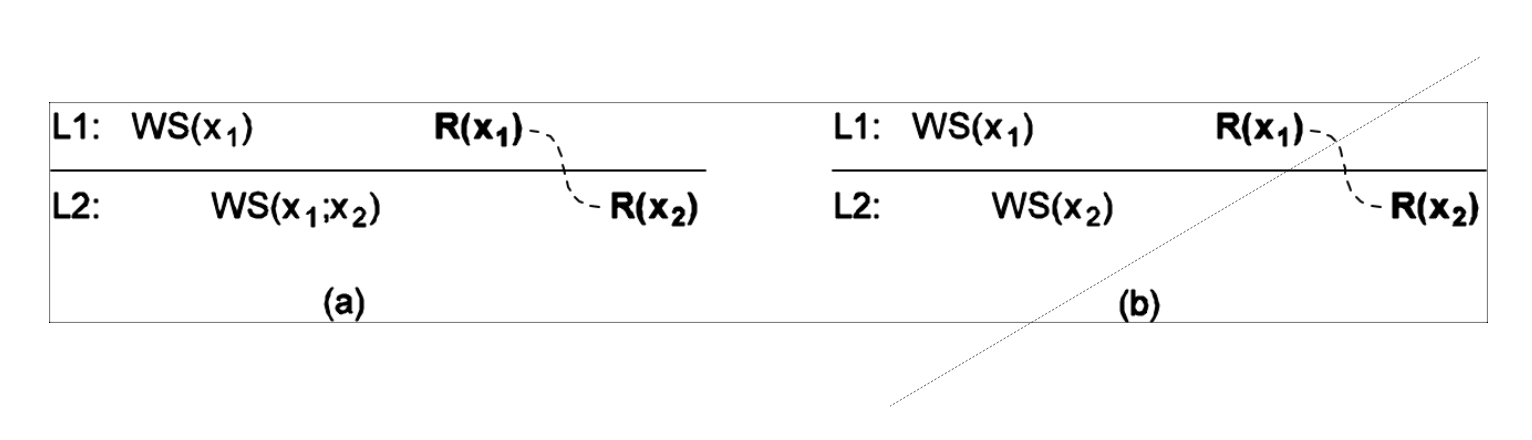
进程先在L1上对x执行了一批写操作,又在L2上再执行一批写操作。
图(a)满足单调读一致性。在执行对L2写x2的时候,会先把在L1上的写操作更新到L2的副本上,即先写入x1,再写入x2。这样,在L2读到x2时,这里面的x2是包含x1写操作的内容的。
而图(b)中就不满足了,直接对L2写x2,那么在后续读到x2的时候,只有WS(x2)的内容,不包含x1带来的内容。
⚡️单调写
定义
A write operation by a process on a data item x is completed before any successive write operation on x by the same process.
一个进程对数据项x执行的写操作必须在该进程对x执行任何后续写操作之前完成。
解释
Write happens on a copy only if it’s brought up to date with preceding write operations on same data (but possibly at different copies).
两个写操作,前面那个写操作写完,后面那个写操作才写
每个写操作完全覆盖x的当前值,但是没有必要更新副本。如果现在副本也要写,必须先完成之前的写操作。
例

图(a)中,在W(x2)之前,先把W(x1)的操作更新到L2(就是WS(x1)),满足单调写一致性。
图(b)中,b中没有WS(x1),所以不满足单调写一致性。
⚡️读写一致性 read-your-writes
定义
The effect of a write operation by a process on data item x, will always be seen by a successive read operation on x by the same process.
一个进程对数据项x执行一次写操作的结果总是会被该进程对x执行的后续读操作看见。
解释
All previous writes are always completed before any successive read.
任何读操作发生之前,应该完成全部的写操作。

进程在L1中写了一次x1,在L2中进行读操作,根据读写一致性,此时应该能把在L1中写入的x1读出来。
图(a)中,在R(x2)发生之前,有WS(x1;x2)操作,所以W(x1)在R(x2)之前被传播过来了。
图(b)中,没有把W(x1)的操作更新到L2中,所以R(x2)中没有体现x1的更新,不满足读写一致性。
⚡️写读一致性 writes-follow-reads
定义
A write operation by a process on a data item x following a previous read operation on x by the same process, is guaranteed to take place on the same or a more recent value of x that was read.
同一个进程,对数据项x执行的读操作之后的写操作,保证发生在于x读值相同或比值更新的值上。
解释
Any successive write operation on x will be performed on a copy of x that is same or more recent than the last read.
在x上所有接下来的写操作,应该是从上次读到的地方开始写,或者是比上次读到的结果还要新的地方开始写。
例
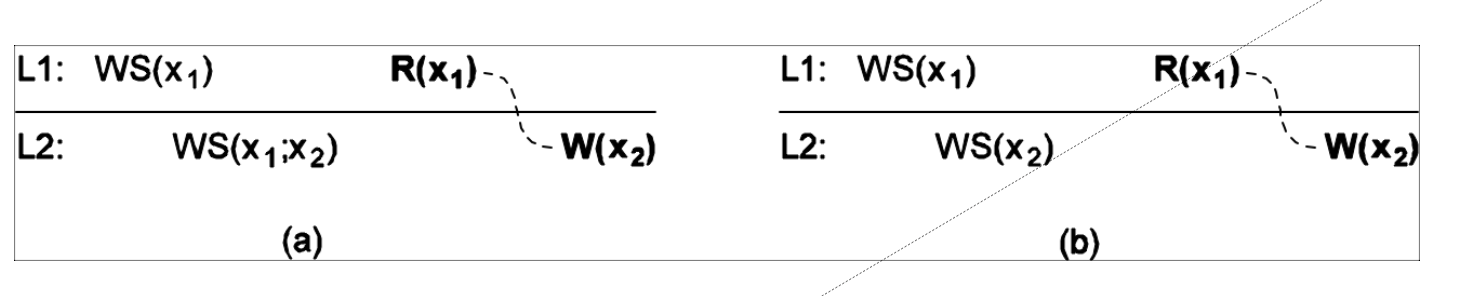
在WS(x2)的时候,要在上次发生读操作R(x1)的地方,或者更新的地方进行写操作,这样需要把WS(x1)传播到L2上。
图(a)中,有WS(x1,x2),先传播了WS(x1),再写入了x2,接下来的W(x2)就在正确的地方写入。
但是在b中没有传播WS(x1),只有WS(x2),不满足写读一致性。因为后续写操作没有发生在于先前x读取值相同或比之更新的值上。
总结
官方总结
We can avoid system-wide consistency, by concentrating on what specific clients want, instead of what should be maintained by servers. Relax consistency requirements even further.
根据客户端的需求来维护内容,进一步放宽了一致性。
个人总结
无论是单调读单调写,还是读写一致写读一致,都是先在一个地方发生写操作,如果以后其他副本发生了其他操作,而先前的写操作没有传播过来,就是不一致的,传播过来就一致。
复制管理
内容分发
一个重要的设计问题是将要实际传播哪些信息,分三种:
- 只传播更新的通知
- 把数据从一个副本传送到另一个副本
- 把更新操作传播到其他副本
拉协议与推协议
基于推式的方法又称为基于服务器的协议,不需要其他副本请求更新,这些更新就被传播到那些副本哪里。
基于拉式的方法,一台服务器或客户请求其他服务器向他发送该服务器此时持有的任何更新,基于拉的协议又称为基于客户的协议
比较:
| Issue | Push-based | Pull-based |
|---|---|---|
| State of server | List of client replicas and caches | None |
| Messages sent | Update (and possibly fetch update later) | Poll and update |
| Response time at client | Immediate (or fetch-update time) | Fetch-update time |

一致性协议
讲具体如何实现前面的模型。主要讲Primary-Based Protocols基于主备份的协议和Replicated-Write
Protocols复制的写协议,持续一致性(喝口水)这个不讲了。
Primary-Based Protocols 基于主备份的协议
一个集中式的协议,是主从式的架构。
远程写协议
原理图
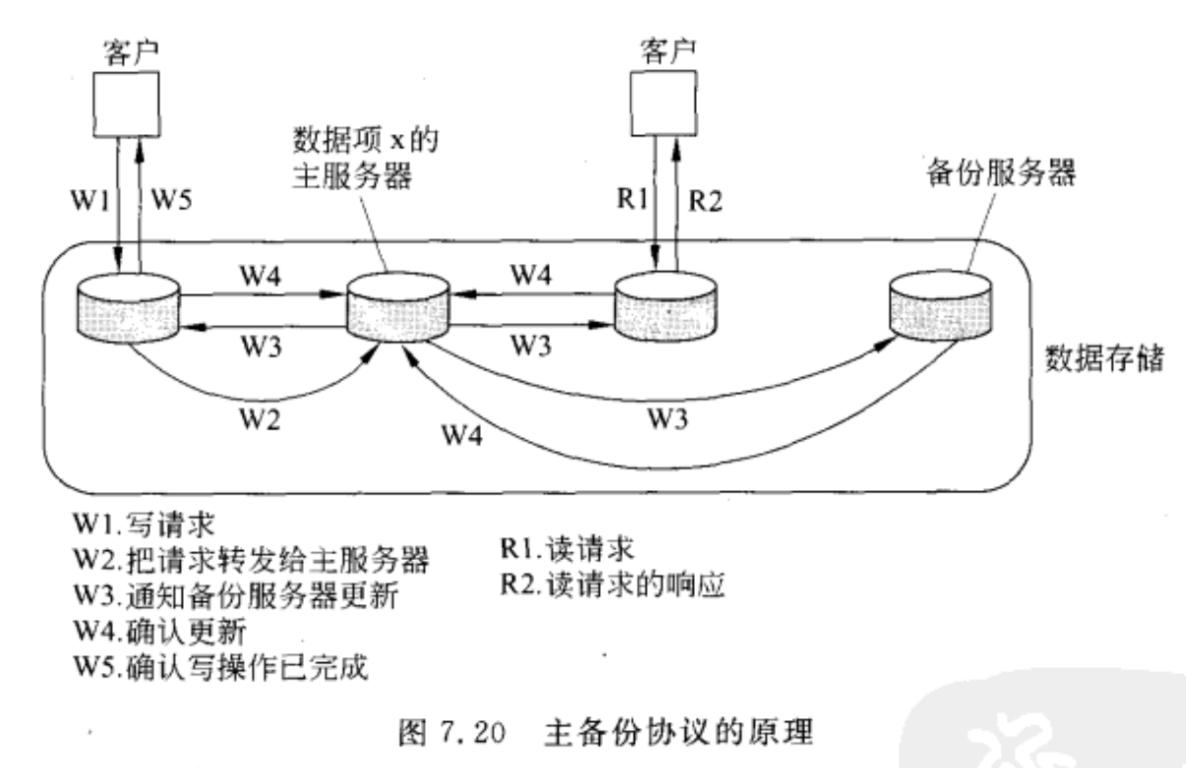
所有的更新操作全都由primary来完成。当主服务器收到W2的时候,向所有从服务器发送W3,要 对大家一起对,要错大家一起错。
这个广播的写操作具有原子性,所以又叫原子多播。
这个不是以数据为中心的一致性模型。比较符合强一致性模型的理念的。
潜在的问题
- 发送W1更新请求之后,需要经过W2,原子多播W3,等所有的W4都受到,才返回W5,这 一个过程中,启动更新的进程会被阻塞,要等待很长时间。
- 另外一种一个非阻塞的方法,就是当前已经更新了x个副本,就返回一个确认消息,然后再通知备份服务器执行这个更新。
- 牺牲了客户的时间来保证性能。
本地写协议
原理图
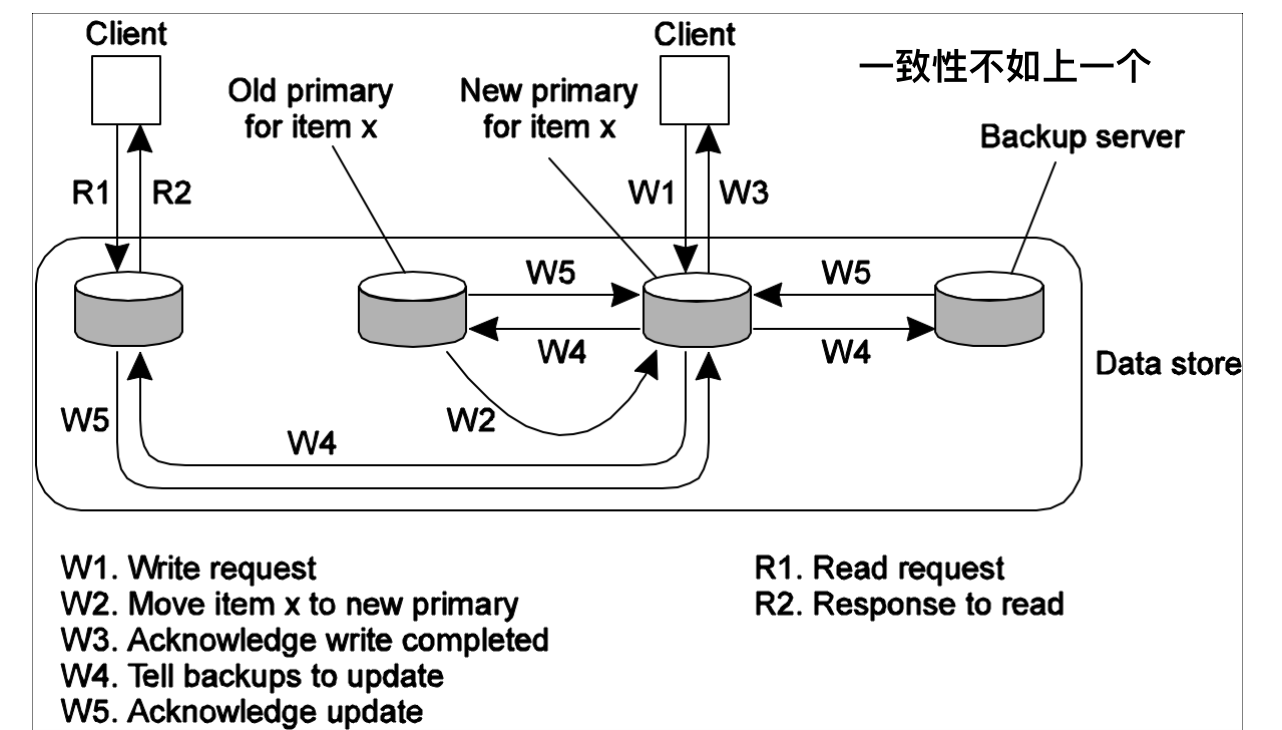
也是基于主备份的协议,当某个进程要更新数据项x是,先定位x的主副本,然后把它移动到当前访问的副本上,客户标记访问的服务器为new primary,之前的是old primary。先给客户做应答, 然后由new告诉各个备份服务器来更新、接受他们发来的更新确认。
潜在的问题
如果客户发起写请求之后,收到确认更新消息了,立即从别的备份服务器再去读,有可能读到一个错误的结果,牺牲了严格的准确性来提升性能。
Replicated-Write Protocols 复制的写协议
一种分布式的解决方案。
规定
一个服务器集群有N个机器,每个机器上都有这个文件。
若要更新这个文件,客户必须先联系至少\(\frac{N}{2}+1\)个服务器,并得到他们同意后自行更新。一旦他们更新,该文件将被修改,这个新文件也将与一个新版本号关联,该版本号用于识别文件的版本,对于所有新更新的文件,他们的版本号是相同的。
在读取的时候,有两种版本
联系至少\(\frac{N}{2}+1\)个服务器,请求他们返回该文件关联的版本号。
根据\(N_R\)和\(N_W\)来计算,\(N_W\)越大,\(N_R\)就可以越小。(在下面详细说)
一个客户要读取一个具有N个副本的文件,必须组织一个读团体(read quorum)该读团体是任意\(N_R\)个以上服务器的集合。
要求改一个文件,客户必须组织一个至少有\(N_W\)个服务器的写团体。
\(N_R\)和\(N_W\)满足以下条件
- \(N_R+N_W>N\):防止读写操作冲突
- \(N_W>N/2\):防止写写操作冲突


唉~~一声长叹,复习不易啊。
举例:
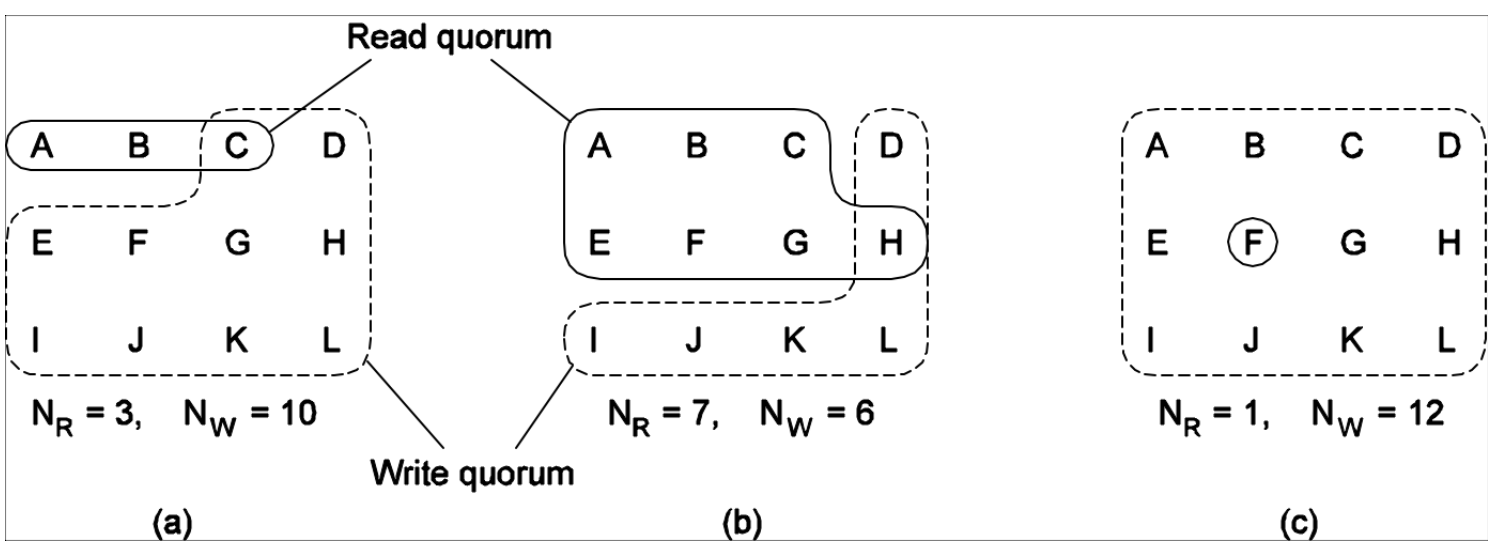
图(a)和(c)是可行的,满足上述两个条件。只要满足\(N_R+N_W>N\),那么再怎样都会读到最新版本的文件,根据文件的版本号选择最新的文件即可。
图(b)不行,因为不满足\(N_W>N/2\),如果一个进程更新{A, B, C, D, E, F},令一个进程更新{G, H, I, J, K, L},这样两边都是最新的版本号,但是文件是内容是不同的,发生写写冲突。
剩下的内容喝了口水,不讲了
Chapter 8 容错 - Fault Tolerance
"Failure is not an option. It comes bundled with your software.“
--unknown
出错是一个大概率事件。因此几乎所有的分布式系统都要考虑容错的问题。
基本概念
Fault tolerance容错
build a component in such a way that it can meet its specifications in the presence of faults (i.e., mask the presence of faults).
构建一个组件,使其能够在出现故障时满足其规范 (即掩盖故障的存在)。
可靠性dependable是一个术语,它包含了分布式系统中很多有用的需求:
可用性:被定义为系统的一个属性,他说明系统已准备好,马上可以使用
availability: Readiness for usage.
可靠性:指系统可以无故障的持续运行。
Reliability: Continuity of service delivery.
安全性:是指系统偶然出现故障的情况下能正确操作而不会造成任何灾难。
Safety: Low probability of catastrophes.
可维护性:是指发生故障的系统被恢复难易程度。
Maintainability: How easy can a failed system be repaired.
Failure:
When a component is not living up to its specifications, a failure occurs.
不满足功能说明,就是failure。
Error:
The part of a component‘s state that can lead to a failure.
一种可能会导致failure的状态
Fault:
The cause of an error.
导致error的原因。
母鸡公鸡小鸡,都是鸡,不都是鸡吗?在英文中是不同的单词。这说明西方人归纳总结的能力不行。西方人偏向推理,东方人偏向归纳总结。
——丁箐
Fault的类型
Transient: occur once and then disappear.
短暂故障:只发生一次,然后就消失了,即使重复操作也不会发生。
Intermittent: occur, then vanish, then reappear.
间歇故障:发生,消失不见,然后再次发生,如此反复进行。
Permanent: continues to exist.
持久故障:是那些知道故障组件被修复之前持续存在的故障
Failure Models
Crash failures: A component simply halts, but behaves correctly before halting.
崩溃性故障:服务器过早的停机,但是在停机之前工作正常。
Omission failures: A component fails to respond to incoming requests.
Receive omission: Fails to receive incoming messages.
Send omission: Fails to send messages.
遗漏性故障:服务器不能对请求进行响应,分为接受遗漏性故障和发送遗漏性故障。
Timing failures: The output of a component is correct, but lies outside a specified real-time interval.
E.g., performance failures: too slow.
定时故障:响应是正确的,但是在指定的时间范围之外,结果是正确的,但是时间不满足要求。
Response failures: A component’s respond is incorrect.
Value failure: The wrong value is produced.
State transition failure: Execution of the component's service brings it into a wrong state.
响应故障:服务器响应不正确,分两种,数值故障,状态转换故障。
Arbitrary (byzantine) failures: A component may produce arbitrary output and be subject to arbitrary timing failures.
随意性故障(也称为拜占庭故障):服务器可能产生任意输出并受到任意定时故障的影响,最严重的问题(没错也是Lamport提出来的)
处理容错
处理容错问题常常使用冗余来解决,例如海明码,物理冗余(多个硬件)。
⚡️⚡️拜占庭将军问题
什么是拜占庭将军问题?
高可靠的分布式系统中需要有较高的容错能力,包括处理其中一部分组件和其他组件返回的消息互相冲突的场景。这个问题可以类比于拜占庭军队围攻一个城池时,各个将军间只能通过信使通信,而将军中可能会有叛徒传递错误的消息。因此需要一种算法能够保证忠诚的将军可以互相达成一致。
假设拜占庭将军们在敌军的周围,将军之间的通信只能通过信使,每个将军根据自己观察的敌情确定下一步的军事行动。将军中可能有背叛者来阻止忠诚的将军达成一致。为了保证下一步军事行动的一致性,将军们需要
- 忠诚的将军最终的决定是一致的。(背叛者可以按照自己的意愿做决定)
- 少数的背叛者不能导致忠诚的将军做出错误的决定。
分布式系统中,没有服务器的存在,所以只能每个节点各自做决定。现在已知网络通讯是可靠的,但是存在不可靠的节点(叛徒)。
需要找到一个算法,每个服务器都使用这个算法来做决策,有叛徒存在的情况下(因为有的节点会出错),至少需要多少个节点,可以做到:
- 所有正常的结点,做出的决定是一致的;
- 出错的节点不会影响到正常的节点做决定。
我只简单写写结论,可以通过Reference的第3个链接点进去详细学习。
投票 - Voting
总结点数为n,其中有m个结点出错。
投票需要少数服从多数,所以当\(n \geq 2m + 1\) 时,能满足要求。
口头消息 - Oral Message
A给B发送一则口头消息,B仅知道这个消息是A发来的,但是不知道这个消息是A产生的,还是A从别的那里转发来的。
前提条件
Every message is delivered correctly
消息会被正确地传送。
Receiver knows who sent message
接受者知道此消息谁发的。
Absence of message can be detected
如果有人不发消息,也是可以被检测到的。
结论
当\(n \geq 3m+1\)时,能满足要求。
带签名的消息 - Sign Message
在Oral Message的前提条件里再添加两个条件:
Loyal general’s signature cannot be forged and contents cannot be altered.
忠诚的将军的签名不能被修改,对忠诚的将军的发出的消息的修改能够被检测到。
Anyone can verify authenticity of signature.
任何人都可以验证签名的真实性。
结论
当\(n \geq m+2\)时,能满足要求。
故障检测
核心思想
通过超时机制来检测某个进程是否发生了故障。
问题
无法区分是由于网络不可靠还是由于进程出现了故障导致的超时。
⚡️可靠通信
远程过程调用(RPC)中的五种失败形式
- 客户不能定位服务器
- 客户到服务器的请求消息丢失
- 服务器在收到请求之后崩溃
- 从服务器到客户的响应消息丢失
- 客户在发送请求之后崩溃
解决办法
客户不能定位服务器:
让错误抛出一个异常 Just report back to client
客户到服务器的请求消息丢失
使操作系统或客户存根在发送请求时开启一个定时器,如果定时器超时了还没有收到应答,就重发消息。(个人感觉类似于ARQ自动请求重发) Just resend message (and use messageID to uniquely identify messages) 只需重新发送消息(并使用messageID唯一标识消息)
服务器在收到请求之后崩溃
非常麻烦,有三种情况:
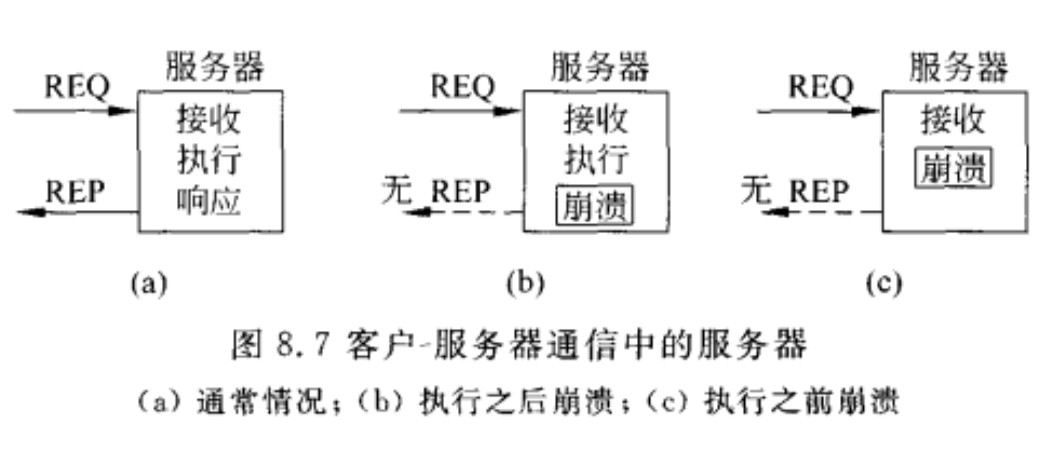
对服务器的期望:
- 至少一次语义:在服务器重启之前(或者重新绑定到一个新的服务器之前)等待并再次尝试操作。 At-least-once-semantics: The server guarantees it will carry out an operation at least once, no matter what.
- 最多一次语义:立即放弃并报告失败。 At-most-once-semantics: The server guarantees it will carry out an operation at most once, but possibly none at all.
客户可采取的4种策略:
- 不重发
- 总是重发
- 没有接收到第一次请求已经传送到服务器的确认时才重发
- 只有接受到服务器发送的请求确认时才重发
从服务器到客户的响应消息丢失
按幂等的方式组织所有的请求
改进版:客户为每一个请求分配一个序列号,通过在服务器上跟踪从每个客户收到的最近序列号,
服务器可以分辨原始的请求 与重发的请求,并拒绝执行第二次发出的请求,但是服务器还是要向
客户发送响应。
⚡️客户在发送请求之后崩溃(孤儿问题)
孤儿:如果客户向服务器发送请求,请求做一些事情,但是在服务器回复之前就崩溃了,这时虽然计算是活动的,但是没有双亲等待结果,这种不需要的计算称为孤儿计算。
解决办法(4个)
孤儿消灭extermination
在客户存根发送RPC消息之前进行进行日志记录来说明要做什么。在客户端重启之后,对日志进行检查然后明确的杀死孤儿。
再生reincarnation
当客户端重启时,就向所有的机器广播一个消息说明一个新时期的开始,当这样的广播到达后,所有与那个客户有关的远程计算都被杀死。
优雅再生gentle reincarnation
当时期广播到达时,每台机器都进行检查来查看是否存在远程计算,如果有,就尝试定位他的拥有者,只有当不能找到拥有者的时候才杀死该孤儿。
到期expiration
每个RPC都被给定一个标准的时间量T来进行工作,如果到时不能结束,就必须显示的请求另外的时间量。(类似于租约)
可靠的组通信
基本的可靠多播方法
简单一提,就是保证消息不丢失。 Simple reliability: No messages lost.
无等级的反馈控制
一种类似于分层次的多播,喝了口水,不讲了。
原子多播
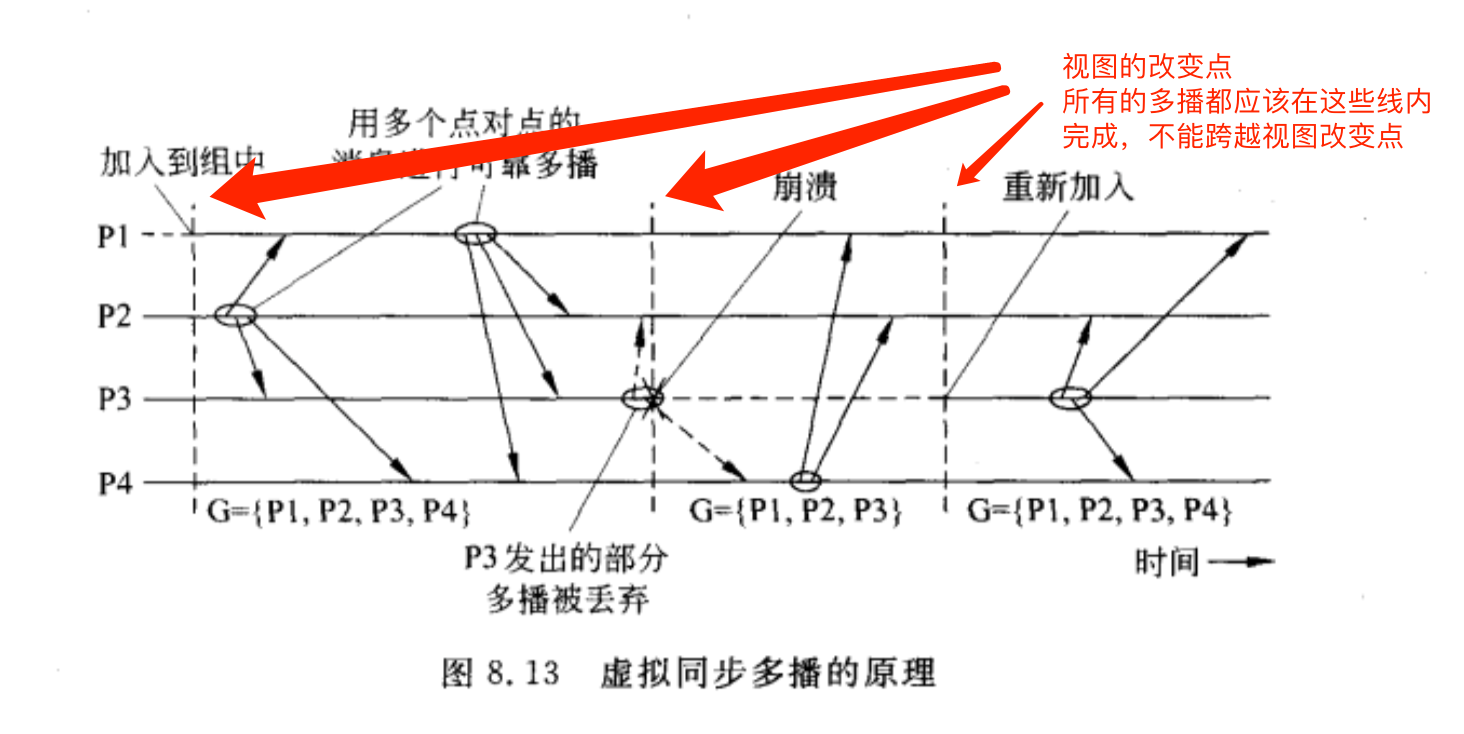
虚拟同步(virtually synchronous)问题
- 保证多播到组视图G的消息被传送给G中的每个正常进程。
- 如果消息的发送方在多播期间崩溃,那么消息要么被投递给所有的进程,要么被每个进程忽略。
所有没有坏的节点应该看到相同的信息
保证1、2两个属性的可靠多播被称为虚拟同步。
例:
P3在发送消息的时候崩溃了,在崩溃之前,它成功地将消息多播到了进程P2和P4,但是没有多播到P1。虚拟同步保证这个消息根本不会被传送。
原理
虚拟同步的原理是所有的多播都在视图改变之间进行,即,视图改变作为一个屏障,不能跨越它进行多播。
消息排序
有四种消息排序方法:
不排序的多播
是一种虚拟同步多播,它对接受不同进程发送的消息的次序不做任何保证。

P1给P2和P3发组内多播,由于没有接受消息顺序的约束,P2P3的接受顺序可能不同。
FIFO顺序的多播
通信层被强制按照消息发送的顺序传送来自同一进程的消息,对不同进程之间的顺序不作要求。

如上图,不保证m1,m3之间的关系,所以对于P2和P3,只要m1在m2之前,m3在m4之前,就满足要求。
按因果关系排序的多
传送消息可以保留不同消息之间的潜在因果关系。如果m1和m2之间有因果关系,m1应该在m2之前,那么每个接收方在接受并向上交付消息时,都应该先交付m1再交付m2。
全序多播
不论消息传送是无序,FIFO顺序还是按因果关系排序,都需要在传送消息时,对所有的组成员按照相同的次序来传送。
原子多播
提供了全序的消息传送的虚拟同步可靠性多播称为原子多播。
比较
| Multicast | Basic Message Ordering | Total-ordered Delivery? |
|---|---|---|
| Reliable multicast | None | No |
| FIFO multicast | FIFO-ordered delivery | No |
| Causal multicast | Causal-ordered delivery | No |
| Atomic multicast | None | Yes |
| FIFO atomic multicast | FIFO-ordered delivery | Yes |
| Causal atomic multicast | Causal-ordered delivery | Yes |

虚拟同步的实现
消息m在发送发完成多播之前崩溃,所以没有接收到m的进程应该从其他地方知道他丢失了消息。
稳定
如果组G中所有进程都接收到了m,则称m是稳定的。
实现原理

如图所示,进程4探测到进程7崩溃,于是它向所有进程发送view change消息。
进程6发送自身的所有不稳定消息,然后发送一个flush message。(看看别的进程有没有收到,进程6说:我认为这些消息是不稳定的,你们来看看,你再把不稳定的发给我,然后再 来分布式决策)
其余进程给进程6反馈一个flush消息,当进程6从其他每个进程那里都接受到一个flush消息时就建立了一个新的视图。
wangyu问:如何知道是不稳定的消息?
丁喝水答:根据view change消息来判断。4发送了进程7的view change消息,所以别人就知道关于7的有可能是不稳定的消息了。
分布式提交
实际上很简单,是一个事务处理的问题。麻烦在于分布式,涉及到了协作的问题。
两阶段提交
引入了协调者的概念。具体操作如下:
协作者向所有的参与者发送一个VOTE_REQUEST消息。
当参与者接收到VOTE_REQUEST消息时,就向协作者返回一个VOTE_COMMIT消息通知协作者它已经
准备好本地提交事务中属于它的部分,否则就返回一个VOTE_ABORT消息。
协作者收集来自参与者的所有选票,如果所有的参与者都表决要提交事务,那么协作者就进行提交。在
这种情况下它向所有的参与者发送一个GLOBAL_COMMIT消息。但是,如果有一个参与者表决要取消事
物,那么协作者就决定取消事务并多播一个GLOBAL_ABORT消息。
每个提交表决的参与者都等待协作者的最后反应。如果参与者接收到一个GLOBAL_COMMIT消息,那
么他就在本地提交事务,否则当接收到一个GLOBAL_ABORT消息时,就取消本地事务。
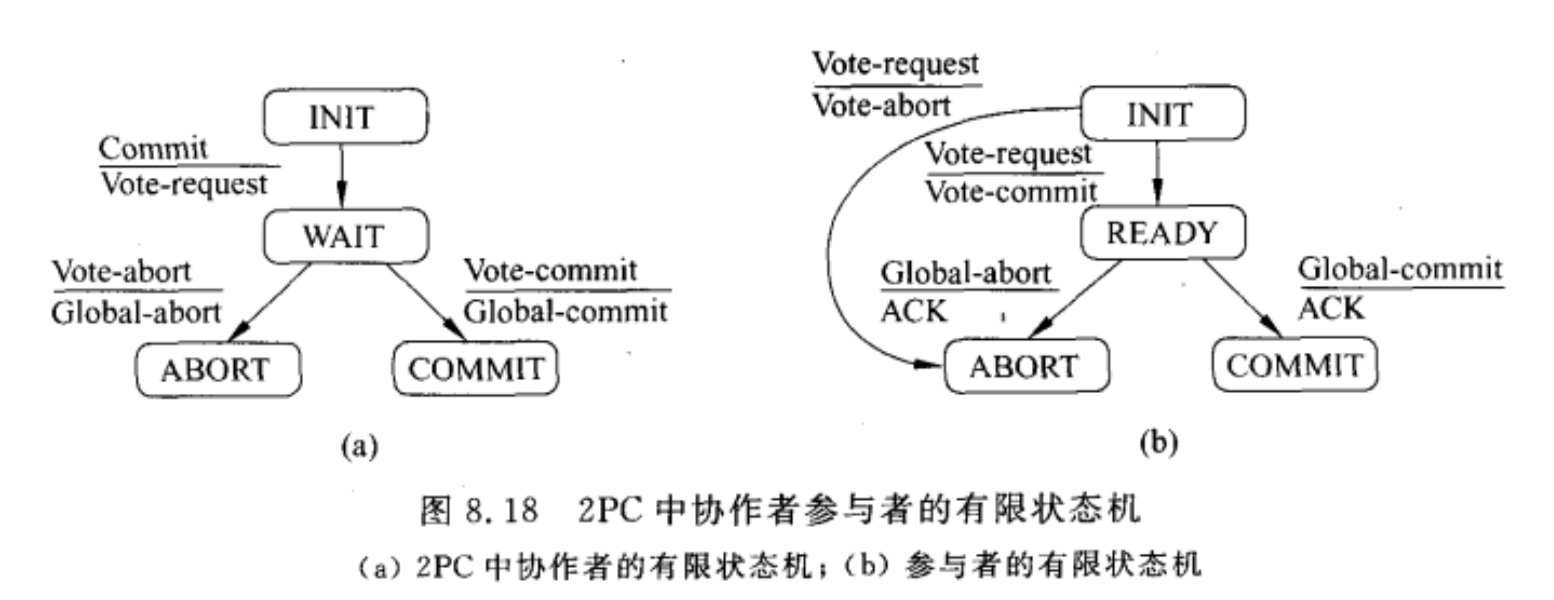
什么时候阻塞问题
- 参与者可能在INIT状态等待来自协作者的VOTE_REQUEST消息;
- 协作者可能在WAIT状态阻塞,等待来自每个参与者的表决;
- 参与者可能在READY状态阻塞,等待协作者发送的全局表决消息。
不可靠问题(简单提了一句)
- COMMIT的时候有可能失败
- 每一台机器也有可能失败
- 超时Time Out问题
三阶段提交
喝口水,不讲了
恢复
书上只是简单举了几个栗子,了解一下,我们就一起来了解一下,就不扩展太多了。
既然了解一下,那我就粘一下李博强的笔记,我也不看了。
回退回复backward recovery
将系统从当前的错误状态回到先前的正确状态。必须定时记录系统的状态(称 为设置一个还原点)
前向恢复(forward recovery)
尝试从可以继续执行的某点开始把系统带入一个正确的新状态。
检查点
Consistent Checkpoints检查点一致性问题
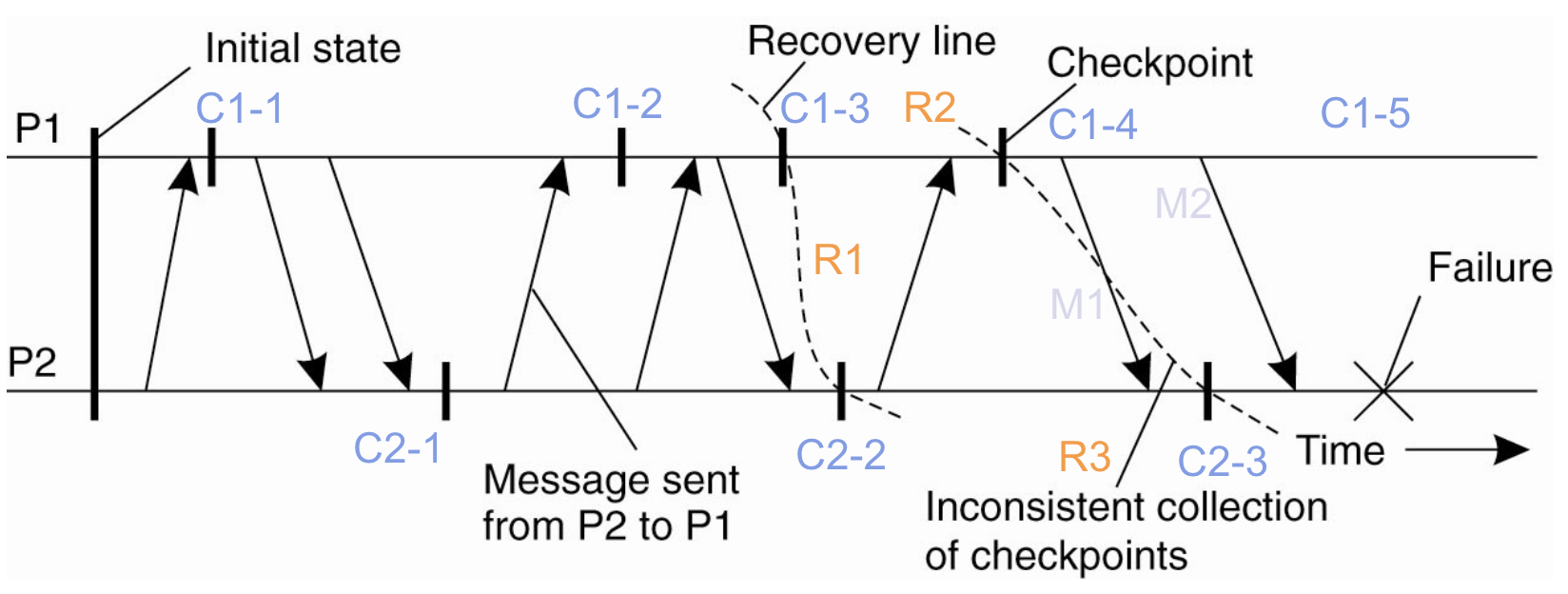
划recovery line时,当且仅当系统提供可靠通信时,同一个状态下,发送的消息必须得被接收。(在可靠通信下,P1发送了一个消息,但是P2没接收,这就会出问题,如第二条recovery line的划分)
稳定存储问题(这个我就不讲了啊,喝口水)
Message Logging消息日志
- 是检查点的另一个思路,通过日志记录来进行查错。
- 尝试在日志中记录发送的消息,然后对消息进程重放,来替代检查点check point 。
喝了一大口水,分布式部分到此结束。
云计算 - 概述
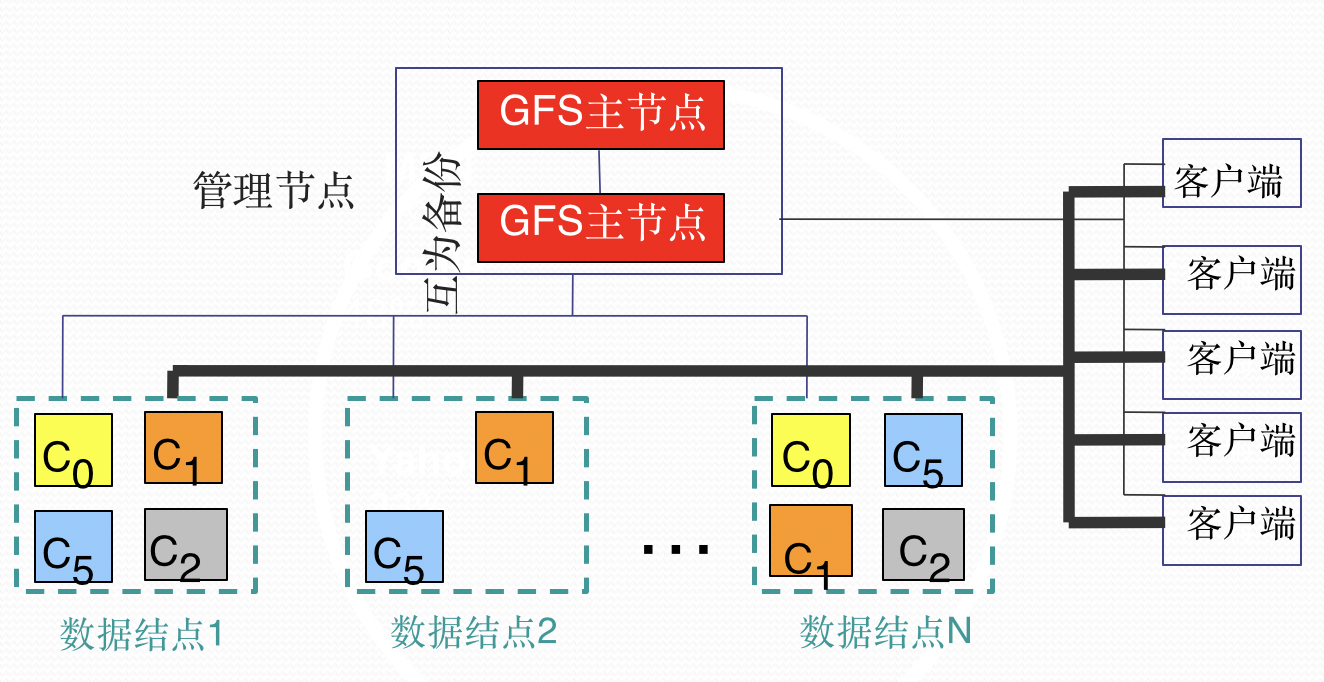
Google文件系统(GFS)
云计算技术体系结构
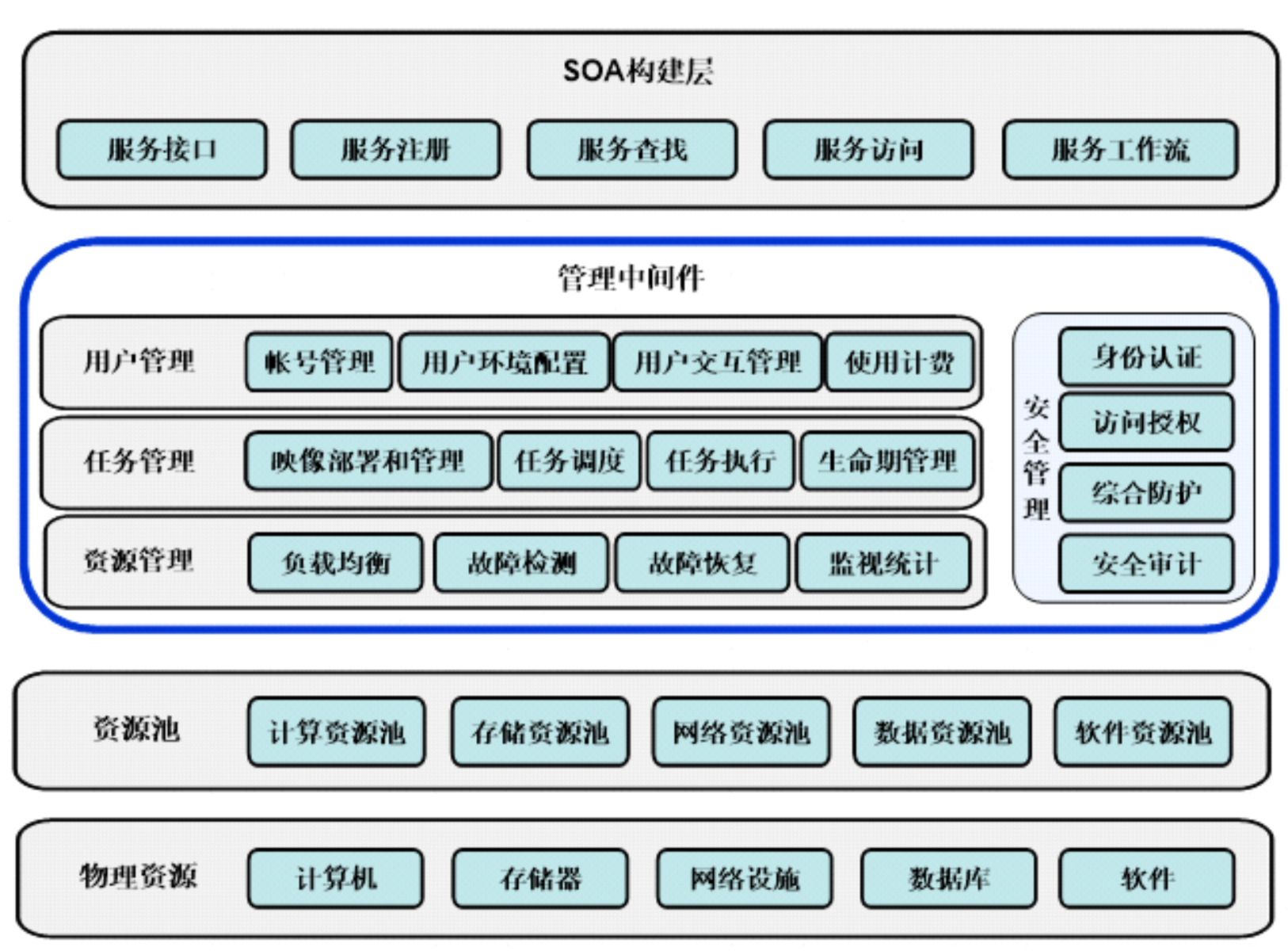
云计算技术体系结构分为四层
- 物理资源层
- 资源池层
- 管理中间件层
- SOA(Service-Oriented Architecture,面向服务的体系结构)构建层
物理资源层
包括计算机、存储器、网络设施、数据库和软件等。
资源池层
将大量相同类型的资源构成同构或接近同构的资源池,如计算资源池、数据资源池等。构建资源池更多的是物理资源的集成和管理工作,例如研究在一个标准集装箱的空间如何装下2000个服务器、解决散热和故障节点替换的问题并降低能耗。
管理中间件层
负责对云计算的资源进行管理,并对众多应用任务进行调度,使资源能够高效、安全地为应用提供服务。
SOA构建层
将云计算能力封装成标准的Web Services服务,并纳入SOA体系进行管理和使用,包括服务接口、服务注册、服务查找、服务访问和服务工作流等。管理中间件层和资源池层是云计算技术的最关键部分,SOA构建层的功能更多依靠外部设施提供。
云计算实现机制
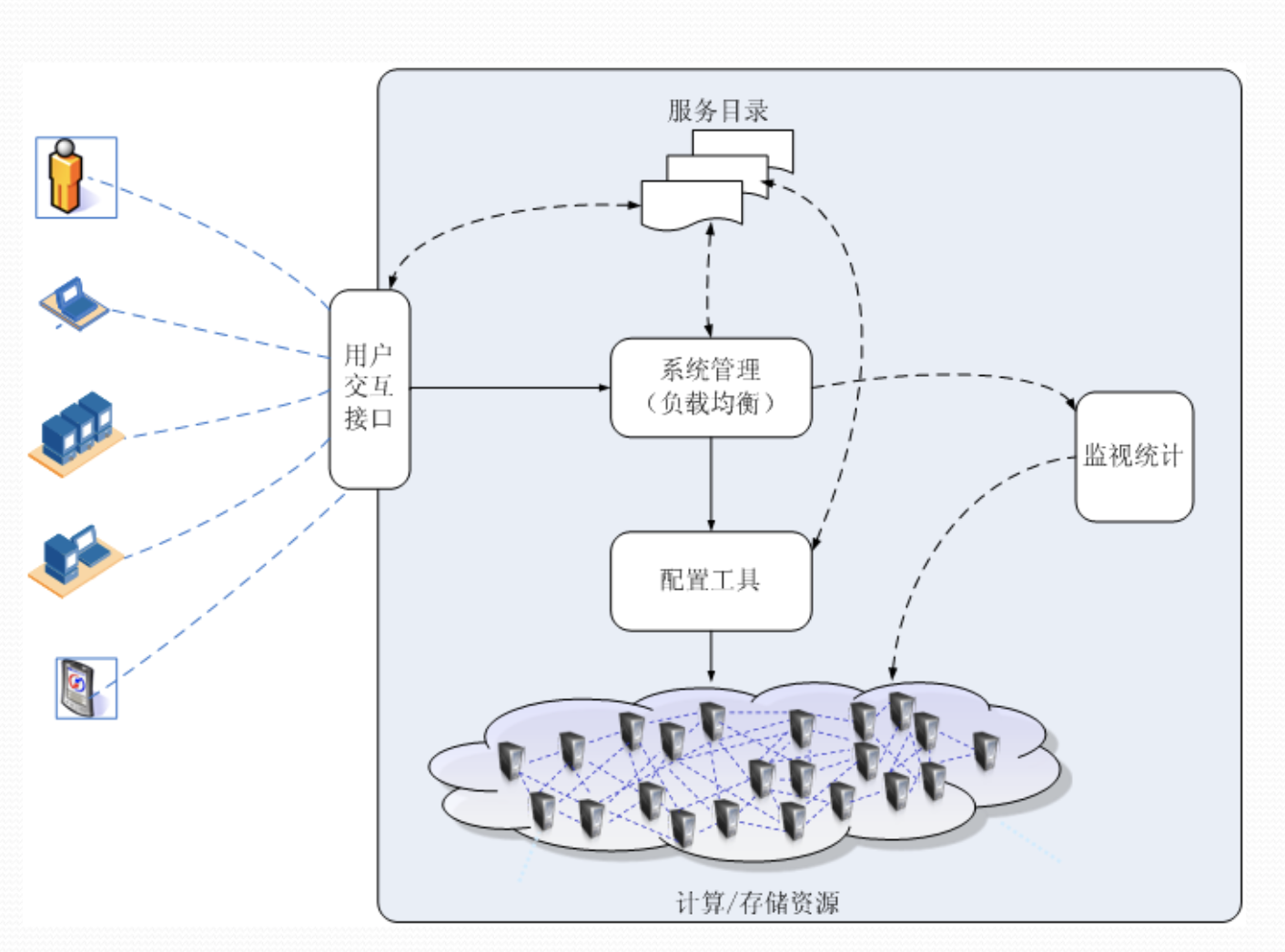
用户交互接口
向应用以Web Services方式提供访问接口,获取用户需求。
服务目录
用户可以访问的服务清单。
系统管理模块
负责管理和分配所有可用的资源,其核心是负载均衡。
配置工具
负责在分配的节点上准备任务运行环境。
监视统计模块
负责监视节点的运行状态,并完成用户使用节点情况的统计。
执行过程
用户交互接口允许用户从目录中选取并调用一个服务,该请求传递给系统管理模块后,它将为用户分配恰当的资源,然后调用配置工具为用户准备运行环境。
云计算的特点
- 超大规模
- 高可扩展性
- 虚拟化
- 按需服务
- 高可靠性
- 极其廉价
- 通用性
⚡️⚡️云计算 - GFS
网格计算与云计算
网格计算
- 在动态变化、由多个机构组成的虚拟组织中协调资源共享和求解问题
- 实现跨组织跨平台异构资源的共享
云计算
- 一种商业计算模型。
- 将计算任务分布在大量计算机构成的资源池上,使各种应用系统(用户)能够根据需要获取计算力、存储空间和信息服务。
网格计算与云计算的比较
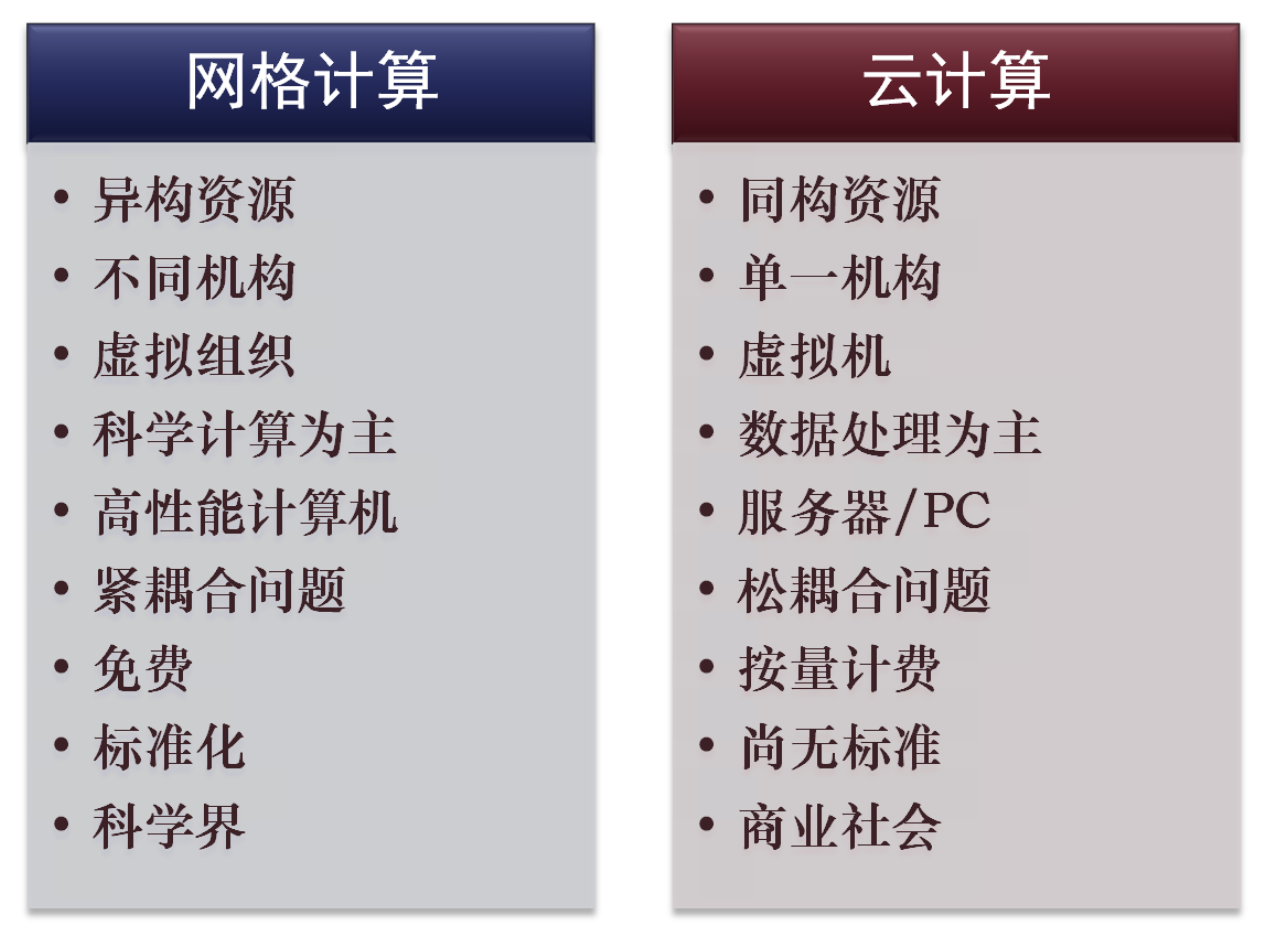
云计算的分类

云计算不是巨型机模式的简单回归
云计算的本质是分布式计算,但有集中管理某些特征优点:
更好的性能价格比;
多数应用是分布式的;
高可靠性
现代分布式系统具有高度容错机制;
可扩展性
买一台性能更高的大型机,或者再买一台性能相同的大型机的费用都比添加几台PC的费用高得多;
高度灵活性:能够兼容不同硬件厂商的产品,兼容低配置机器和外设而获得高性能计算。
Google云计算平台技术架构
文件存储
Google Distributed File System,GFS
并行数据处理
MapReduce
分布式锁
Chubby
结构化数据表
BigTable

文件系统基础
什么是文件系统?
- FAT, FAT32, NTFS, EXT, ......
- 用于持久地存储数据的系统,通常覆盖在底层的物理存储介质上,如:硬盘、CD、磁带等
数据组织的基本单元
文件
- 具有文件名(1.txt)
- 通常支持层次化嵌套(目录结构)
文件路径
- 文件与目录的结合,用于定位文件
- 绝对路径,/home/aaron/foo.txt
- 相对路径,docs/someFile.doc
规范路径
- 定位文件的最短绝对路径
- /home/aaron/foo.txt, /home/../home/aaron/./foo.txt
- 所有规范路径的集合构成了文件系统的目录结构
文件系统的存储内容
- 主要内容:用户的实际数据
- ⚡️元数据:驱动器元数据与文件元数据

文件系统设计的考虑因素
- 最小存储单元
- 较小可减少浪费空间,较大则可提高文件顺序读取速度
- 文件系统的设计目标是提高访问速度还是提高使用率?
文件系统的安全性
- 多用户环境下的文件安全
- 读/写权限分配
- 文件附带访问控制列表(ACL)
文件系统缓存
- 提高文件系统读写效率
GFS的假设与目标
硬件出错是正常而非异常
- 系统应当由大量廉价、易损的硬件组成
- 必须保持文件系统整体的可靠性
主要负载是流数据读写
- 主要用于程序处理批量数据,而非与用户的交互或随机读写
- 数据写主要是“追加写”,“插入写”非常少
需要存储大尺寸的文件
- 存储的文件尺寸可能是GB或TB量级,而且应当能支持存储成千上万的大尺寸文件
GFS的设计思路
将文件划分为若干块(Chunk)存储
- 每个块固定大小(64M)
通过冗余来提高可靠性
- 每个数据块至少在3个数据块服务器上冗余
通过单个master来协调数据访问、元数据存储
- 结构简单,容易保持元数据一致性
无缓存
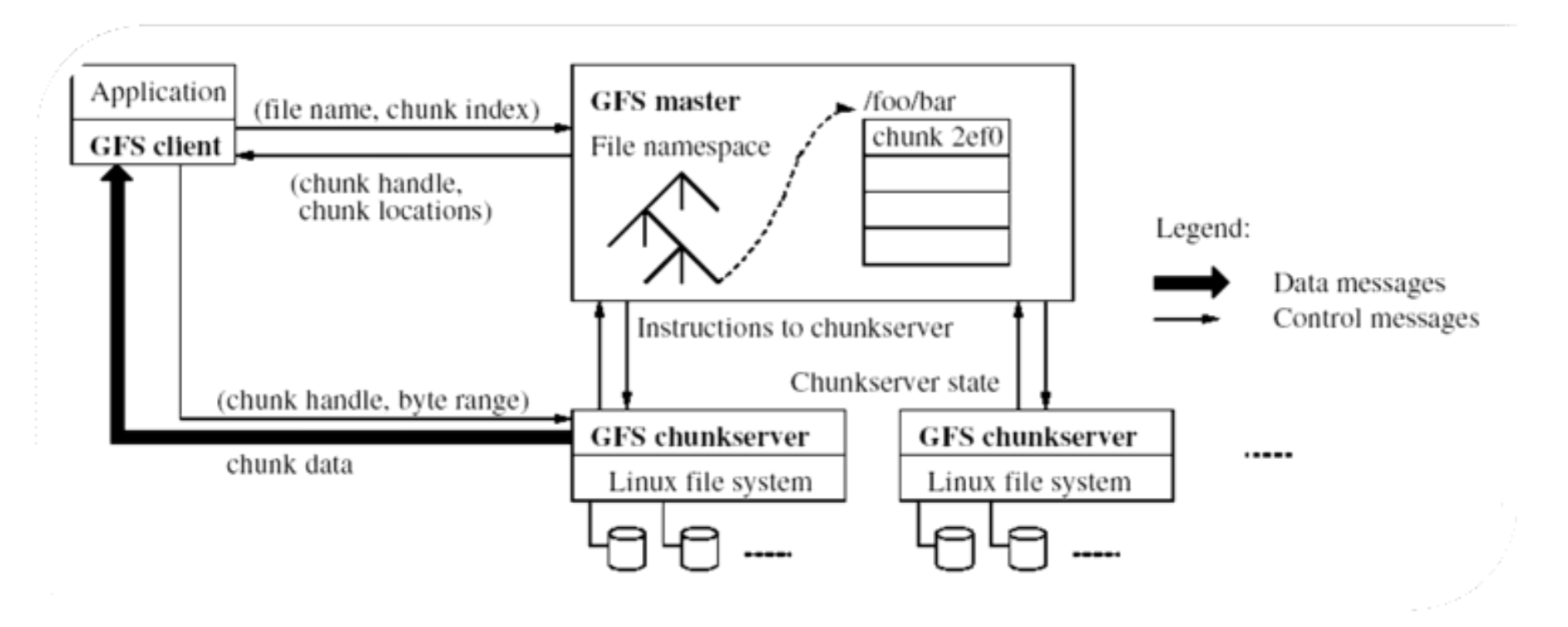
GFS架构
单一Master问题
分布式系统设计告诉我们
- 这是单点故障
- 这是性能瓶颈
单点故障问题
采用多个(如3个)影子Master节点进行热备,一旦主节点损坏,立刻选举一个新的主节点服务
真实数据放在 chunk server 上,metadata放在Master节点上。用户访问时访问的是metadata(类似于索引)。
性能瓶颈问题
尽可能减少数据存取中Master的参与程度
- 不使用Master读取数据,仅用于保存元数据。
- 客户端缓存元数据
- 采用大尺寸的数据块(64M)
- 数据修改顺序交由Primary Chunk Server完成
Master节点的任务
- 存储元数据
- 文件系统目录管理与加锁
- 与ChunkServer进行周期性通信
- 发送指令,搜集状态,跟踪数据块的完好性
- 数据块创建、复制及负载均衡
- 对ChunkServer的空间使用和访问速度进行负载均衡,平滑数据存储和访问请求的负载
- 对数据块进行复制、分散到ChunkServer上
- 一旦数据块冗余数小于最低数,就发起复制操作
- 垃圾回收
- 在日志中记录删除操作,并将文件改名隐藏
- 缓慢地回收隐藏文件
- 与传统文件删除相比更简单、更安全
- 陈旧数据块删除
- 探测陈旧的数据块,并删除
GFS架构的特点
采用中心服务器模式
- 可以方便地增加Chunk Server
- Master掌握系统内所有Chunk Server的情况,方便进行负载均衡
- 不存在元数据的一致性问题
- 不缓存数据
- GFS的文件操作大部分是流式读写,不存在大量的重复读写,使用Cache对性能提高不大
- Chunk Server上的数据存取使用本地文件系统,如果某个Chunk读取频繁,文件系统具有Cache
- 从可行性看,Cache与实际数据的一致性维护也极其复杂
- 在用户态下实现
- 直接利用Chunk Server的文件系统存取Chunk,实现简单
- 用户态应用调试较为简单,利于开发
- 用户态的GFS不会影响Chunk Server的稳定性
- 提供专用的访问接口
- 未提供标准的POSIX访问接口
- 降低GFS的实现复杂度
GFS的容错方法
Chunk Server容错机制
- 每个Chunk有多个存储副本(通常是3个),分别存储于不通的服务器上
- 每个Chunk又划分为若干Block(64KB),每个Block对应一个32bit的校验码,保证数据正确(若某个Block错误,则转移至其他Chunk副本)
Master容错(影子节点热备)
- 三类元数据:命名空间(目录结构)、Chunk与文件名的映射(写日志提供容错)以及Chunk副本的位置信息
- 前两类通过日志提供容错,Chunk副本信息存储于Chunk Server,Master出现故障时可恢复
⚡️⚡️云计算 - MapReduce
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架。MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 hadoop 集群上。
一个软件架构,是一种处理海量数据的并行编程模式
用于大规模数据集(通常大于1TB)的并行运算
MapReduce实现了Map和Reduce两个功能
- Map把一个函数应用于集合中的所有成员,然后返回一个基于这个处理的结果集
- Reduce对结果集进行分类和归纳
- Map()和 Reduce() 两个函数可能会并行运行,即使不是在同一的系统的同一时刻
为什么需要MapReduce?
- 海量数据在单机上处理因为硬件资源限制,无法胜任
- 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
- 引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理。
Google MapReduce执行流程
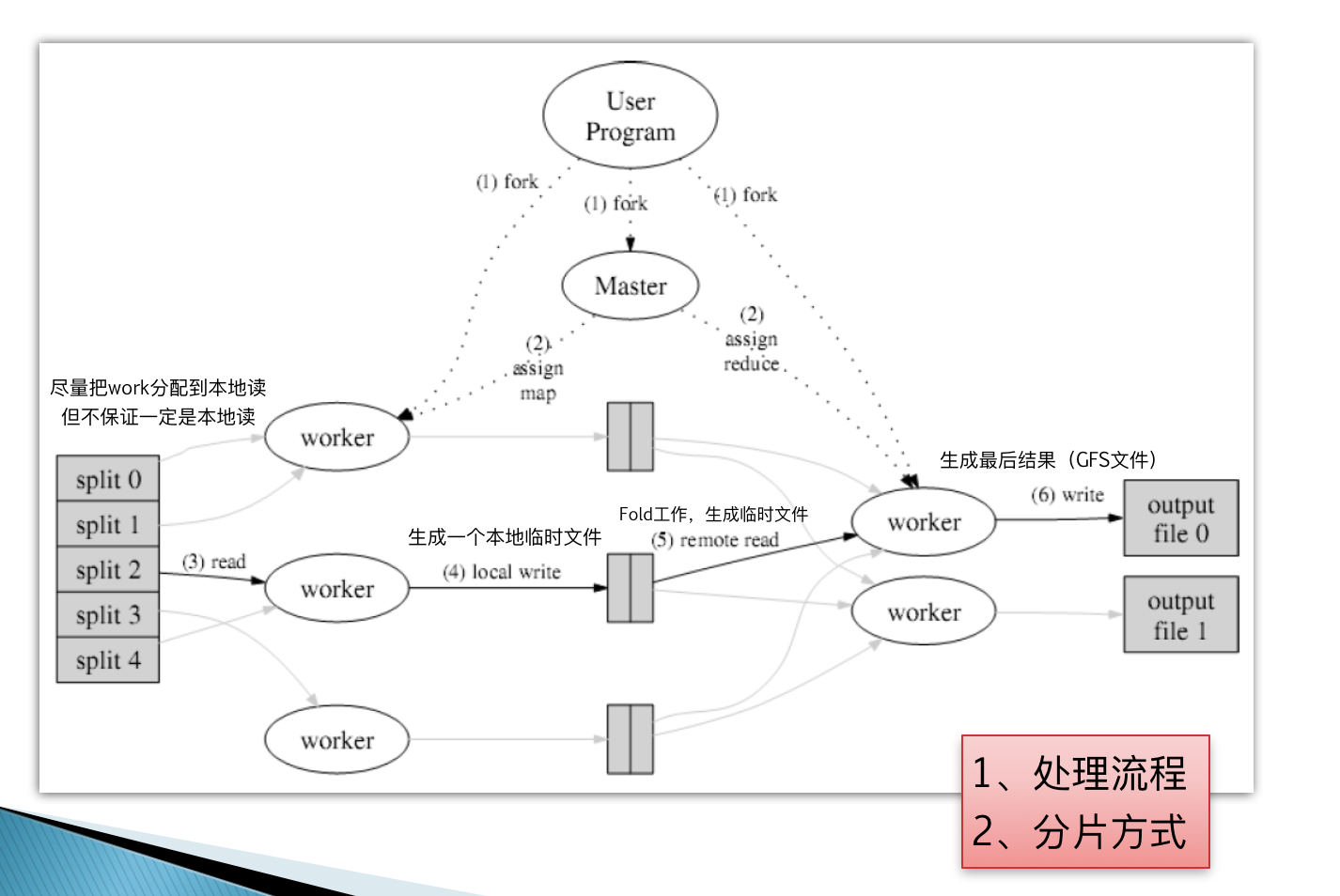
- 一个MapReduce程序启动的时候,最先启动的是 MRAppMaster, MRAppMaster 启动后根据本次 job 的描述信息,计算出需要的 maptask 实例数量,然后向集群申请机器启动相应数量的 maptask 进程
- maptask
进程启动之后,根据给定的数据切片(哪个文件的哪个偏移量范围)范围进行数据处理,主体流程为:
- 利用客户指定的 inputformat 来获取 RecordReader 读取数据,形成输入 KV 对
- 将输入 KV 对传递给客户定义的 map()方法,做逻辑运算,并将 map()方法输出的 KV 对收 集到缓存
- 将缓存中的 KV 对按照 K 分区排序后不断溢写到磁盘文件 (超过缓存内存写到磁盘临时文件,最后都写到该文件,ruduce 获取该文件后,删除 )
- MRAppMaster 监控到所有 maptask 进程任务完成之后(真实情况是,某些 maptask 进 程处理完成后,就会开始启动 reducetask 去已完成的 maptask 处 fetch 数据),会根据客户指 定的参数启动相应数量的 reducetask 进程,并告知 reducetask 进程要处理的数据范围(数据分区)
- Reducetask 进程启动之后,根据 MRAppMaster 告知的待处理数据所在位置,从若干台 maptask 运行所在机器上获取到若干个 maptask 输出结果文件,并在本地进行重新归并排序, 然后按照相同 key 的 KV 为一个组,调用客户定义的 reduce()方法进行逻辑运算,并收集运算输出的结果 KV,然后调用客户指定的 outputformat 将结果数据输出到外部存储
MapReduce的容错
Worker故障
- Master 周期性的ping每个worker。如果master在一个确定的时间段内没有收到worker返回的信息,那么它将把这个worker标记成失效
- 重新执行该节点上已经执行或尚未执行的Map任务
- 重新执行该节点上未完成的Reduce任务,已完成的不再执行
Master故障
- 定期写入检查点数据
- 从检查点恢复
MapReduce的优化
任务备份机制
慢的workers 会严重地拖延整个执行完成的时间
由于其他的任务占用了资源
磁盘损坏
解决方案: 在临近结束的时候,启动多个进程来执行尚未完成的任务
- 谁先完成,就算谁
可以十分显著地提高执行效率
本地处理
Master 调度策略:
- 向GFS询问获得输入文件blocks副本的位置信息
- Map tasks 的输入数据通常按 64MB来划分 (GFS block 大小)
- 按照blocks所在的机器或机器所在机架的范围,进行调度
效果
- 绝大部分机器从本地读取文件作为输入,节省大量带宽
跳过有问题的记录
- 一些特定的输入数据常导致Map/Reduce无法运行
- 最好的解决方法是调试或者修改
- 不一定可行~ 可能需要第三方库或源码
- 在每个worker里运行一个信号处理程序,捕获map或reduce任务崩溃时发出的信号,一旦捕获,就会向master报告,同时报告输入记录的编号信息。如果master看到一条记录有两次崩溃信息,那么就会对该记录进行标记,下次运行的时候,跳过该记录。
云计算 - Chubby
Chubby是什么?
Chubby是Google设计的提供粗粒度锁服务的一个文件系统,主要用于解决分布式一致性问题。
划重点:Chubby是一个文件系统。
粗粒度是一个什么概念?
粗粒度是指颗粒度很大,相对而言有细粒度这一概念。
两者的差异在于持有锁的时间。细粒度的锁持有时间很短,常常只有几秒甚至更少,而粗粒度的锁持有的时间可长达几天,选择粗粒度的锁可以减少频繁换锁带来的系统开销。
锁的颗粒度越大,锁住的资源越大,性能影响越大。
分布式一致性问题是个啥?
在一个分布式系统中,有一组的Process,它们需要确定一个Value。于是每个Process都提出了一个Value,一致性就是指只有其中的一个Value能够被选中作为最后确定的值,并且当这个值被选出来以后,所有的Process都需要被通知到。
Chubby的设计目标
需要实现的特性
- 高可用性
- 高可靠性
- 支持粗粒度的建议性锁服务
- 支持小规模文件直接存储
不作考虑的特性
- 高性能 使用GFS中并发读实现
- 存储能力
Chubby的系统架构
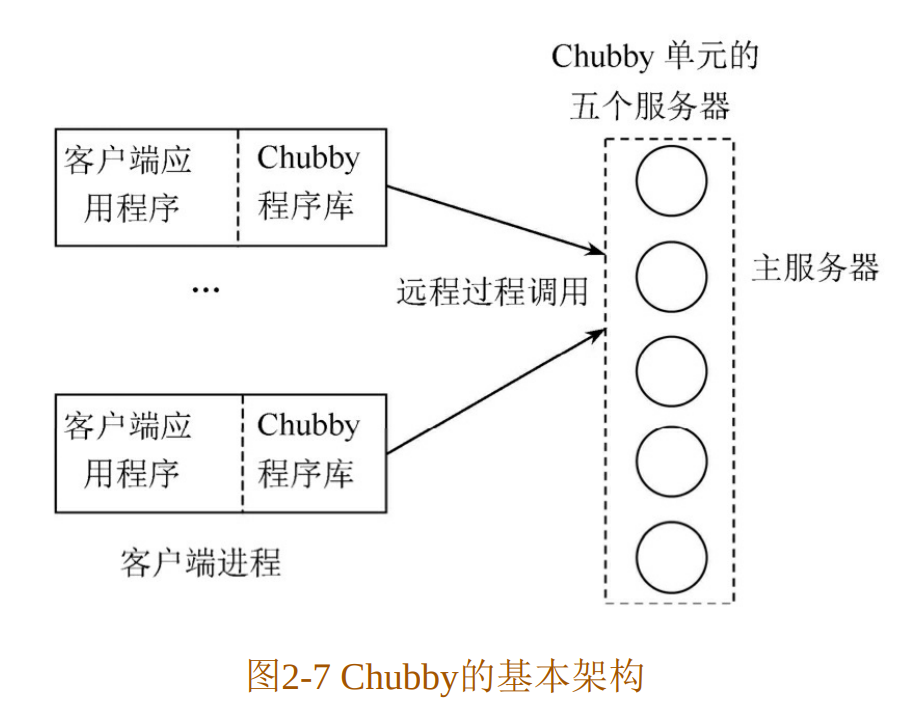
Chubby被划分成两个部分:
客户端
客户这一端每个客户应用程序都有一个Chubby程序库(Chubby Library),客户端的所有应用都是通过调用这个库中的相关函数来完成的。
服务器端
服务器一端称为Chubby单元,一般是由五个称为副本(Replica)的服务器组成的,这五个副本在配置上完全一致,并且在系统刚开始时处于对等地位。
客户端和服务器端之间通过远程过程调用(RPC)来连接。
Chubby文件系统
Chubby系统本质上就是一个分布式的、存储大量小文件的文件系统
- Chubby中的锁就是文件
- 创建文件就是进行“加锁”操作,创建文件成功的那个server其实就是抢占到了“锁”
- 用户通过打开、关闭和存取文件,获取共享锁或者独占锁;并且通过通信机制,向用户发送更新信息
Chubby客户端与服务器端的通信过程
客户端和主服务器之间的通信是通过KeepAlive握手协议来维持的。
KeepAlive是周期发送的一种信息,它主要有两方面的功能:
- 延迟租约的有效期
- 携带事件信息告诉用户更新
主要的事件包括:
- 文件内容被修改
- 子节点的增加、删除和修改
- 主服务器出错、句柄失效等。
正常情况下,通过KeepAlive握手协议租约期会得到延长,事件也会及时地通知给用户。但是由于系统有一定的失效概率,引入故障处理措施是很有必要的。
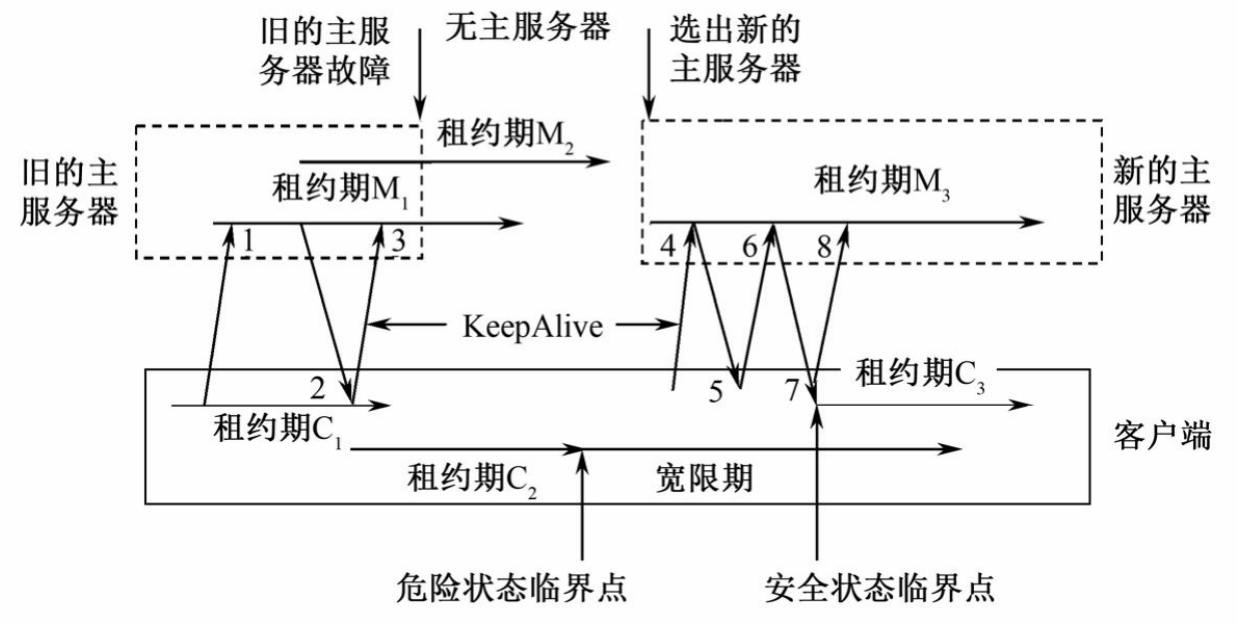
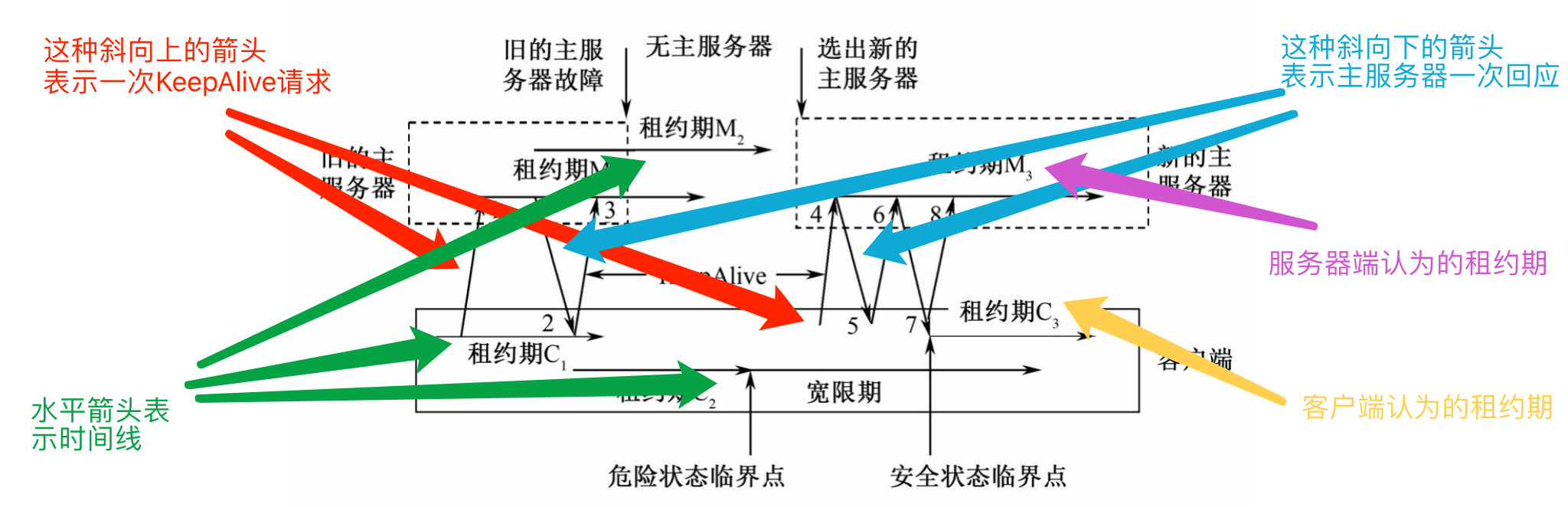
符号说明:
从左到右的水平方向表示时间在增加,斜向上的箭头表示一次KeepAlive请求,斜向下的箭头则是主服务器的一次回应。
M1、M2、M3表示不同的主服务器租约期。
C1、C2、C3则是客户端对主服务器租约期时长做出的一个估计。
图解释:
- 客户端向主服务器发出一个KeepAlive(1号消息)请求。
- 这时服务器一般不回应客户端,如果有需要通知的事件时则主服务器会立刻做出回应。
- 等到客户端的租约期C1快结束的时候才做出回应(2号消息)。并更新主服务器租约期为M2。
- 客户端在接到这个回应后认为该主服务器仍处于活跃状态,于是将租约期更新为C2并立刻发出新的KeepAlive请求(3号消息)。同样地,主服务器可能不是立刻回应而是等待C2接近结束。
- 但是在这个过程中主服务器出现故障停止使用。在等待了一段时间后C2到期,由于并没有收到主服务器的回应,系统向客户端发出一个危险(Jeopardy)事件,客户端清空并暂时停用自己的缓存,从而进入一个称为宽限期(Grace Period)的危险状态。
- 这个宽限期默认是45秒。在宽限期内,客户端不会立刻断开其与服务器端的联系,而是不断地做探询。
- 新的主服务器很快被重新选出,当它接到客户端的第一个KeepAlive请求(4号消息)时会拒绝(5号消息),因为这个请求的纪元号(Epoch Number)错误。
- 不同主服务器的纪元号不相同,客户端的每次请求都需要这个号来保证处理的请求是针对当前的主服务器。客户端在主服务器拒绝之后会使用新的纪元号来发送KeepAlive请求(6号消息)。
- 新的主服务器接受这个请求并立刻做出回应(7号消息)。如果客户端接收到这个回应的时间仍处于宽限期内,系统会恢复到安全状态,租约期更新为C3。如果在宽限期未接到主服务器的相关回应,客户端终止当前的会话。
主服务器故障
在客户端和主服务器端进行通信时可能会遇到主服务器智障,哦不,故障,上图就出现了这种情况。
正常情况下旧的主服务器出现故障后系统会很快地选举出新的主服务器,新选举的主服务器在完全运行前需要经历以下九个步骤:
- 产生一个新的纪元号以便今后客户端通信时使用,这能保证当前的主服务器不必处理针对旧的主服务器的请求。
- 只处理主服务器位置相关的信息,不处理会话相关的信息。
- 构建处理会话和锁所需的内部数据结构。
- 允许客户端发送KeepAlive请求,不处理其他会话相关的信息。
- 向每个会话发送一个故障事件,促使所有的客户端清空缓存。
- 等待直到所有的会话都收到故障事件或会话终止。
- 开始允许执行所有的操作。
- 如果客户端使用了旧的句柄则需要为其重新构建新的句柄。
- 一定时间段后(1分钟),删除没有被打开过的临时文件夹。
如果这一过程在宽限期内顺利完成,新旧主服务器的替换对于用户来说是透明的。
用户感觉到的仅仅是一个延迟。
Paxos算法(他没怎么讲,应该考不到)
Paxos算法目的
一种基于消息传递的一致性算法,用于解决分布式系统中的一致性问题。
Paxos算法思想
节点被分成了三种类型
- proposers
- acceptors
- learners
其中:
- proposers提出决议(value,实际上就是告诉系统接下来该执行哪个指令)
- acceptors批准决议
- learners获取并使用已经通过的决议
一个节点可以兼有多重类型
在这种情况下,满足以下三个条件就可以保证数据的一致性。
- 决议只有在被proposers提出后才能批准。
- 每次只批准一个决议。
- 只有决议确定被批准后learners才能获取这个决议。
acceptors对决议进行批准,采用少数服从多数原则,即大多数acceptors接受的决议将成为最终的正式决议。
云计算 - BigTable
为什么需要设计BigTable?
Google需要存储的数据种类繁多
- 网页,地图数据,邮件……
- 如何使用统一的方式存储各类数据?
海量的服务请求
- 如何快速地从海量信息中寻找需要的数据?
BigTable概述
基于GFS和Chubby的分布式存储系统
- 对数据进行结构化存储和管理
- 与GFS的联系,存到底层都是GFS
BigTable的设计动机
来源于Google的需求
- 数据存储可靠性
- 高速数据检索与读取
- 存储海量的记录(若干TB)
- 可以保存记录的多个版本
BigTable和数据库的Table可完全不一样:
- 数据库的table有外键关联,有实体之间的关系;
- BigTable没有关系这一说,是nosql,不支持关系操作。(而且云存储一般都不支持)
BigTable的逻辑视图
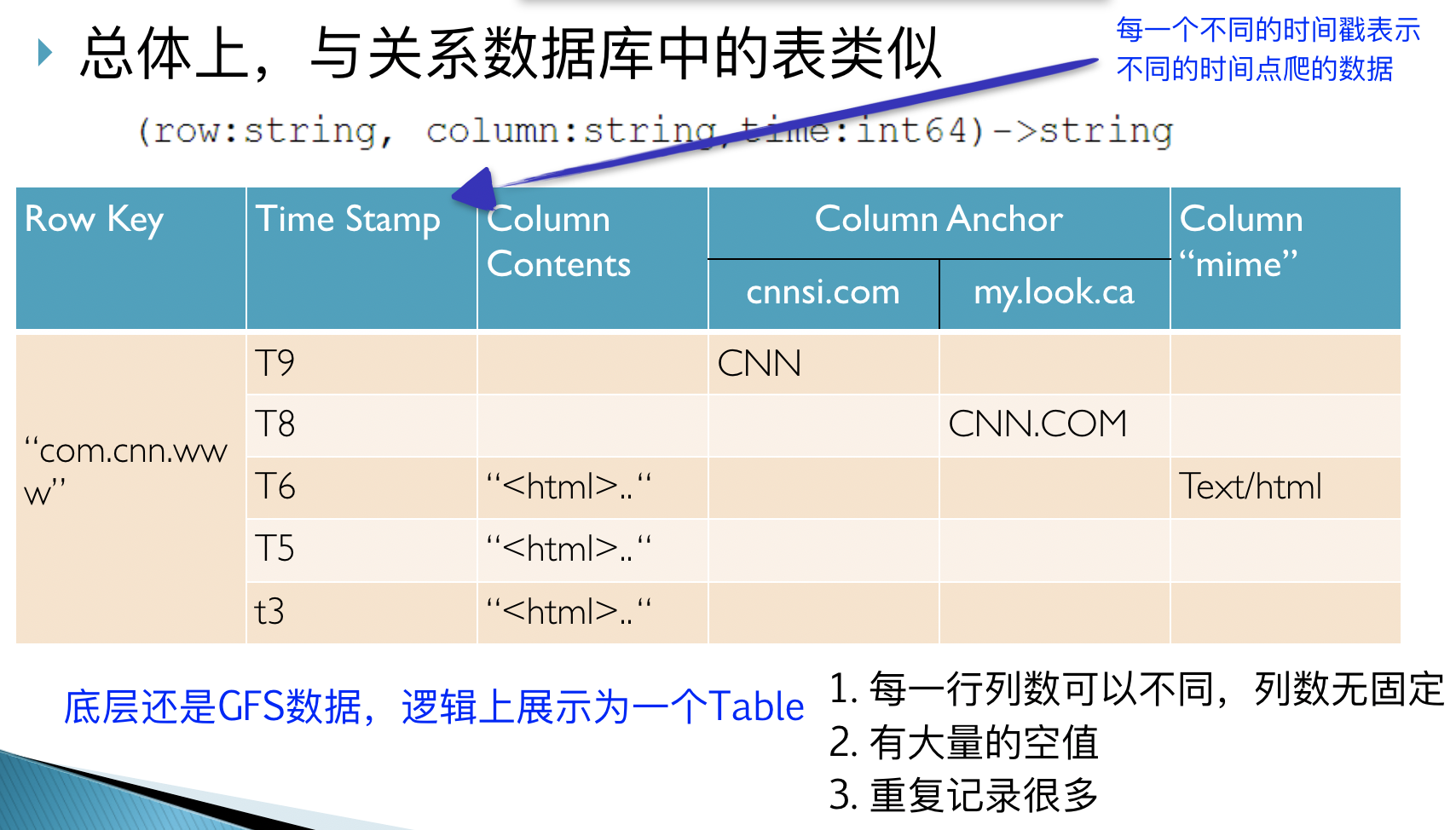
BigTable数据模型
行
每行数据有一个可排序的关键字和任意列项,即key
字符串、整数、二进制串甚至可串行化的结构都可以作为行键
表按照行键的“逐字节排序”顺序对行进行有序化处理
表内数据非常‘稀疏’,不同的行的列的数完全目可以大不相同
URL是较为常见的行键,存储时需要倒排
统一地址域的网页连续存储,便于查找、分析和压缩

列
- 特定含义的数据的集合,如图片、链接等
- 可将多个列归并为一组,称为族(family)
- 采用 族:限定词 的语法规则进行定义
- fileattr:“owning_group”, “fileattr:owning_user”, etc
- 同一个族的数据被压缩在一起保存,一个chunk指令可以读到所有数据,为了优化而设置的
- 族是必须的,是BigTable中访问控制的基本单元。
时间戳
- 保存不同时期的数据,如“网页快照”
A big table
- 表中的列可以不受限制地增长
- 表中的数据几乎可以无限地增加
无数据校验
- 每行都可存储任意数目的列
- BigTable不对列的最少数目进行约束
- 任意类型的数据均可存储
- BigTable将所有数据均看作为字符串
- 数据的有效性校验由构建于其上的应用系统完成
一致性
针对同一行的多个操作可以分组合并
- 不支持对多行进行修改的操作符
物理视图
逻辑上的“表”被划分为若干子表(Tablet)
- 每个Tablet由多个SSTable文件组成
- SSTable文件存储在GFS之上
每个子表存储了table的一部分行
- 元数据:起始行键、终止行键
- 如果子表体积超过了阈值(如200M),则进行分割
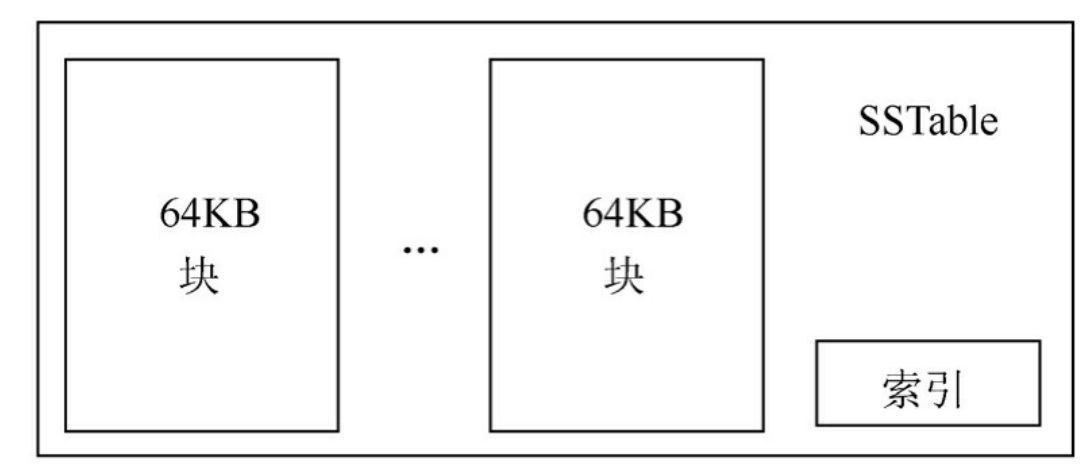
SSTable及子表基本结构
SSTable是Google为Bigtable设计的内部数据存储格式。所有的SSTable文件都存储在GFS上,用户可以通过键来查询相应的值,是SSTable格式的基本示意。
SSTable中的数据被划分成一个个的块(Block),每个块的大小是可以设置的,一般来说设置为64KB。在SSTable的结尾有一个索引(Index),这个索引保存了SSTable中块的位置信息,在SSTable打开时这个索引会被加载进内存,这样用户在查找某个块时首先在内存中查找块的位置信息,然后在硬盘上直接找到这个块,这种查找方法速度非常快。由于每个SSTable一般都不是很大,用户还可以选择将其整体加载进内存,这样查找起来会更快。
体系结构
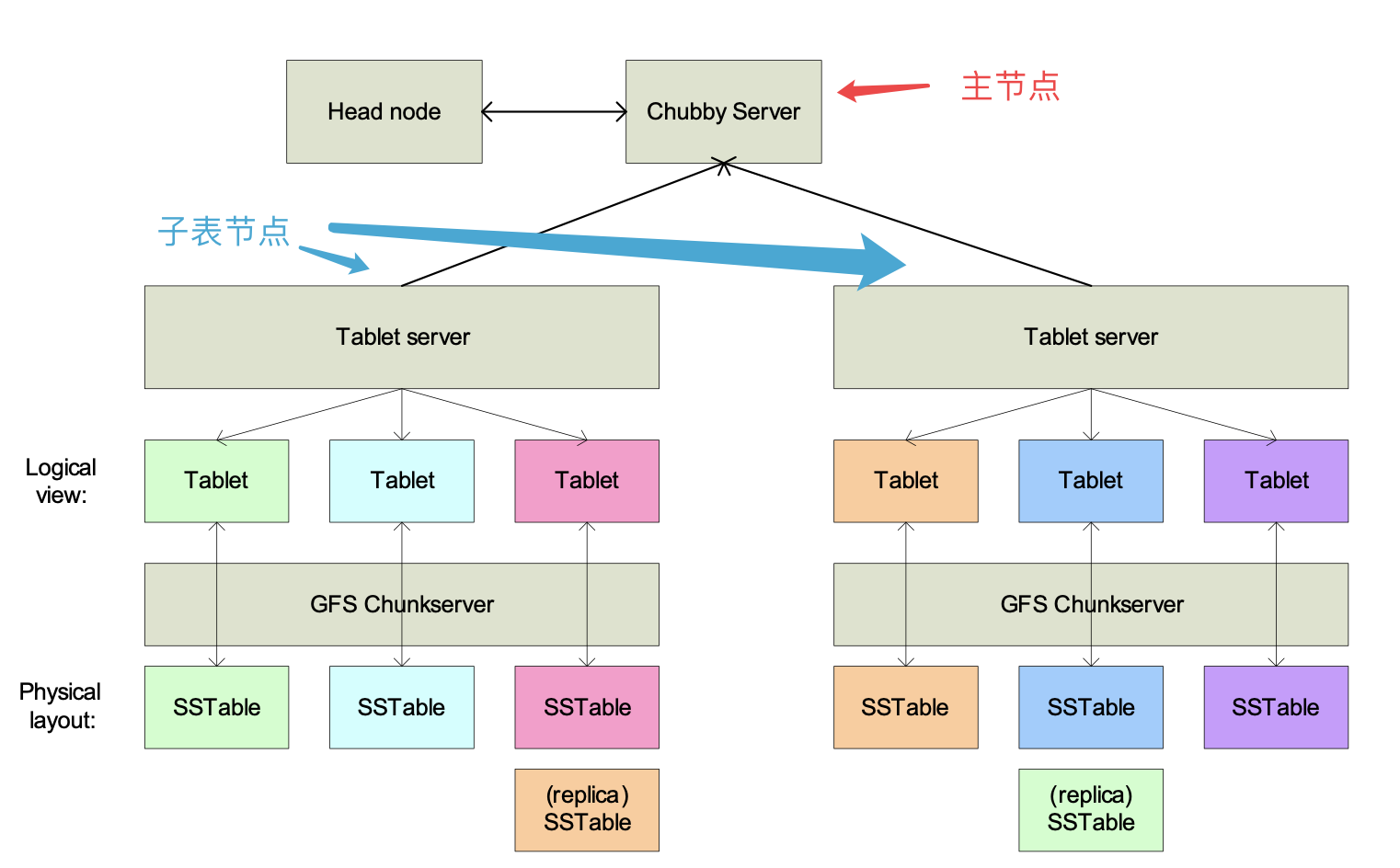
主节点的职责
- 为每个子表服务器分配子表,对外提供服务
- 与GFS垃圾回收进行交互,收回废弃的SSTable
- 探测子表服务器的故障与恢复
- 负载均衡
子表服务器故障
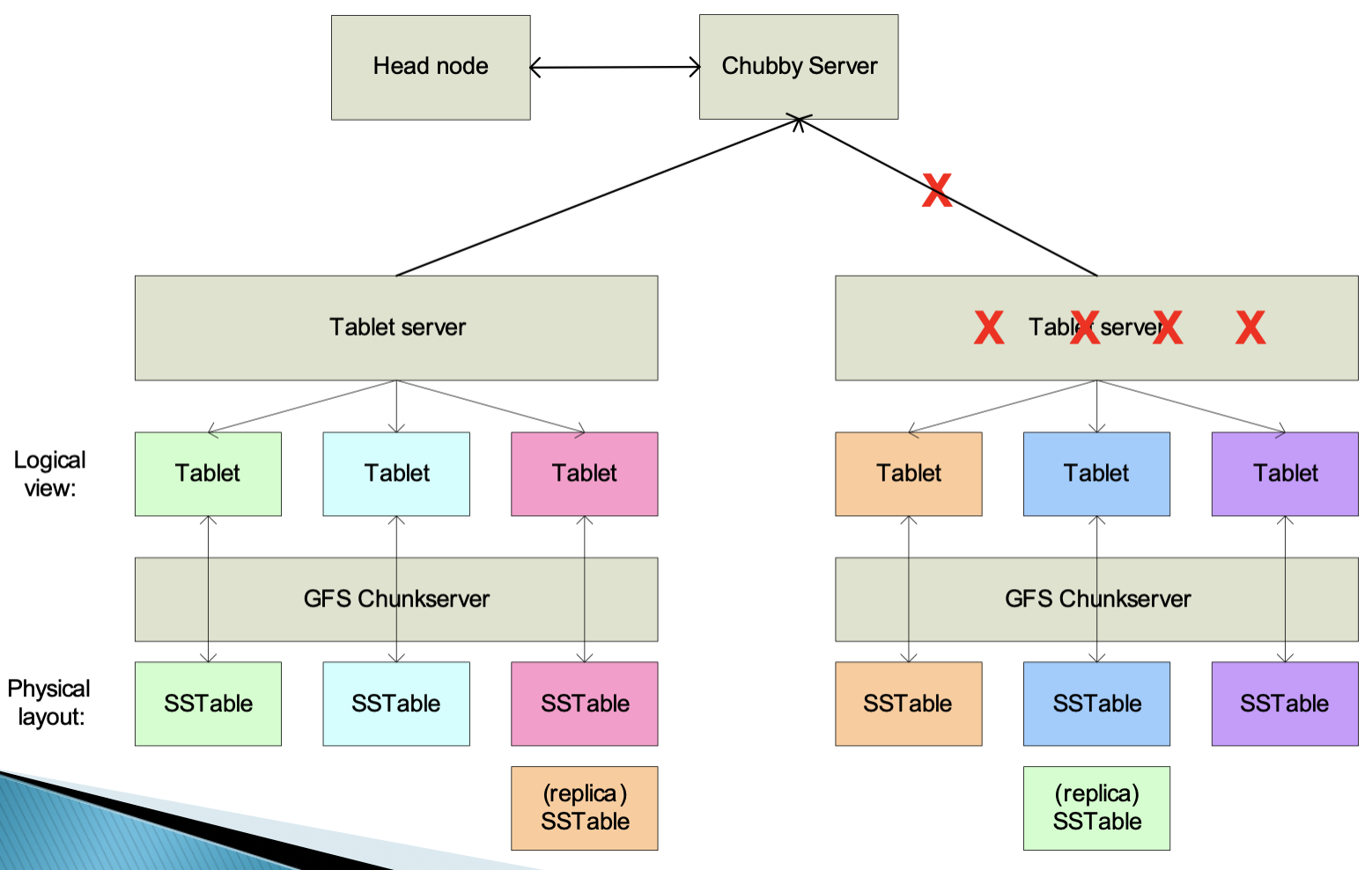
如图,右边的子表服务器出现故障,主服务器会中止这个子表服务器并将其上的子表全部移至其他子表服务器。
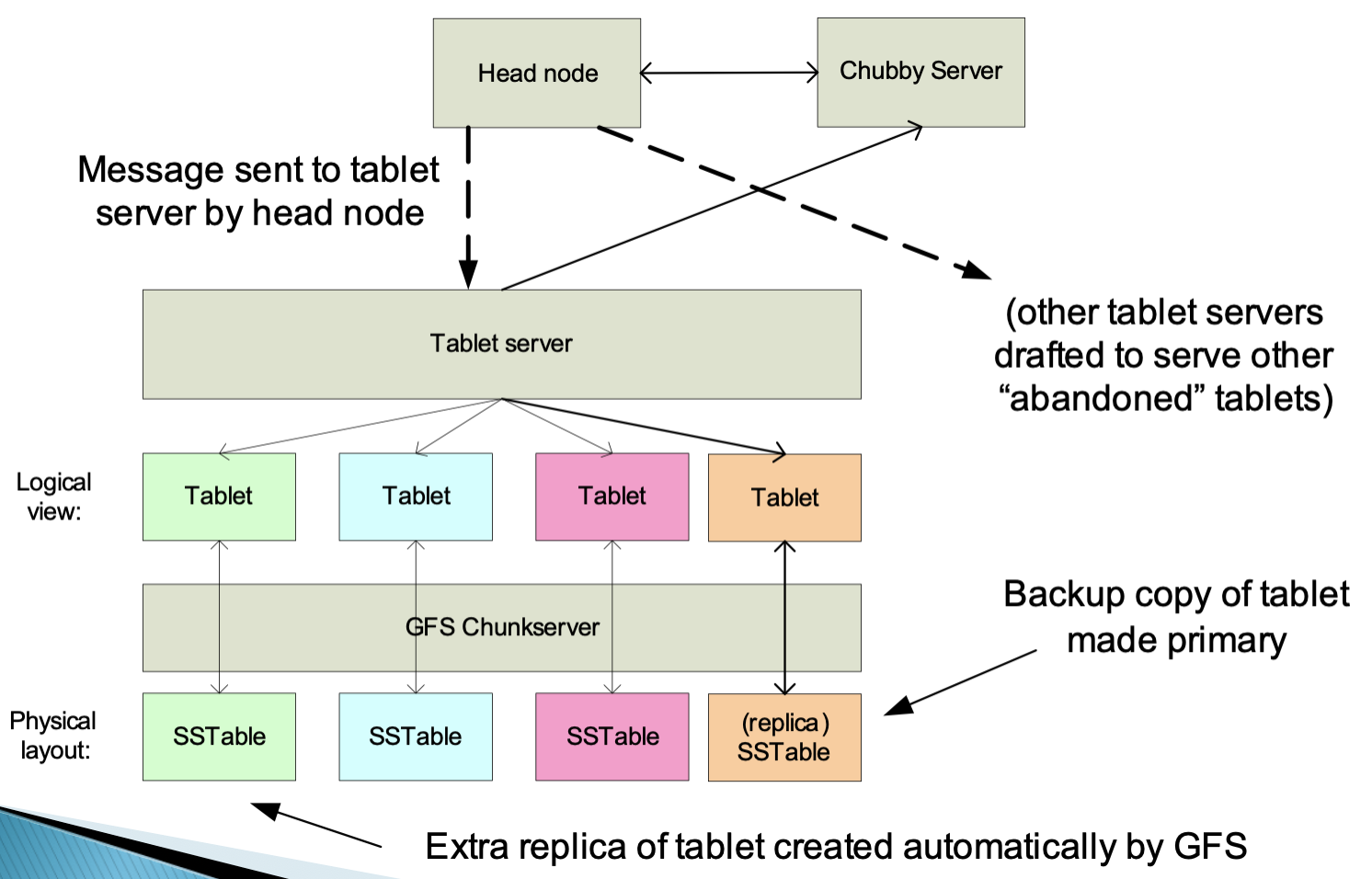
数据访问方式
子表地址的查询是经常碰到的操作。在Bigtable系统的内部采用的是一种类似B+树的三层查询体系。
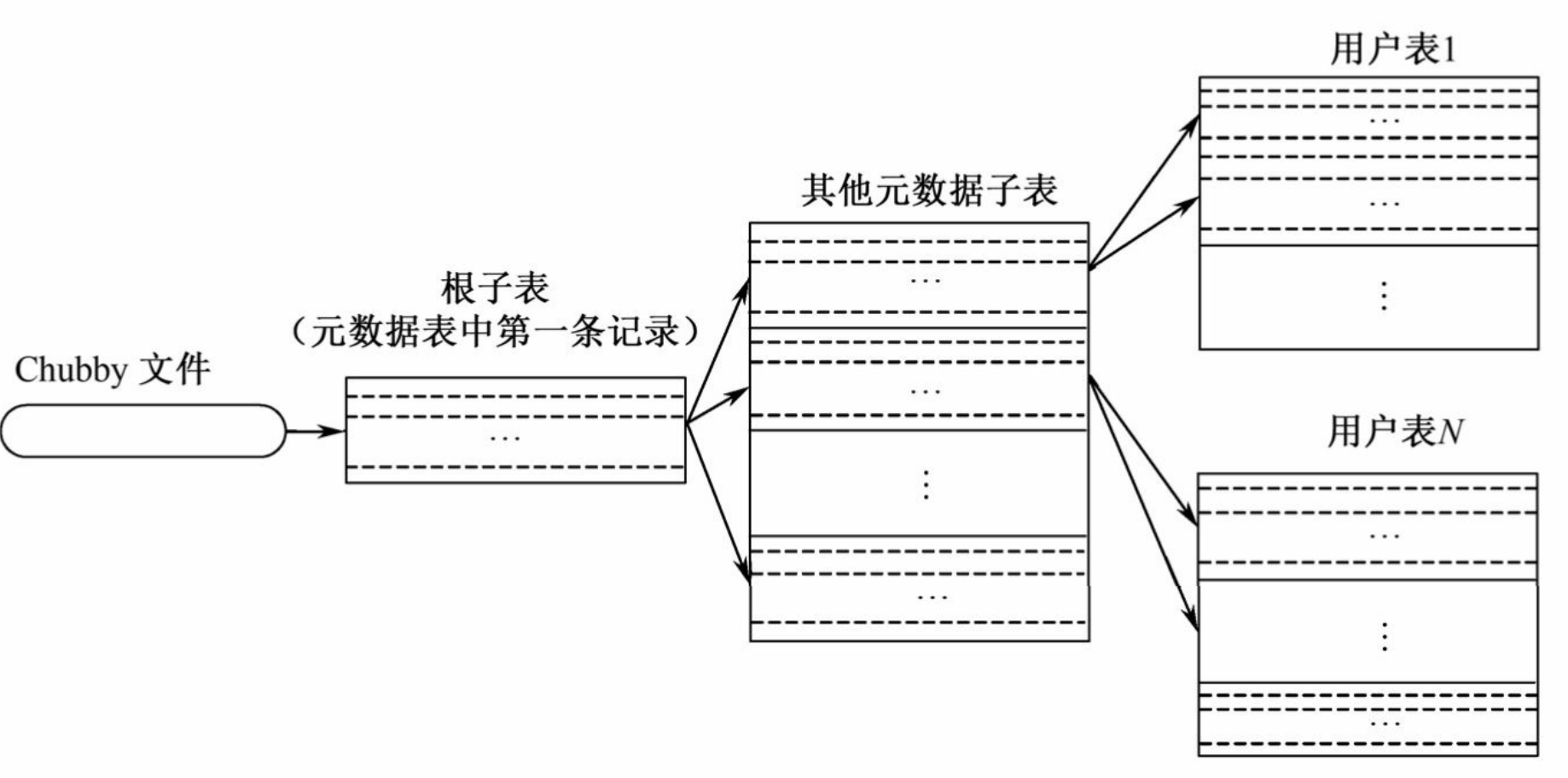
数据写的流程
任何对子表的写操作都会记录到一个存储在GFS之上的commit log中
- 每个子表服务器上所有子表变化对应于一个commit log
新的数据存储到子表服务器的内存(memtable)中
次压缩
- 旧数据存储在SSTable中,而新数据存放在memtable中
- 当memtable体积超过一定阈值,将形成SSTable,并写入GFS
- 每个tablet对应多个SSTable
子表服务器故障恢复
新的故障
- 子表服务器内存中的memtable丢失
恢复方法 用log恢复
按照tablet将该服务器对应的日志分片为每个失效tablet分配新的子表服务器新子表服务器读取对应的分段commit log,并按照日志修改tablet删除commit log中已实施的内容重新对外提供服务
性能优化
局部性群组(Locality Group)
- 根据需要,将原本不存储在一起的数据,以列族为单位存储至单独的子表
- 如用户对网站排名、语言等分析信息感兴趣,那么可以将这些列族放至单独的子表,减少无用信息读取,改善存取效率
布隆过滤器(Bloom Filter)
- 什么是布隆过滤器?判断某个元素是否隶属于集合
- 优点:误判概率低,其存储空间仅为Hash表的1/8至1/4
- 用于判断列键是否位于SSTable中,快速确定某个列键的位置
Google云计算的技术架构
Chubby的作用
- 为GFS提供锁服务,选择Master节点;记录Master的相关描述信息
- 通过独占锁记录Chunk Server的活跃情况
- 为BigTable提供锁服务,记录子表元信息(如子表文件信息、子表分配信息、子表服务器信息)
- (可能)记录MapReduce的任务信息
- 为第三方提供锁服务与文件存储
GFS的作用
- 存储BigTable的子表文件
- 为第三方应用提供大尺寸文件存储功能
- 文件读操作流程
- API与Master通信,获取文件元信息
- 根据指定的读取位置和读取长度,API发起并发操作,分别从若干ChunkServer上读取数据
- API组装所得数据,返回结果
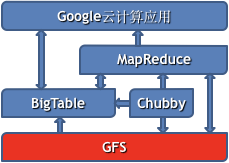
BigTable的作用
- 为Google云计算应用(或第三方应用)提供数据结构化存储功能
- 类似于数据库
- 为应用提供简单数据查询功能(不支持联合查询)
- 为MapReduce提供数据源或数据结果存储
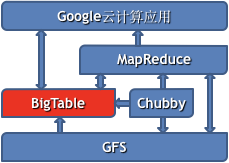
BigTable的存储与服务请求的响应
划分为子表存储,每个子表对应一个子表文件,子表文件存储于GFS之上
BigTable通过元数据组织子表
1
2
3
4Tablet 1: <startRowKey1, endRowKey1>, root\bigtable\tablet1,……
Tablet 2: <startRowKey2, endRowKey2>, root\bigtable\tablet2,……
Tablet 3: <startRowKey3, endRowKey3>, root\bigtable\tablet3,……
Tablet 4: <startRowKey4, endRowKey4>, root\bigtable\tablet4,……每个子表都被分配给一个子表服务器
一个子表服务器可同时分配多个子表
子表服务器负责对外提供服务,响应查询请求
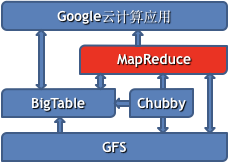
MapReduce的作用
- 对BigTable中的数据进行并行计算处理(如统计、归类等)
- 使用BigTable或GFS存储计算结果
master与slave的通信:用文件来做,永久异步通信。(一般CS是用socket来做的,属于瞬时阻塞通信)进程间协作更简单,容错性更强。下层用GFS来管理。
Reference
- http://www.chinastor.com/s/openstack/10093K202017.html
- https://blog.csdn.net/controllerha/article/details/78766840
- https://zhaohongbo.github.io/2017/02/22/Byzantine-Generals-Problem/
致谢
感谢李博强同学、汪宇同学、王诗诗同学、苏璐岩同学在此门课程上对我给予了莫大帮助!
